Comparing Mapping and Wrangling Data Flows in Azure Data Factory
Please note: Since I wrote this post, Wrangling Data Flows have been renamed to Power Queries, and there have been many updates in Azure Data Factory. I'm keeping this post as-is, please make sure you also read the official documentation.
In 2019, the Azure Data Factory team announced two exciting features. The first was Mapping Data Flows (currently in Public Preview), and the second was Wrangling Data Flows (currently in Limited Private Preview). Since then, I have heard many questions. One of the more common questions is “which should I use?” In this blog post, we will be comparing Mapping and Wrangling Data Flows to hopefully make it a little easier for you to answer that question.

Should you use Mapping or Wrangling Data Flows?
Now, we all know that the consultant answer to “which should I use?” is It Depends ™ 😄 But what does it depend on?
To me, it boils down to a few key questions you need to ask:
- What is the task or problem you are trying to solve?
- Where and how will you use the output?
- Which tool are you most comfortable using?
Before we dig further into these questions, let’s start with comparing Mapping and Wrangling Data Flows.
Mapping Data Flows

Use Mapping Data Flows to visually transform data without having to write any code. You can focus on the transformations and logic, while Azure Data Factory does the heavy lifting behind the scenes. It translates your transformations and logic to code that runs on scaled-out Azure Databricks clusters for maximum performance.
A Mapping Data Flow can look something like this:
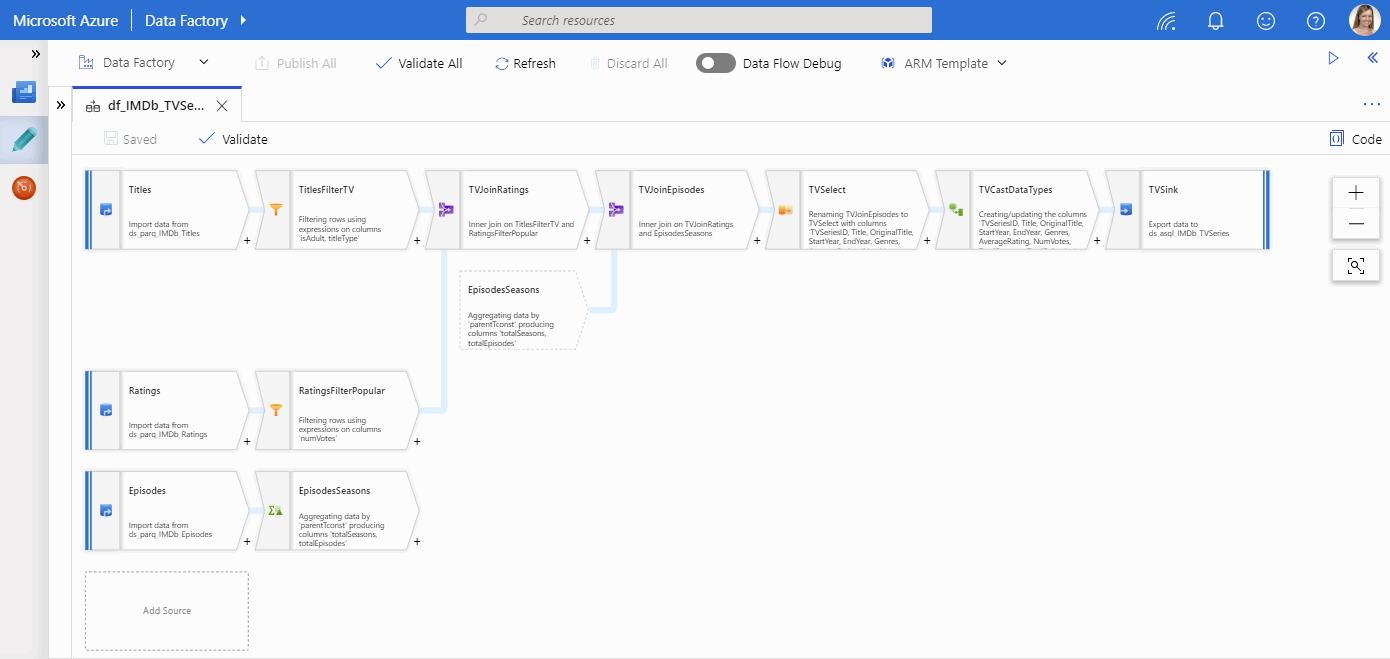
The focus in this interface is on the flow. You can quickly identify your sources, transformations, branches, joins, and sinks. To see the actual data, you need to enable Data Flow Debug and preview the data per transformation.
Wrangling Data Flows

Use Wrangling Data Flows to visually explore and prepare datasets using the Power Query Online mashup editor. You can focus on the modeling and logic, while Azure Data Factory does the heavy lifting behind the scenes. It translates the underlying M code to code that runs on a managed Spark environment for maximum performance.
A Wrangling Data Flow can look something like this:
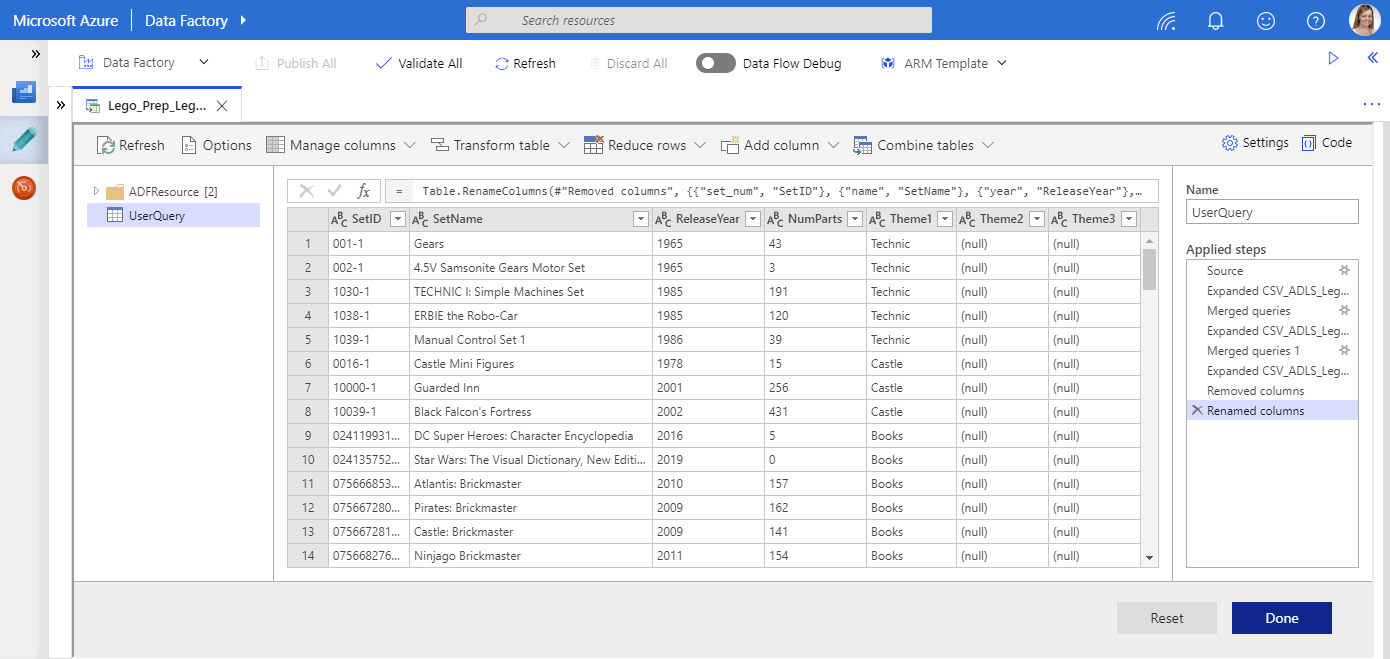
The focus in this interface is on the data. You can quickly see what the final dataset will look like. To see the actual sources, transformations, and joins, you need to go through the list of Applied Steps.
Comparing Mapping and Wrangling Data Flows
When comparing Mapping and Wrangling Data Flows, we see that there is some overlap, but also some key differences.
Data Sources and Sinks
Mapping and Wrangling Data Flows currently both support the same sources and sinks. These include Azure Blob Storage, Azure Data Lake Storage Gen1 and Gen2, Azure SQL Database, and Azure SQL Data Warehouse.
Transformations
You can do many of the same transformations in Mapping and Wrangling Data Flows. For example filtering rows, adding and renaming columns, merging / joining datasets, grouping, and sorting.
However, if you are loading data into a database, Mapping Data Flows can also handle inserts, updates, deletes, and upserts. These row operations are managed behind the scenes, so all you have to do is enable the features and define the rules. There are also pre-defined templates available with common ETL patterns like SCD1 and SCD2.
Schema Drift
You can create Mapping Data Flows to handle schema drift if your source changes frequently. For example, if columns are added or removed, the destination can be automatically updated to include or exclude those columns. In Wrangling Data Flows, you need to make these changes manually.
File and Table Handling
Mapping Data Flows has built-in support for file handling, such as moving files after they have been read. You can also choose to recreate sink tables during execution. This means that you won’t have to manually create and execute T-SQL scripts before loading data.
Bonus: Analyzing the Icons
Wait, what? The icons? What does that have to do with anything? Well, they are more than just pretty illustrations. They are also supposed to represent the features 💡
Compare Mapping Data Flows (left) and Wrangling Data Flows (right):
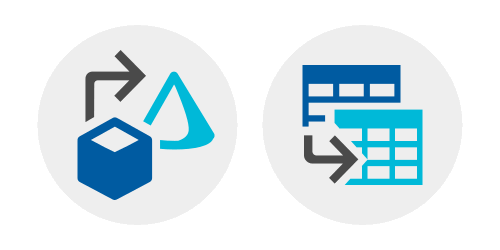
The Mapping Data Flows icon shows a cube pointing to a cone. To me, this represents transformation. For example, transforming raw source data into facts and dimensions in a dimensional model.
The Wrangling Data Flows icon shows one dataset pointing to another dataset. To me, this represents preparation. For example, cleaning up a dataset and reshaping it so it can be used elsewhere.
Now, I know that I might be the odd one out here reading way too much into this! 🤓 But the icons do actually help me remember the differences and use cases.
Choosing Between Mapping and Wrangling Data Flows
After comparing Mapping and Wrangling Data Flows, I have simplified my definitions to:
- Mapping Data Flows: Transform Data (known data and schemas)
- Wrangling Data Flows: Prepare and Explore Data (known or unknown datasets)
This is obviously not 100% accurate for every single use case and edge case out there, but it’s a good start. That brings us back to the questions we started with. How would you answer these questions?
What is the task or problem you are trying to solve?
Do you need to do known-schema to known-schema mapping, for example loading facts and dimensions? Use Mapping Data Flows. They support row operations, and have pre-defined templates for handling common ETL patterns like SCD1 and SCD2.
Do you need to create a brand new dataset, but aren’t really sure if you have the data you need? Use Wrangling Data Flows. The Power Query Online mashup editor makes it easy to visually explore your data.
Where and how will you use the output?
If your destination is an Azure SQL Data Warehouse, then it’s pretty clear: Mapping Data Flows is the best choice. But what if you just need to create a dataset and load it into Azure Data Lake Storage? That might not be as clear. Both Mapping and Wrangling Data Flows can do that.
And that brings us to you. What is your skill set? What do you prefer?
Which tool are you most comfortable using?
Have you used SQL Server Integration Services (SSIS)? Mapping Data Flows should feel familiar. If you have many sources and sinks, branches, joins, or conditional logic, it can be much easier to see this visualized in a Mapping Data Flow. It will take fewer clicks to get an overview of the flow.
Have you used Power Query? Wrangling Data Flows should definitely feel very familiar. If you need to prepare data and make sure the output is usable, it can be much easier to work in a Wrangling Data Flow. It will take fewer clicks to see the end result.
But what if you prefer to code?

Do you already know Scala, Python, or another language? Does the thought of clicking around an interface make you twitch? No problem! Use Azure Databricks Notebooks instead. You can run notebooks in your Azure Data Factory pipelines, so this is entirely your choice. Use the tool you are most comfortable with, as long as it gets the job done.
What about Power BI dataflows?

Should you use Azure Data Factory Data Flows or Power BI dataflows? That is a much longer discussion that I won’t go into in this post 😅
But in short, the main consideration for that decision is who the user is. Power BI dataflows were primarily built as a tool for analysts and business users. It bridges the gap between business and IT, and lets business users create solutions without having to wait for IT. These users will rarely work directly in Azure Data Factory.
On the other hand, if you are already using Azure Data Factory, you most likely have a title like Data Engineer, ETL Developer, Data Integrator, Business Intelligence Consultant, or something similar. You may also use Power BI in your job, but you are not primarily a business user. If you need to collaborate with analysts and business users, or enable them to do their job more efficiently, then Power BI dataflows might be the right choice. But for enterprise-scale ETL and data integration solutions, Azure Data Factory is most likely the right choice. It now just comes with even more features to help you build the best solution for your use case.
(If you want to read more about Power BI dataflows, I recommend Matthew Roche’s series of blog posts: Dataflows in Power BI.)
Learn more and try it!
Read Rohan Kumar’s Analytics in Azure remains unmatched with new innovations announcement.
Watch Gaurav Malhotra and Anand Subbaraj’s session Code-free data integration at scale for Azure SQL Data Warehouse with Azure Data Factory from Microsoft Build 2019.
Sign up for the Wrangling Data Flow Private Preview.
Dig into Gaurav Malhotra’s Wrangling Data Flows Documentation.
Summary
After comparing Mapping and Wrangling Data Flows, the choice boils down to this for me: Do I need to do known-schema to known-schema transformations and mapping? Use Mapping Data Flows. Do I need to prepare or explore data? Use Wrangling Data Flows.
For a modern Data Warehouse solution, I see a use case for both. First, clean and prepare the data using Wrangling Data Flows. Then, load the data into a dimensional model in the Data Warehouse using Mapping Data Flows.
I’m very excited about both of these features. Instead of thinking of them as overlapping and confusing, I like to think of them as giving me even more choices and opportunities! 😊
About the Author
 Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓
Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓