Welcome to this Beginner’s Guide to Azure Data Factory! In this series, I’m going to cover the fundamentals of Azure Data Factory in casual, bite-sized blog posts that you can read through at your own pace and reference later. You may not be new to ETL, data integration, Azure, or SQL, but we’re going to start completely from scratch when it comes to Azure Data Factory.
How do you get started building data pipelines? What if you need to transform or re-shape data? How do you schedule and monitor your data pipelines? Can you make your solution dynamic and reusable? Join me in this Beginner’s Guide to Azure Data Factory to learn all of these things - and maybe more. 🤓 Let’s go!
P.S. This series will always be a work-in-progress. Yes, always. Azure changes often, so I keep coming back to tweak, update, and improve content. I just might not be able to do it right away!
Hi! I’m Cathrine 👋🏻 I really like Azure Data Factory. It’s one of my favorite topics, I can talk about it for hours. But talking about it can only help so many people - the ones who happen to attend an event where I’m presenting a session. So I’ve decided to try something new… I’m going to write an introduction to Azure Data Factory! And not just one blog post. A whole bunch of them.
I’m going to take all the things I like to talk about and turn them into bite-sized blog posts that you can read through at your own pace and reference later. I’ve named this series Beginner’s Guide to Azure Data Factory. You may not be new to ETL, data integration, Azure, or SQL, but we’re going to start completely from scratch when it comes to Azure Data Factory.
In the introduction to Azure Data Factory, we learned a little bit about the history of Azure Data Factory and what you can use it for. In this post, we will be creating an Azure Data Factory and navigating to it.
Spoiler alert! Creating an Azure Data Factory is a fairly quick click-click-click process, and you’re done. But! Before you can do that, you need an Azure Subscription, and the right permissions on that subscription. Let’s get that sorted out first.
Azure Subscription and Permissions
If you don’t already have an Azure Subscription, you can create a free account on azure.microsoft.com/free. (Woohoo! Free! Yay!) Some of the Azure services will always be free, while some are free for the first 12 months. You get $200 worth of credits that last 30 days so you can test and learn the paid Azure services. One tip: Time your free account wisely ⏳
In the previous post, we started by creating an Azure Data Factory, then we navigated to it. In this post, we will navigate inside the Azure Data Factory. Let’s look at the Azure Data Factory user interface and the four Azure Data Factory pages.
Azure Data Factory Pages
On the left side of the screen, you will see the main navigation menu. Click on the arrows to expand and collapse the menu:
In the previous post, we looked at the Azure Data Factory user interface and the four main Azure Data Factory pages. In this post, we will go through the Author page in more detail and look at a few things on the Monitoring page. Let’s look at the different Azure Data Factory components!
Azure Data Factory Components on the Author Page
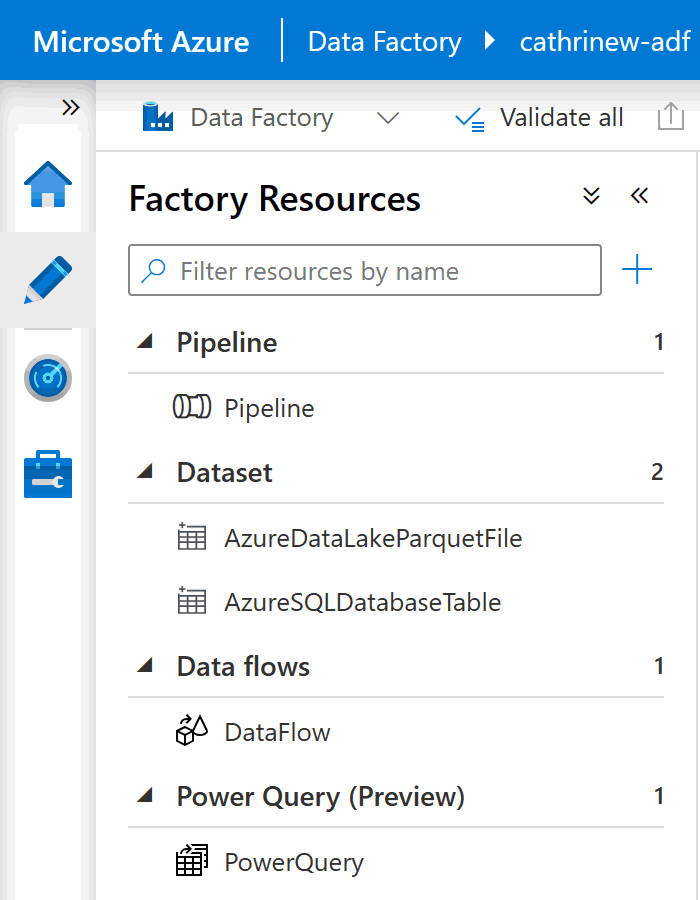
On the left side of the Author page, you will see your factory resources. In this example, we have already created one pipeline, two datasets, one data flow, and one power query:
Let’s go through each of these Azure Data Factory components and explain what they are and what they do.
In the previous post, we looked at the different Azure Data Factory components. In this post, we’re going to tie everything together and start making things happen. Woohoo! First, we will get familiar with our demo datasets. Then, we will create our Azure Data Lake Storage Account that we will copy data into. Finally, we will start copying data using the Copy Data Tool.
Demo Datasets
First, let’s get familiar with the demo datasets we will be using. I don’t know about you, but I’m a teeny tiny bit tired of the AdventureWorks demos. (I don’t even own a bike…) WideWorldImporters is at least a little more interesting. (Yay, IT joke mugs and chocolate frogs!) But! Let’s use something that might be a little bit more fun to explore.