On Saturday, October 2nd, I’m guesting the anniversay show of Rockin’ The Code World with dotNetDave 🥳 The show starts at 10:00 AM PST / 19:00 CEST and we’ll be talking about things like Azure Data, blogging, career development, and maybe even a little bit about keeping up in a fast-paced world. Yay! I hope you’ll tune in 🤓

You can find the previous shows and several other shows on C# Corner Live.
(Oh, and if you like free stuff… Since this is the anniversary show, there will be books, swag, and prizes! 🤑)
It’s been one month since I migrated from WordPress to Hugo. In my original post, I mentioned some of the immediate benefits of migrating: I saved money, performance went up, and I was totally geeking out about getting to learn new skills. It was all about the tech, really. Today, I want to reflect on some of the less obvious benefits and how migrating has had a positive impact on me this past month 😊
I think I can summarize it in one sentence:
I enjoy blogging again because I’ve taken back control of my website.
That sounds a bit strange, doesn’t it? I mean, this has always been my website and I have always been in control of it. But what I’ve realized is that for many years, WordPress and its features and plugins shaped how I used - and didn’t use - my blog.
I can’t and I don’t really blame WordPress. This is mostly about my habits and thought processes and how I started changing them. However, that change only happened because I migrated to a new blogging platform. It was only after I started using Hugo that I realized how I could do things differently.
So what’s different now?
Did you know that PowerPoint can help you improve your presentation skills? 💡 If you rehearse with the PowerPoint Presenter Coach, you can get real-time feedback on things like your pace and language. If that’s too distracting (it is for me), you can choose to hide the real-time feedback and only view the detailed report at the end of your rehearsal.
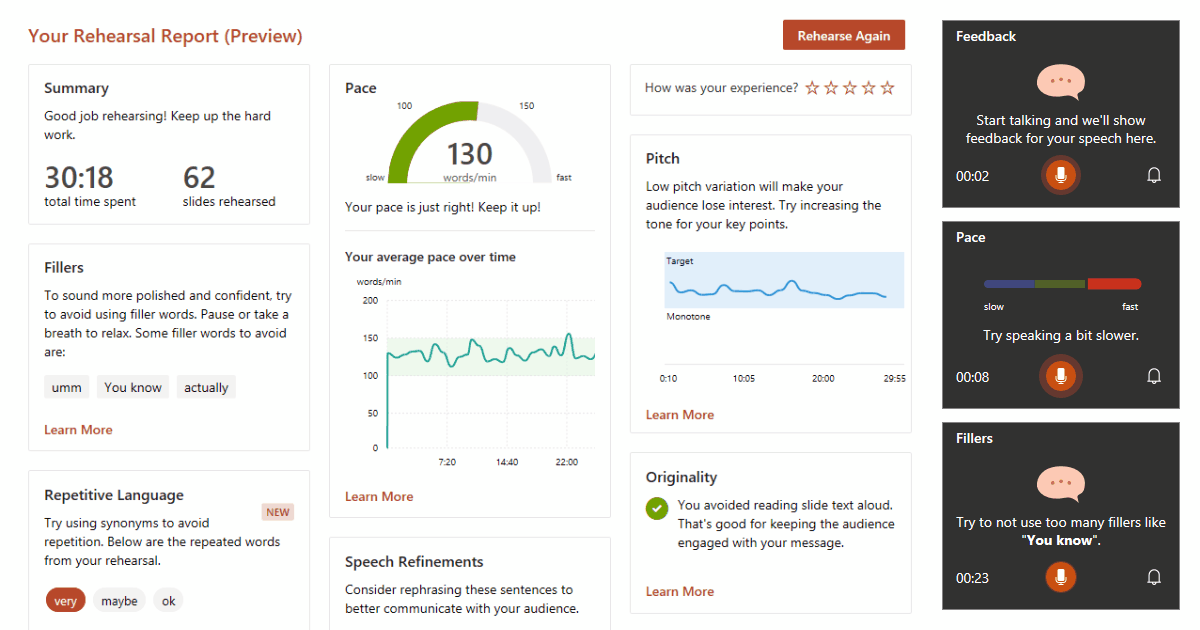
The report shows you details about the total time spent, your pace and pitch over time, whether or not you are simply reading from your slides, as well as actionable feedback on your language. The feedback includes whether you are using too many filler words (like umm, actually, or you know), whether you are using too many repetitive words with alternatives you can use instead, whether you are using any words that can be offensive, and specific sentences that you can refine.
The PowerPoint Presenter Coach works on Windows, macOS, iOS, Android, and in PowerPoint online 🥳 However, it currently only understands English. Let’s hope it will learn new languages soon!
I delivered my first ever keynote at Data Saturday Oslo 2021, called “I can’t keep up!” - Turning Discomfort into Personal Growth in a Fast-Paced World. We decided to record it, and it has now been published on the brand new Data Saturday Oslo YouTube channel. Yay! 🤓
On Saturday, September 4th, 2021, I will deliver the keynote at Data Saturday Oslo 2021: “I can’t keep up!” - Turning Discomfort into Personal Growth in a Fast-Paced World. My feelings can be summarized in this series of emojis: 😱🤩🤯🤓🥳 I’m freaking out, absolutely honored, can’t really believe this is real, super excited, and very much looking forward to it!
