I spent a couple of hours today figuring out how to connect to HubSpot from Azure Synapse Analytics. Since it wasn’t straightforward for me, I decided to blog about how I did it. Hopefully, this post can help one or two others (or future me!) save some time 😊
The HubSpot Linked Service
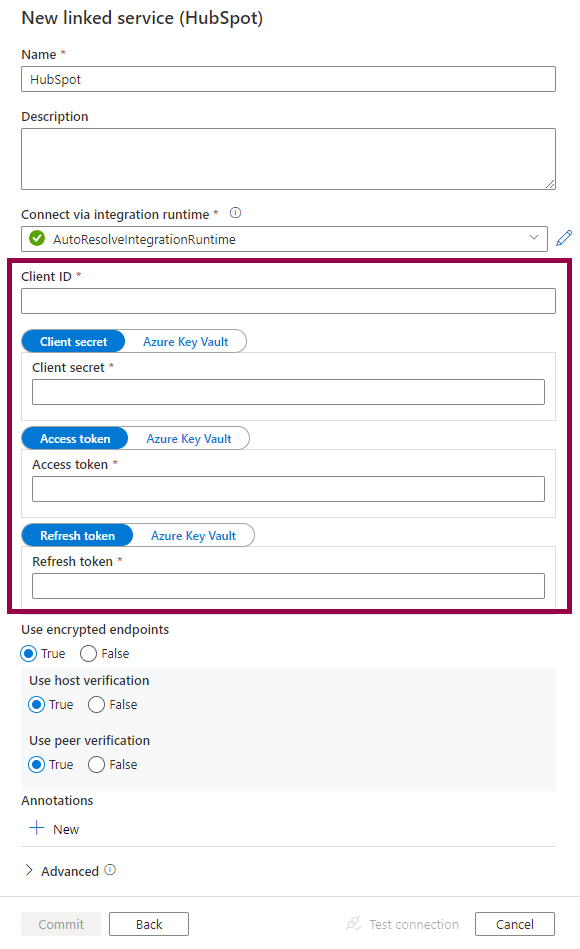
The Azure Synapse Analytics (or Azure Data Factory) linked service connects to HubSpot using a Client ID, Client Secret, Access Token, and Refresh Token:
How do we get these values from HubSpot?
The overall process is to:
- Create a private app in HubSpot to get the Client ID and Client Secret
- Authorize the private app and get authorization code
- Exchange authorization code for Access Token and Refresh Token
- Create linked service in Azure Synapse Analytics or Azure Data Factory
Let’s dig into the details! 🤓
Are you new to Azure Data Factory or Azure Synapse Analytics? Maybe you’re an expert SSIS developer wondering how to take that first step into Azure? Do you feel a little overwhelmed by all the possible ways you can move and transform data these days? Join me at the ExCeL London on Tuesday, March 8th, 2022! I will be delivering a training day at SQLBits 2022 called Beginner’s Guide to Data Integration using Azure Data Factory or Azure Synapse Analytics 🥳
My goal is to help kickstart your journey as an Azure Data Engineer, and for all of us to have a great and safe day of learning and networking. SQLBits are taking covid safety seriously by requiring proof of vaccination / tests, wearing masks, and ensuring proper spacing between seats. I will be there in-person and hope you will be able to join us too!
(Oh, and if you want to get the most out of your week at SQLBits? Check out Paul Andrew’s training day on Wednesday called Azure Data Integration Pipelines - Advanced Design and Delivery 🤓)
Today is a very special day. It’s Monday, it’s a new week, and it’s a new month - all sorts of new beginnings. The most important new beginning, however, is that today is my first day as a Senior Consultant in the Data Management and Analytics team in Skill! Yay 🥳

Skill is a Norwegian IT consulting company with over 100 consultants working from two locations. They have teams focused on everything from cloud infrastructure to cloud productivity, from security to business applications, and from collaboration to analytics.
What do they all have in common? They all deliver solutions built on Microsoft technologies! Just like me 🤓
(And just like me, there are many people in Skill who love giving back and helping their communities! I’m honored that I can now call fellow Microsoft MVPs Jan Vidar Elven, Magnus Goksöyr, and Ulrikke Akerbæk my coworkers 🤩)
I’ve joined the Data Management and Analytics team, and will continue to focus on Azure Data and the Microsoft Data Platform. I get to dive deeper into fun things like Azure Synapse Analytics and Azure Data Factory, and I’m hoping to learn even more about Power BI and the rest of the Power Platform. Maybe I’ll even pick up a thing or two about infrastructure, networking, and security?
I’m very much looking forward to this new chapter. Great people, a supportive workplace, and exciting technologies…? I’M SO EXCITED! 😊

On September 28th, 2021, I passed exam DP-900: Azure Data Fundamentals, yay! 🥳 The exam is mainly intended for those who are new to working with the Azure data platform, but is also required for achieving Microsoft partner status in the Data Platform competency.
In this post, I share how I prepared for the exam and what my experience was like on the day of the exam.
On Wednesday, November 17th, 2021, I will be speaking at MVP Dagen 2021! This is a free event where attendees can learn tips and tricks and get updates about Microsoft technologies from Norwegian MVPs.
There are several reasons why this is a very special event to me. It will be my first in-person event since February 2020, and I’m really looking forward to seeing and hanging out with fellow speakers and attendees again! It covers a wide variety of topics so I get to learn about cool things outside my regular data bubble. And… I will be delivering a session in Norwegian… about PowerPoint… Whaaat!? 🤯😁

I will be presenting a brand new session called Bli en PowerPoint (Slide Master)-mester på 1-2-3! (It roughly translates to something like Becoming a PowerPoint (Slide Master) Master in 3 Simple Steps!) It’s a 40-minute mostly demo-based session on how to make PowerPoint work for you instead of against you.
Why am I presenting a session on PowerPoint, though? Excellent question! Johan Ludvig Brattås (@intoleranse) had already submitted a great session called Azure Synapse + Power BI + Purview = True that I want to attend, and I reeeaaally didn’t want to compete with him for a speaking slot. Since attendees will have wildly different backgrounds and expertises, I decided to submit a session on a topic that most are familiar with. So! I chose something I feel like a know a thing or two about: creating slide decks with minimal effort.