Data Flows in Azure Data Factory

So far in this Azure Data Factory series, we have looked at copying data. We have created pipelines, copy data activities, datasets, and linked services. In this post, we will peek at the second part of the data integration story: using data flows for transforming data.
But first, I need to make a confession. And it’s slightly embarrassing…
I don’t use data flows enough to keep up with all the changes and new features 😳
Don’t get me wrong. I want to! I really, really, really want to. But since I don’t currently use data flows on a daily basis, I struggle to find time to sit down and dig into all the cool new things.
So! In this blog post, I will mostly scratch the surface of data flows, then refer to awesome people with excellent resources so you can learn all the details from them.
On a related note: The Matrix is over 20 years old… are we getting closer to learning things the way Neo learns kung fu? I could totally use that in this case 😂
(Also, how on earth is The Matrix over 20 years old already? HOW OLD AM I??? 🤯)
Anyway! Where was I? Right!
Mapping and Wrangling Data Flows
In Azure Data Factory, you can create two types of data flows: Mapping or Wrangling.

Back in May 2019, I wrote a blog post comparing them. Back then, Mapping Data Flows were in public preview and Wrangling Data Flows were in limited private preview. In the 6-7 months since I wrote that post, Mapping Data Flows have become generally available and Wrangling Data Flows have gone into public preview.
While there have been many updates and improvements since I wrote that post, it’s still highly relevant. So instead of me duplicating that content in this post, I’ll kindly ask you to hop on over to my other post. Then come back here and continue this series 😊
Alright! Let’s look at a basic example.
Creating a Mapping Data Flow
In the copy data tool, we copied LEGO data from the Rebrickable website into our Azure Data Lake Storage. Now, we want to load data from Azure Data Lake Storage, add a new column, then load data into the Azure SQL Database we configured in the previous post.
From the Author page, create a new data flow:
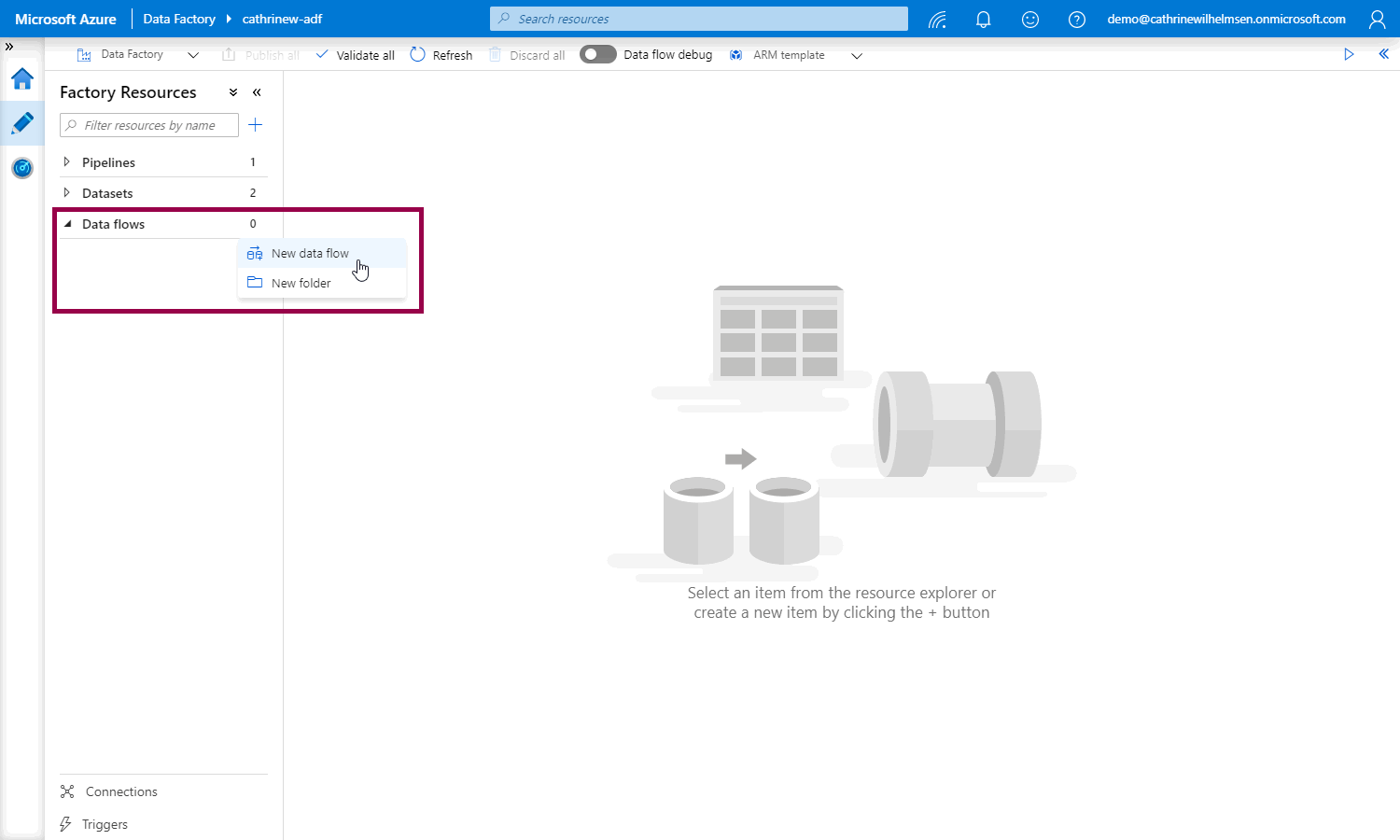
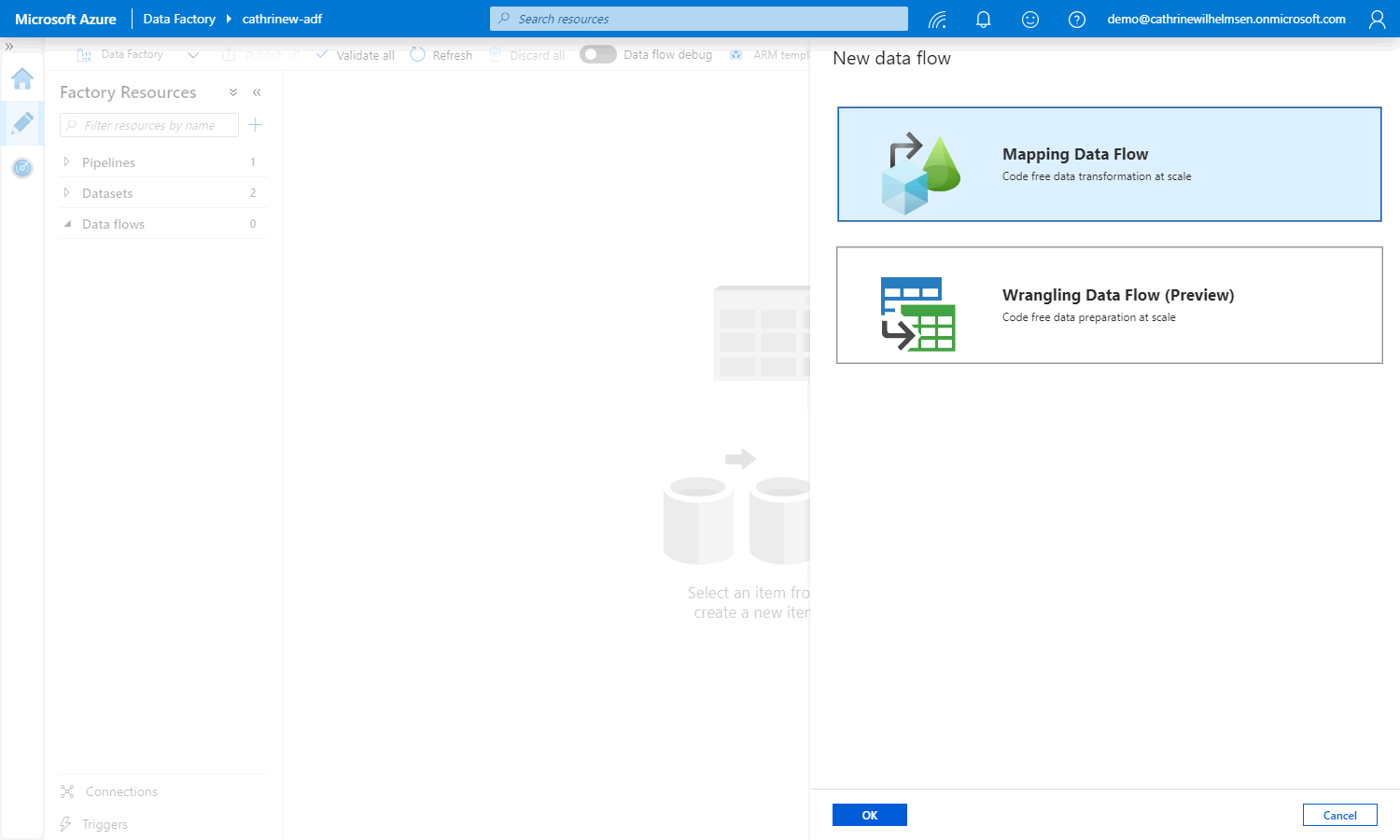
Select Mapping Data Flow:
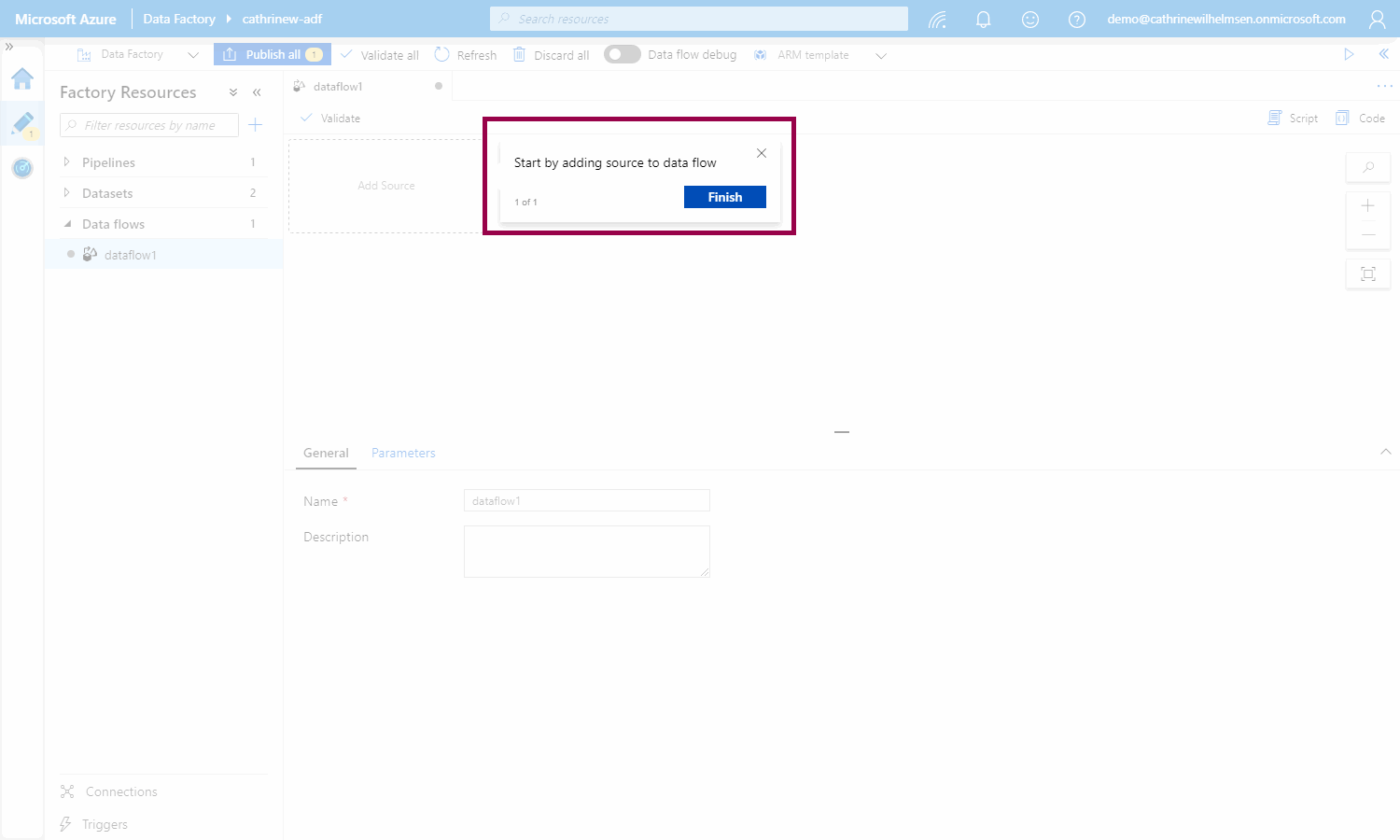
The first time you create a mapping data flow, you will be guided through the experience with these popup tips:
If you ever want to reference these popup tips again, you can click the help / information button, and then click guided tour:
You start creating your mapping data flow by adding a source:
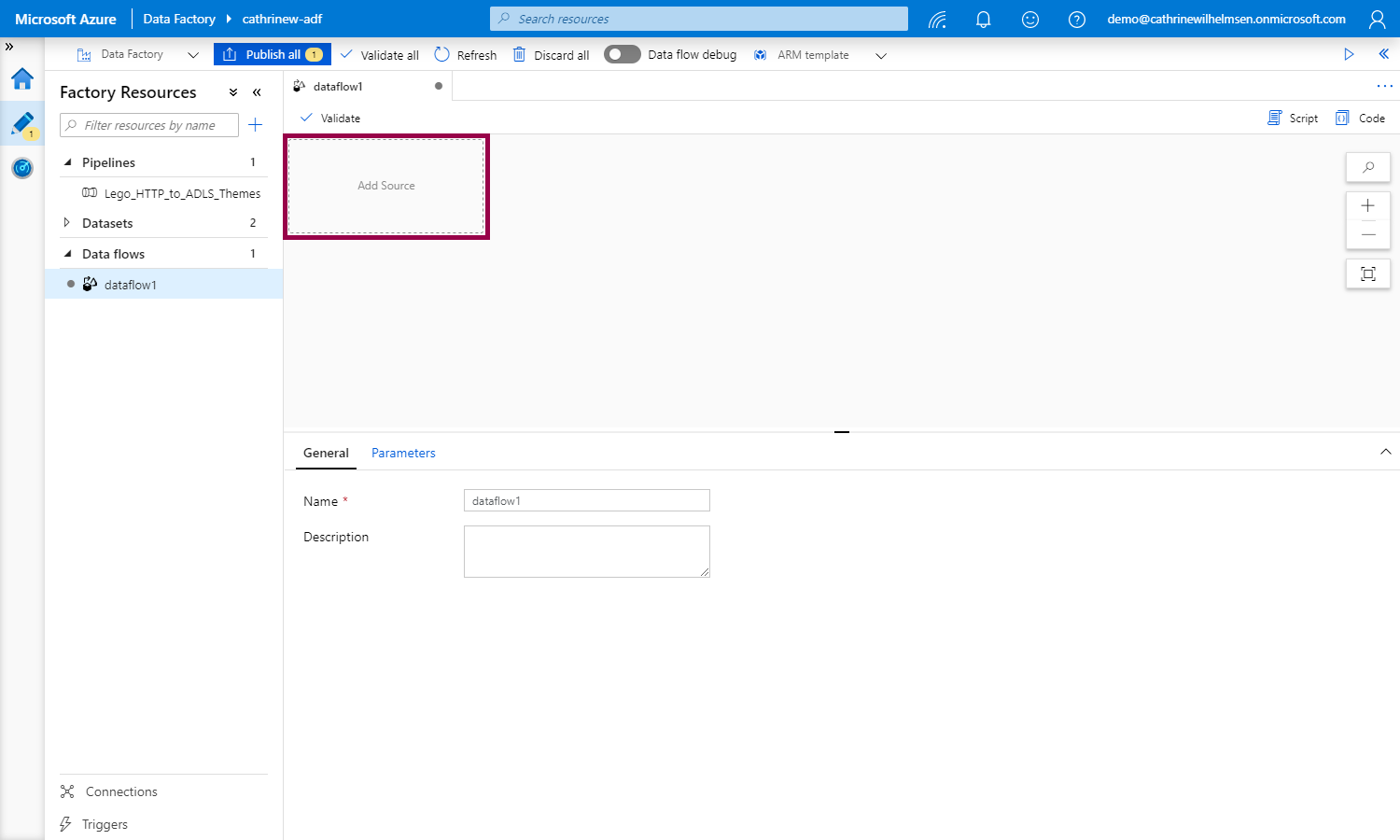
Configure the source settings in the configuration panel at the bottom:
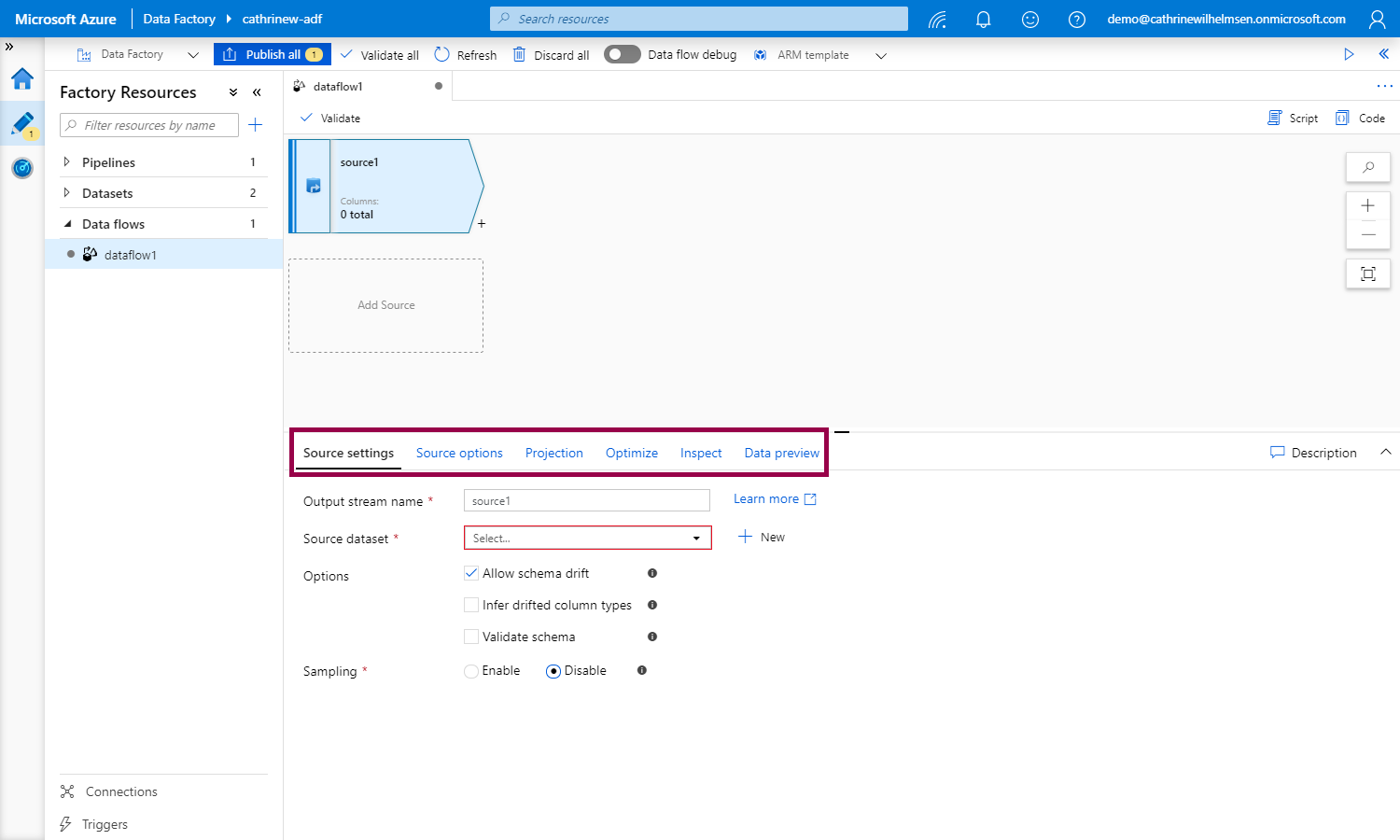
To add transformations, click the + sign, then choose a transformation:
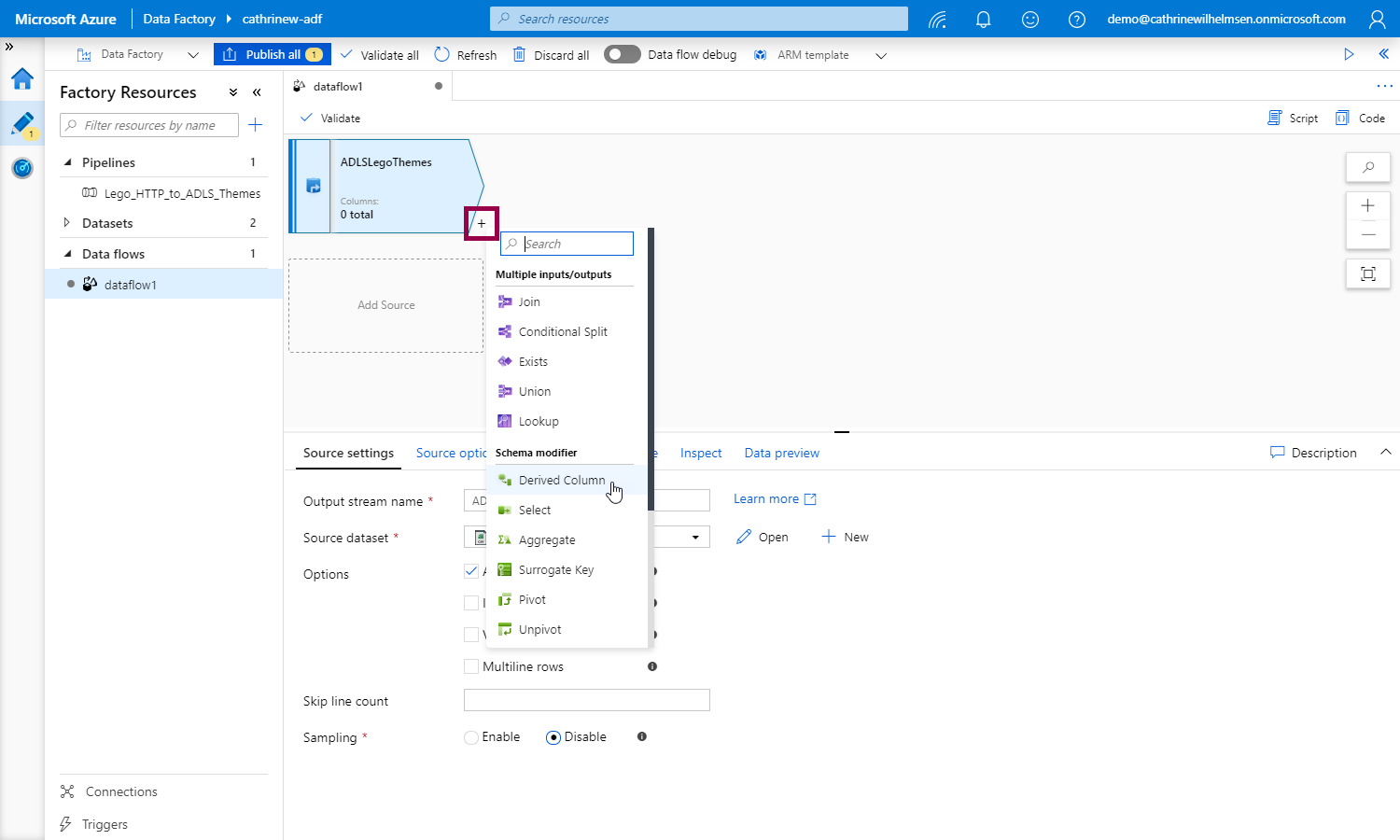
In this example, we want to add an additional column, so we choose the Derived Column transformation. We define a new column called load_date, and click on the expression:
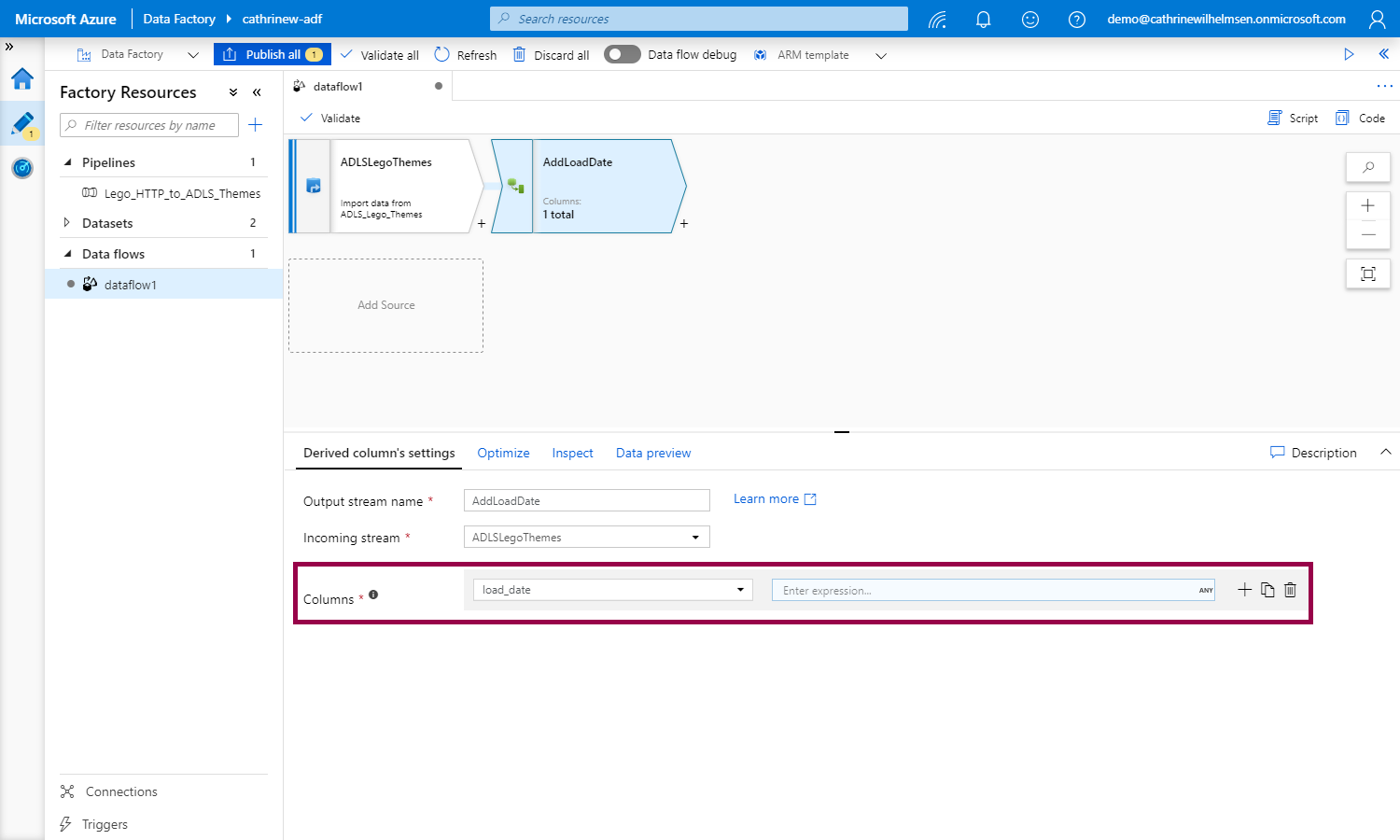
This opens the visual expression builder. In here, we can define our new column. If we start typing, the intellisense will help us:
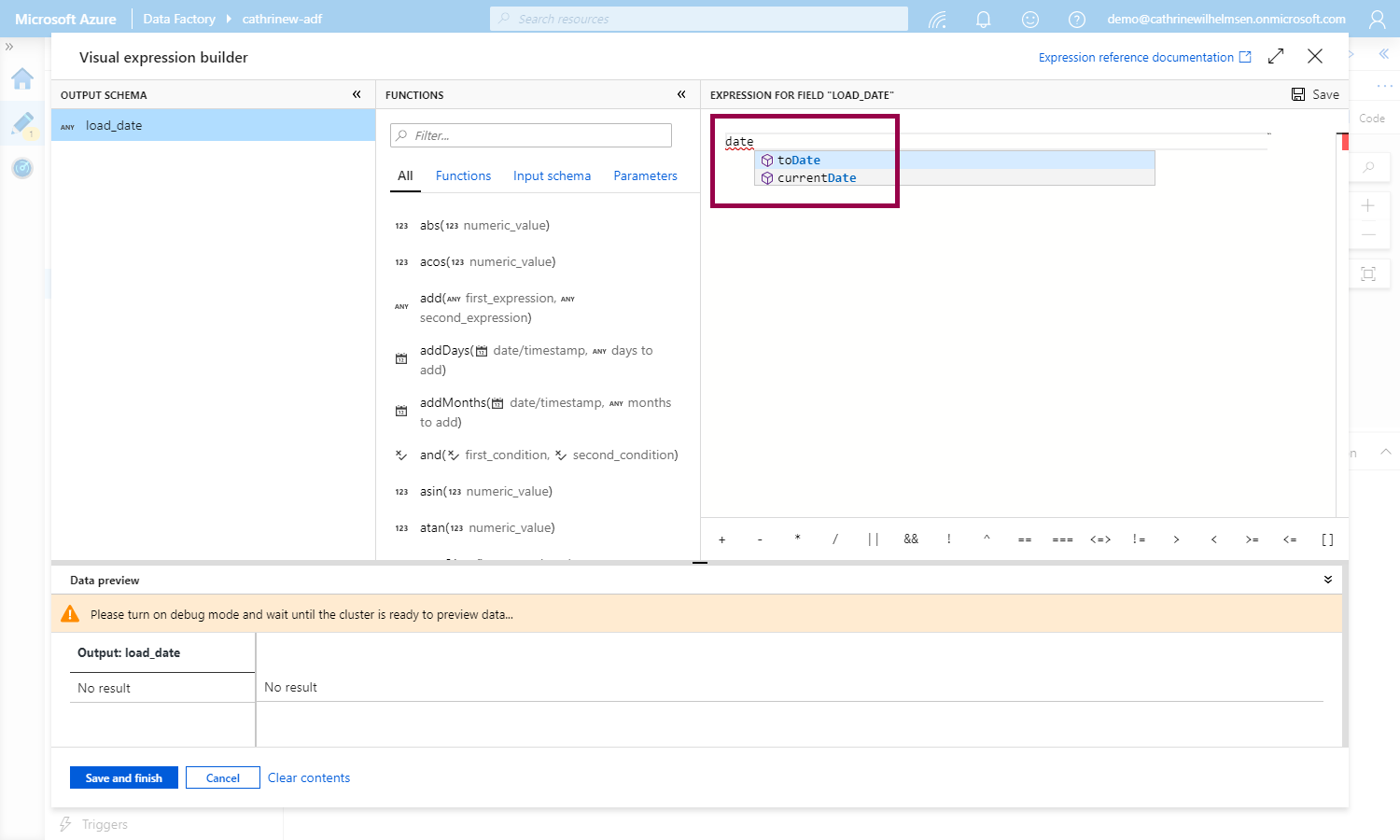
Once we have defined the column, we see a little icon telling us what data type is used:
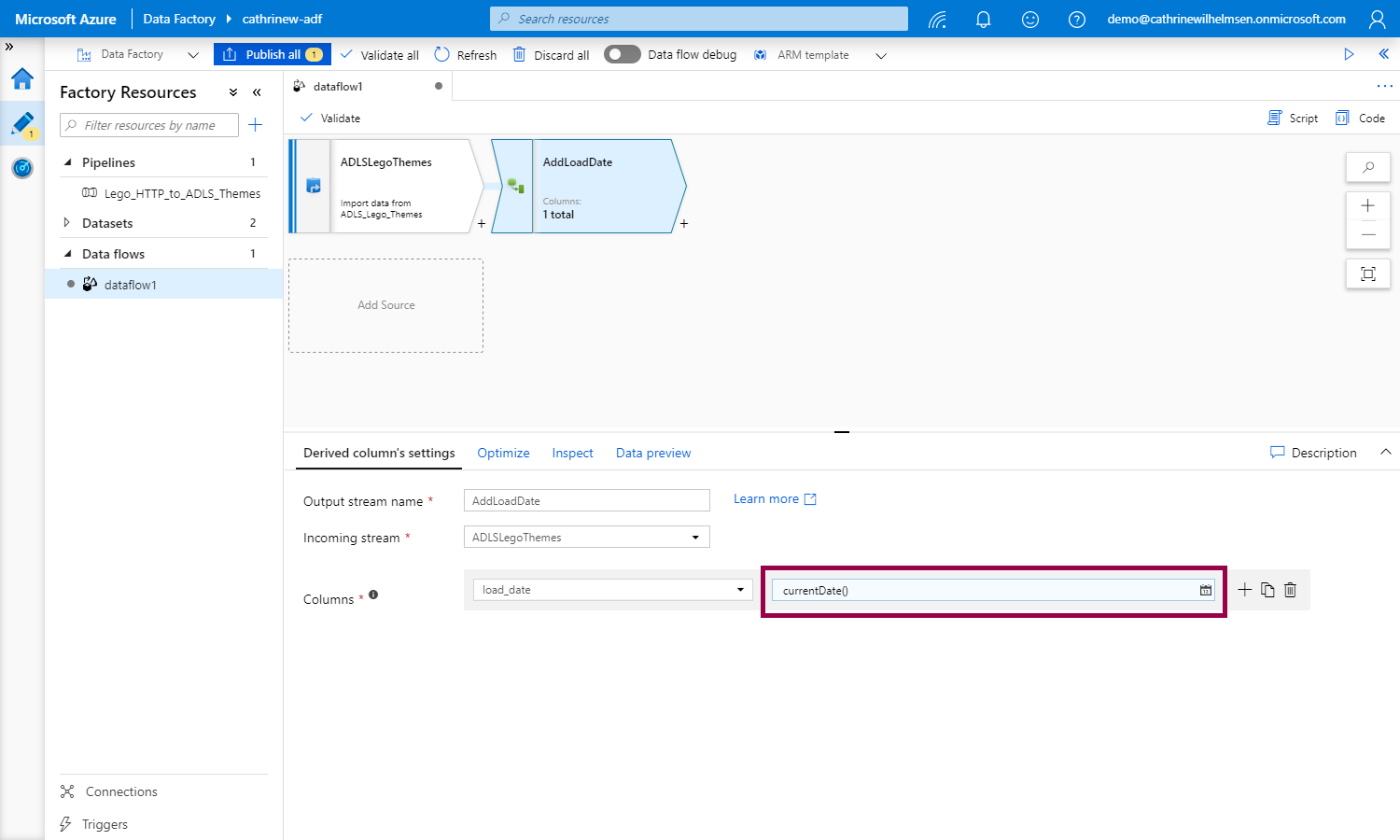
We can now sink the data into the database:
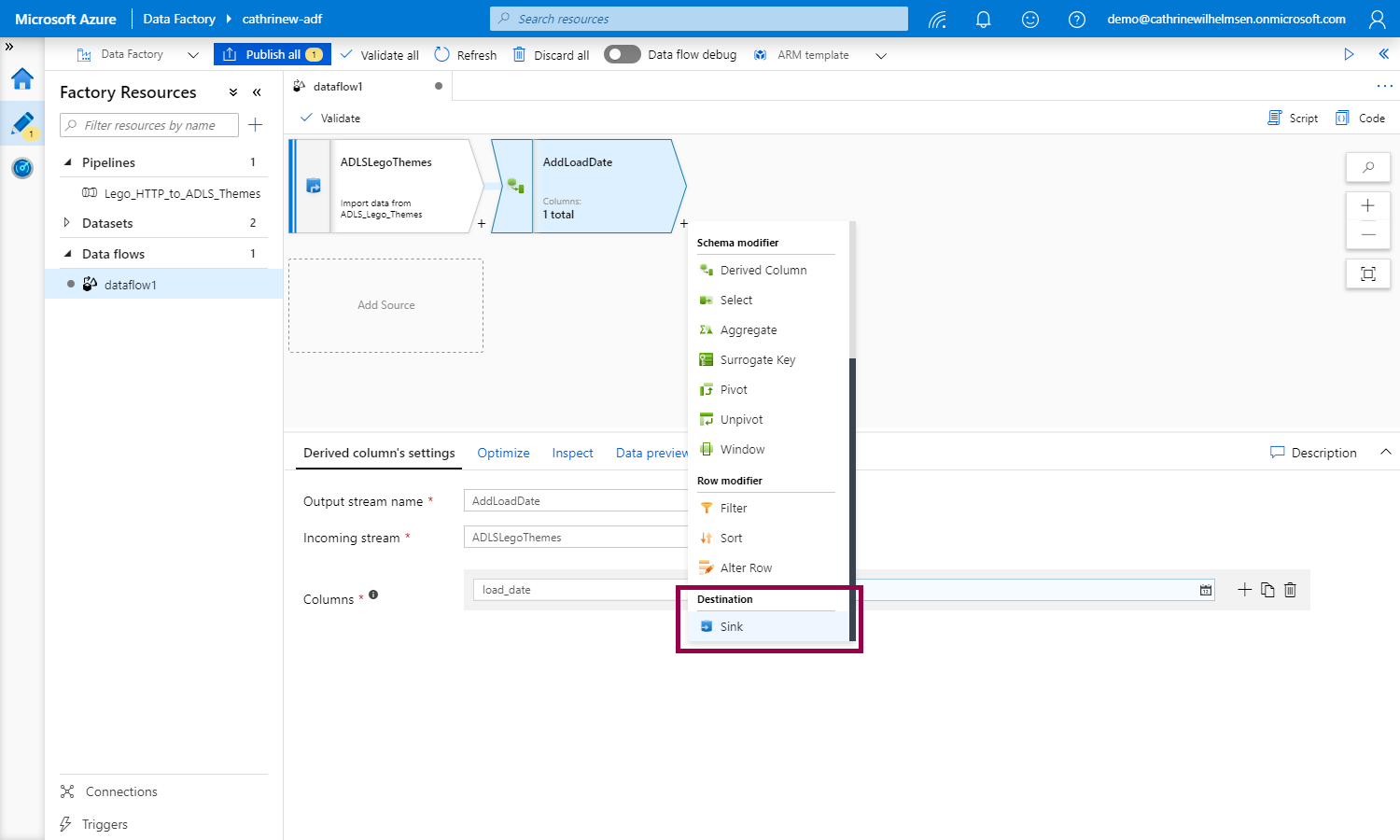
In the previous post, we created the Azure SQL Database linked service. Now, we can create the dataset from the data flow. Click + New:
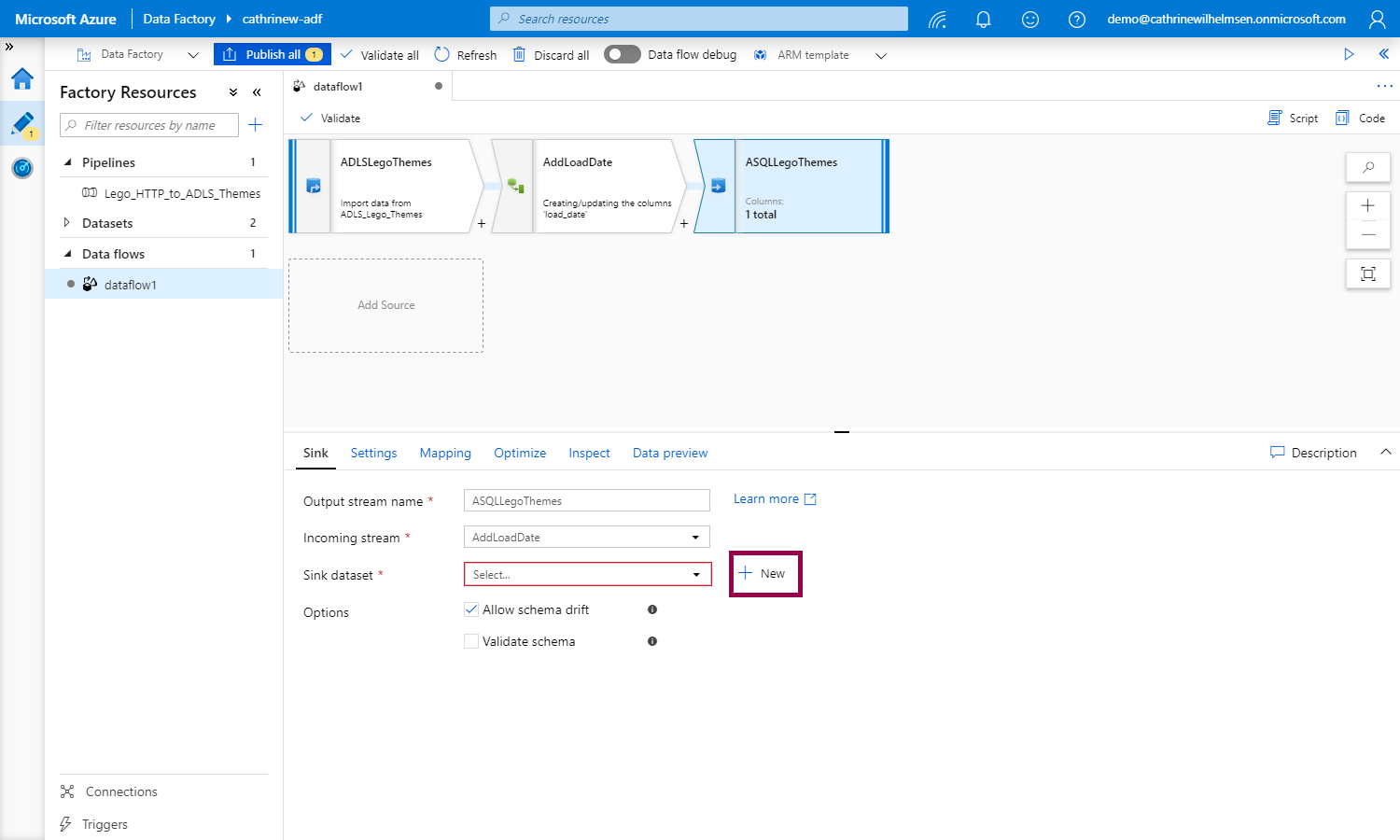
We see that only some connectors are supported, the others are grayed out. Click Azure SQL Database:
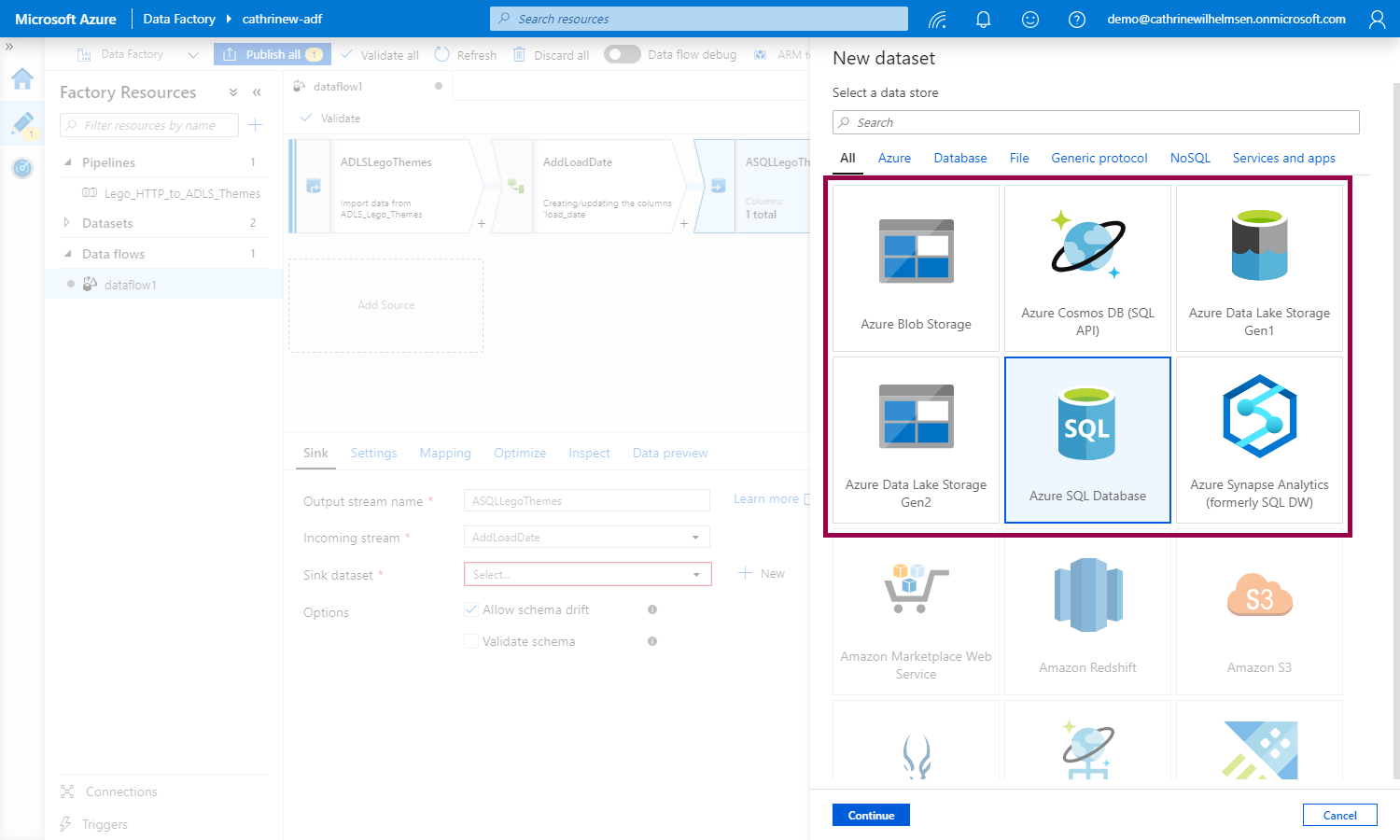
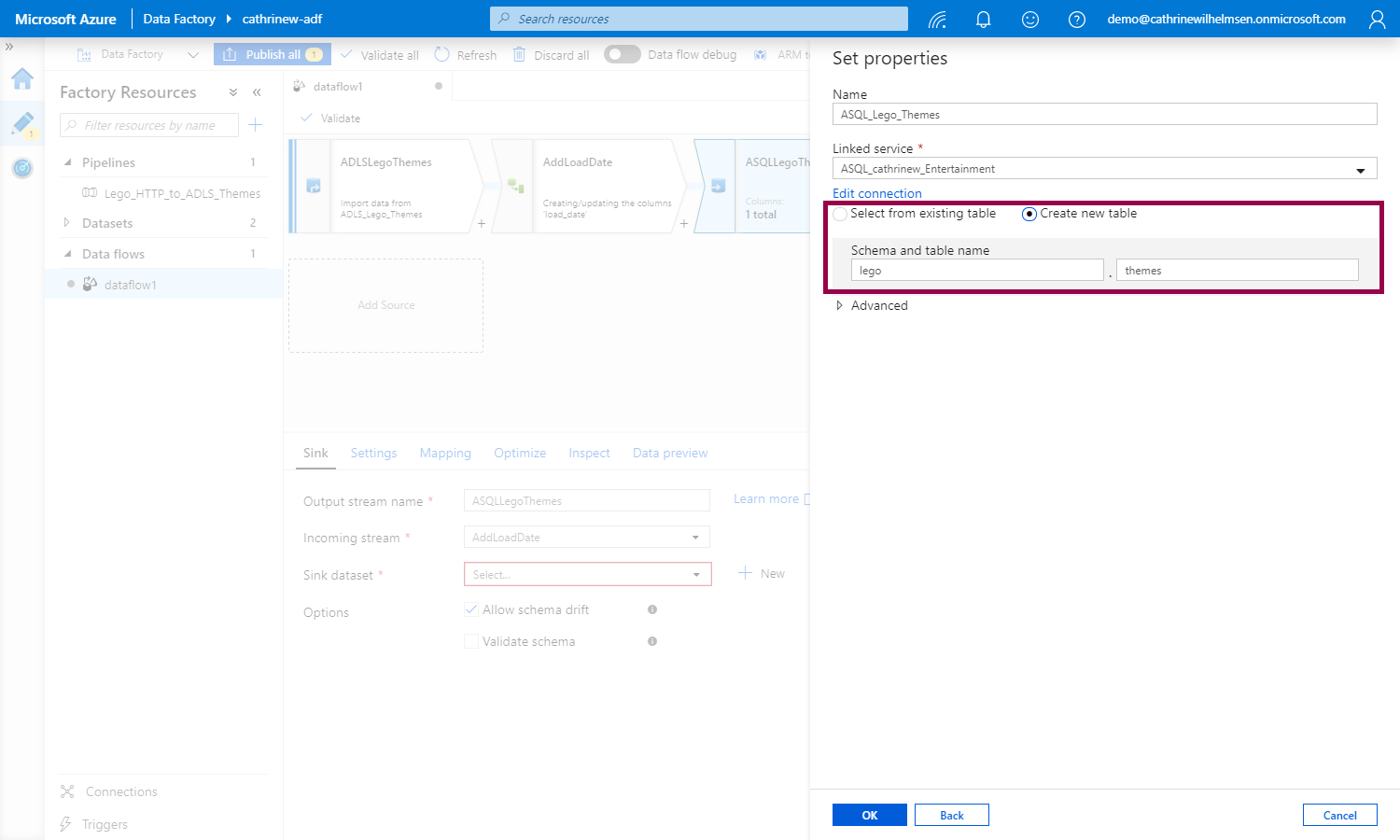
When creating the dataset, we can specify that we want to create the table the first time we run the data flow. Cool! Just keep in mind that the schema must already exist 😊
And in the sink settings, if the table already exists, we can specify that we want to truncate the table before loading into it - simply by checking a box. Also cool! 🤩

Finally, give the data flow a descriptive name, and click publish to save your changes:
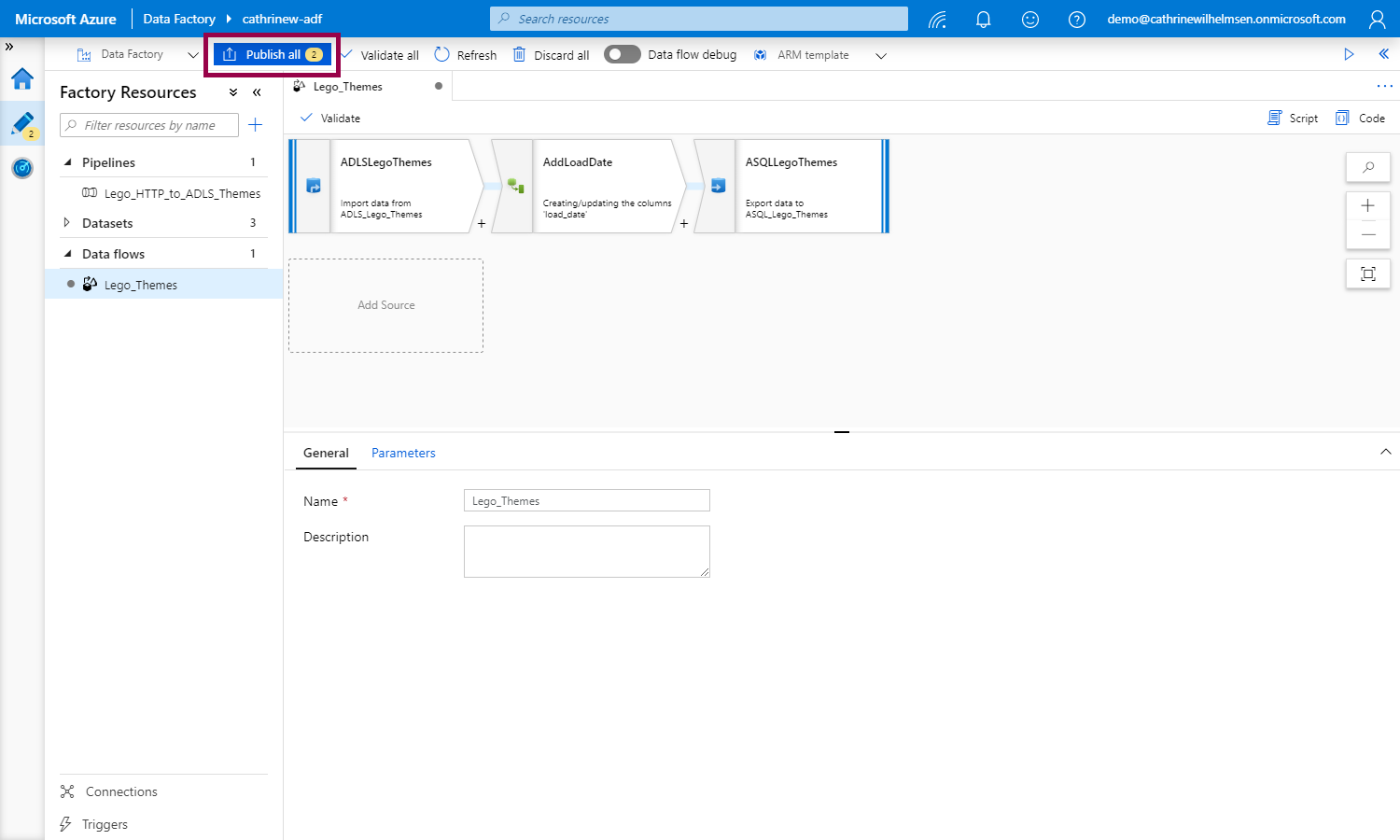
Now that you have created a data flow, you need to add it to a pipeline. And unlike the copy data activity, which lives inside a single pipeline, a data flow can be added to multiple pipelines.
Adding Data Flows to Pipelines
Let’s create a new pipeline. Give it the name Lego_ADLS_to_ASQL_Themes, then drag a data flow activity onto the design canvas:
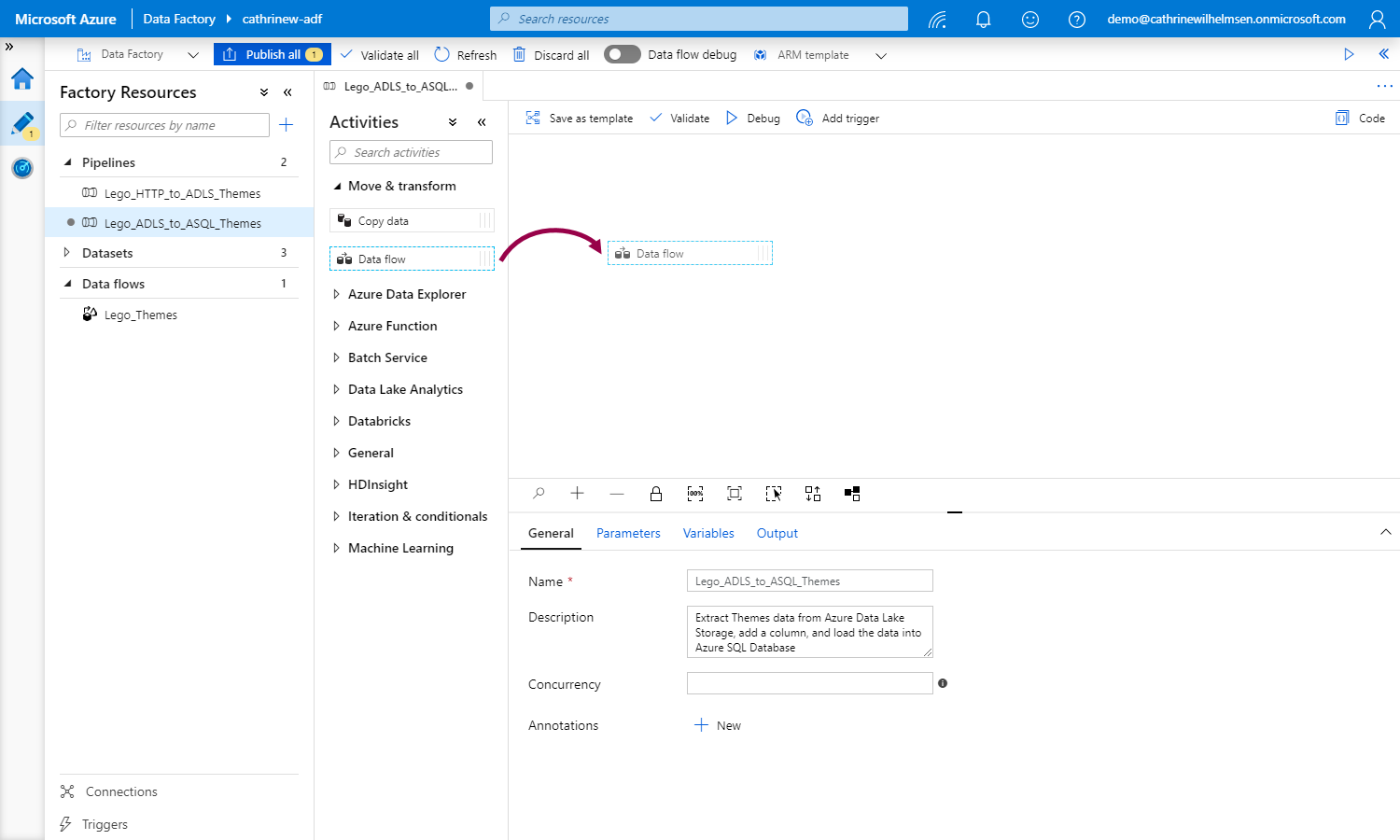
Select the Lego_Themes data flow we just published:
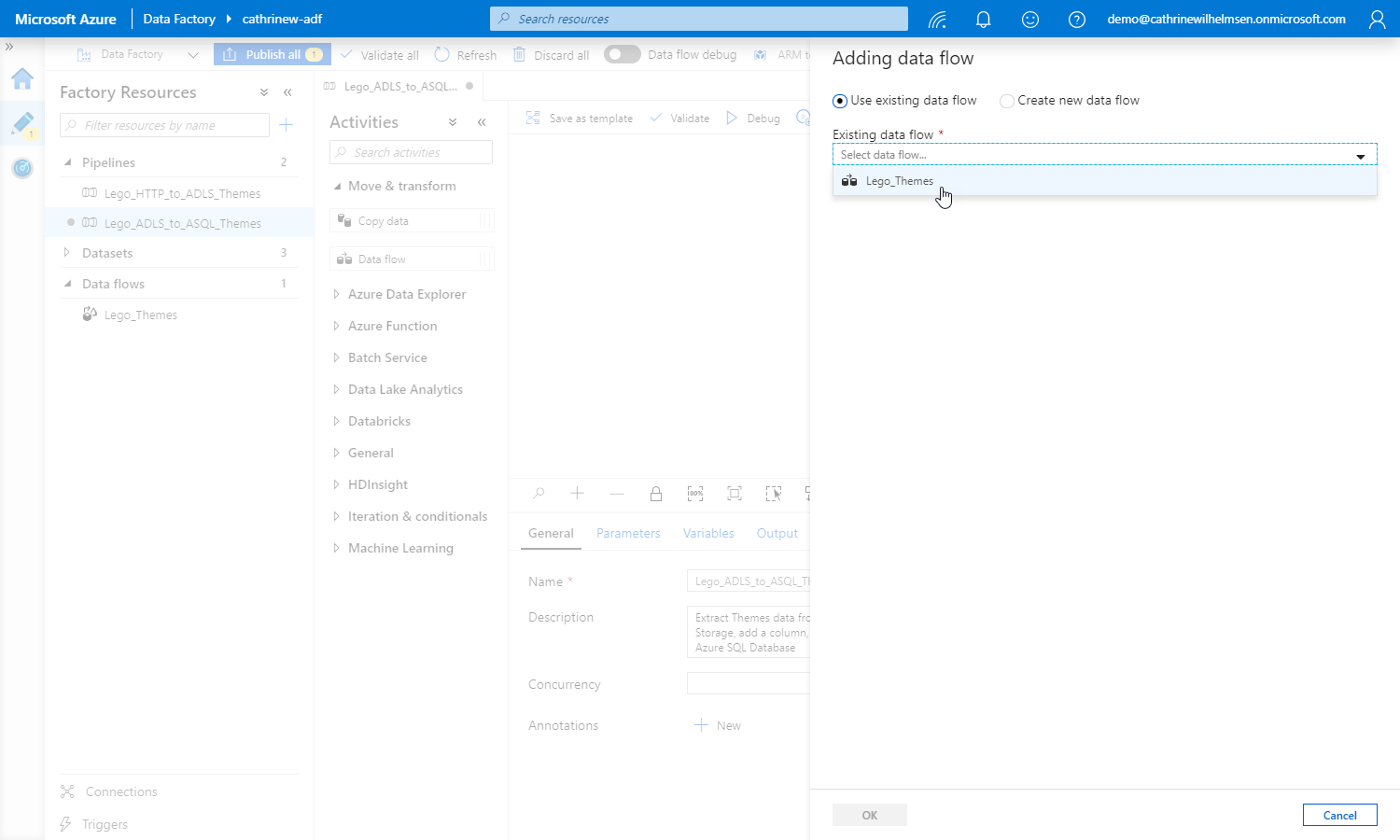
Aaaand… that’s pretty much it!
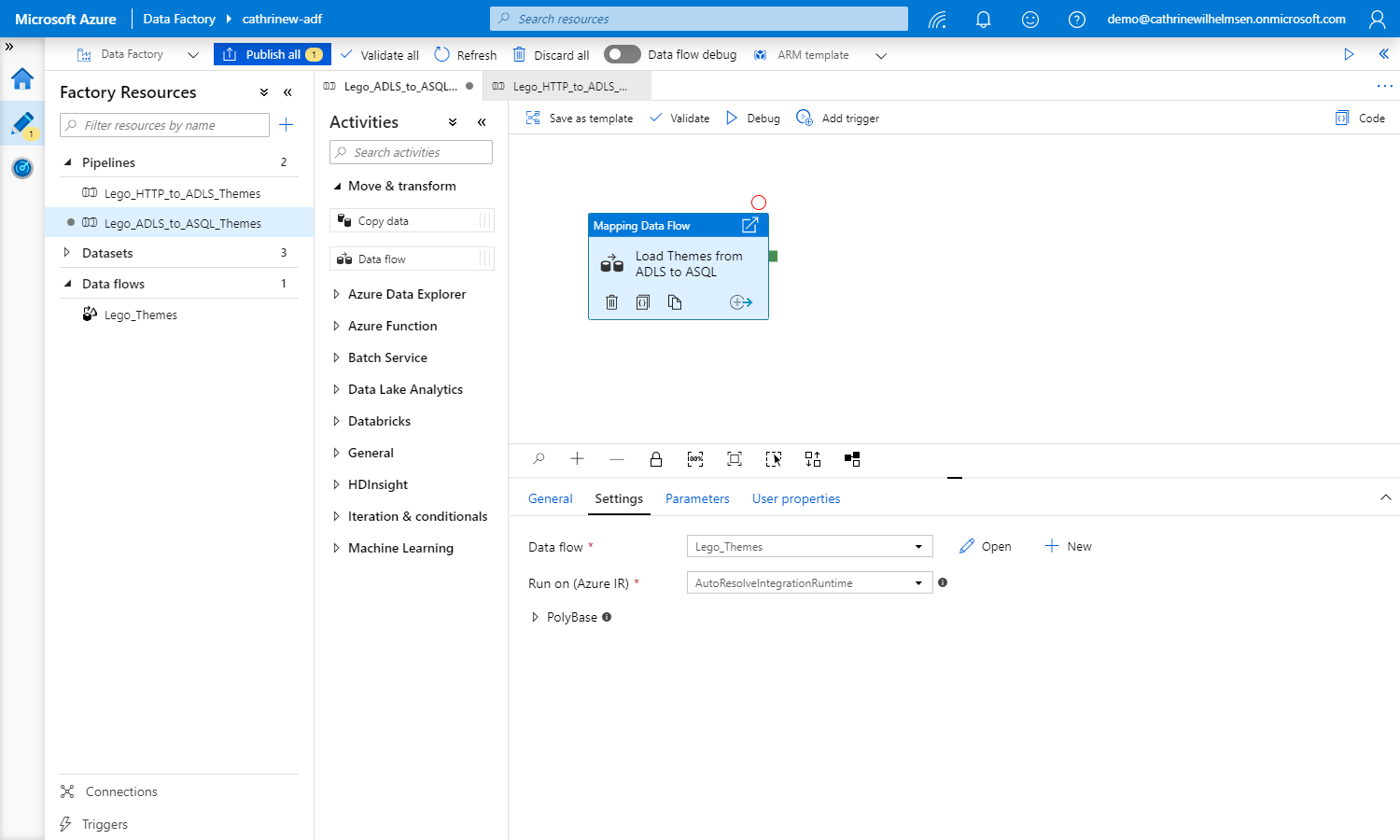
When you use a copy data activity, you configure the source and sink settings inside the pipeline. When you use a data flow, you configure all the settings in the separate data flow interface, and then the pipeline works more as a wrapper. That’s why the data flow settings are fairly simple in the screenshot above, at least compared to the copy data activity.
Now, this is a basic example to walk you through some of the interface, but you can do so much more with data flows. And now we’re getting to what I consider the most important part of this post. The external links!
Resources and Continued Learning
If there’s one thing you take away from this post, it’s this link:
All Links and Resources: aka.ms/dflinks
Bookmark it 🤓 From there, you will find links to the official documentation, tutorials, videos, hands-on labs, performance guides, and training slides.
Most of this content is created by Mark Kromer, Senior Program Manager in Microsoft. (He’s brilliant!) Make sure you follow his blog and his Twitter accounts: @KromerBigData and @mssqldude.
While you’re at it, also follow Azure Data Factory on Twitter: @DataAzure and subscribe to their channel on YouTube: aka.ms/adfvideos.
Summary
In this post, I basically told you to visit a bunch of other websites, hahaha 😅
The reason for that is that things are moving so fast in Azure Data Factory, with most of the changes and improvements currently being made to data flows. If this is a feature that you want to use, it’s important for you to know how to keep learning and stay updated after reading this post. Because I’m the first to admit that there there are others who do a much better job of teaching the nitty gritty details of data flows 😊
In the next post, we will start wiring up our solution and make it look something like this:
About the Author
 Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓
Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓