Copy Data Activity in Azure Data Factory

In the previous post, we went through Azure Data Factory pipelines in more detail. In this post, we will dig into the copy data activity. How does it work? How do you configure the settings? And how can you optimize performance while keeping costs down?
Copy Data Activity

The copy data activity is the core (*) activity in Azure Data Factory.
(* Cathrine’s opinion 🤓)
You can copy data to and from more than 90 Software-as-a-Service (SaaS) applications (such as Dynamics 365 and Salesforce), on-premises data stores (such as SQL Server and Oracle), and cloud data stores (such as Azure SQL Database and Amazon S3). During copying, you can define and map columns implicitly or explicitly, convert file formats, and even zip and unzip files – all in one task.
Yeah. It’s powerful! But how does it really work?
Copy Data Activity Overview
The copy data activity properties are divided into six parts: General, Source, Sink, Mapping, Settings, and User Properties.
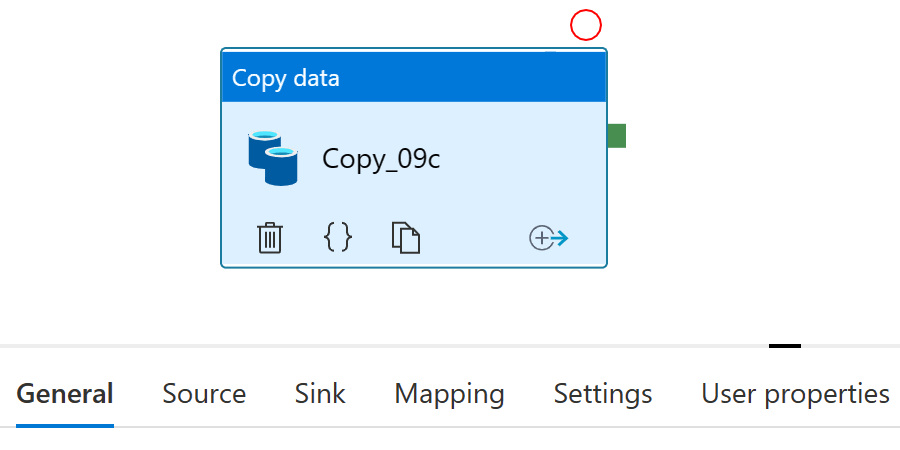
General
First things first! Let’s change the name into something more descriptive than the random “Copy_09c” that was auto-generated in the copy data tool:
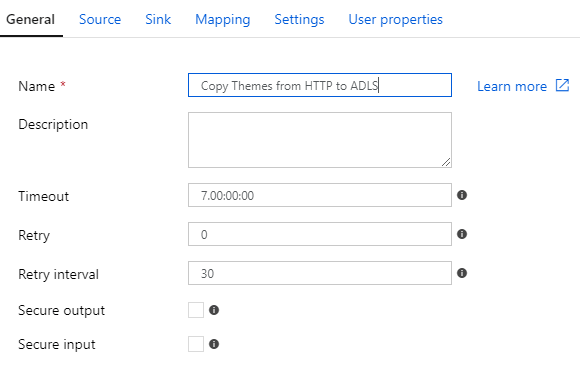
Aaaaah, that’s better! Now I can focus 😂 Alright. Where were we?
In addition to the name and description, you can change the copy data activity policies for activity timeout, retry attempts, retry interval, and whether or not to log input and output details. (You probably don’t want to log anything containing sensitive data.) You can hover the little information icons for more details:

These policies are available for the execution activities, meaning most activities except the control activities.
…wait. Policies?
Yep, let me show you! Click the view source code button on the copy data activity:
This opens up the JSON code view for the activity. Here, you can see that these properties are grouped under “policy”:

The fact that they are called policies isn’t really important. However, I wanted to show you an example of things you can find and discover in the JSON code that might not be obvious from the graphical user interface. It may be worth peeking at the code when learning Azure Data Factory to understand things even better.
(Or not. Maybe I’m just weird 😅)
Source and Sink
It’s easy to explain the concept of the source and sink properties. It’s where you specify the datasets you want to copy data from and to. But it’s nearly impossible for me to go through the properties in detail. Why? Because the properties completely depend on the type of dataset and data store you are using.
Here’s an example of four different datasets used as a source:
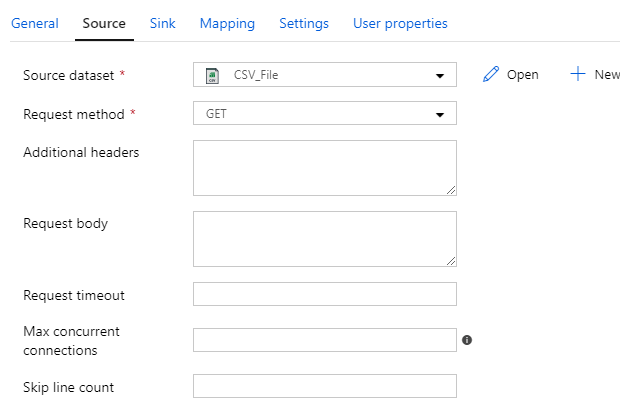
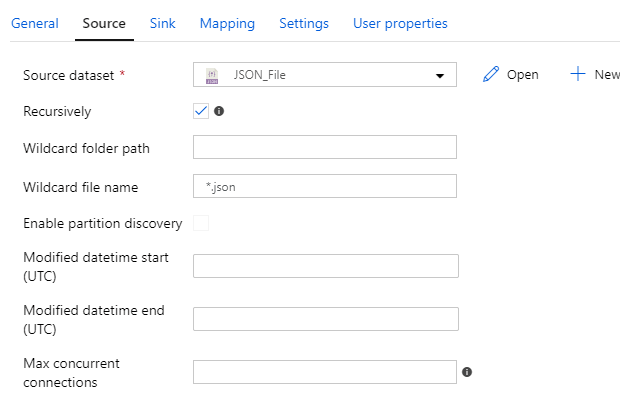
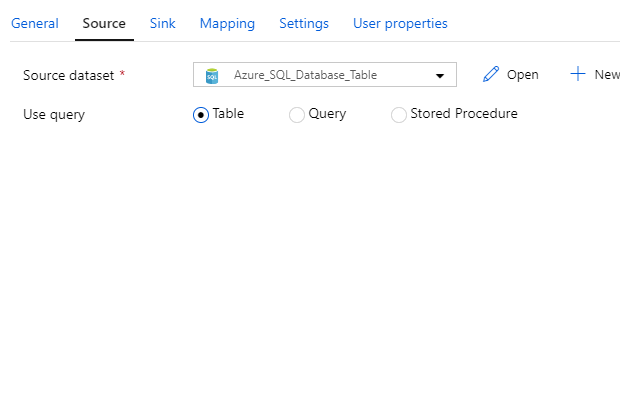
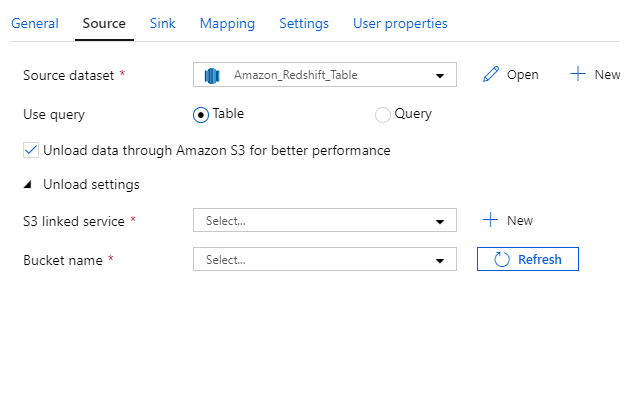
And here’s an example of four different datasets used as a sink:
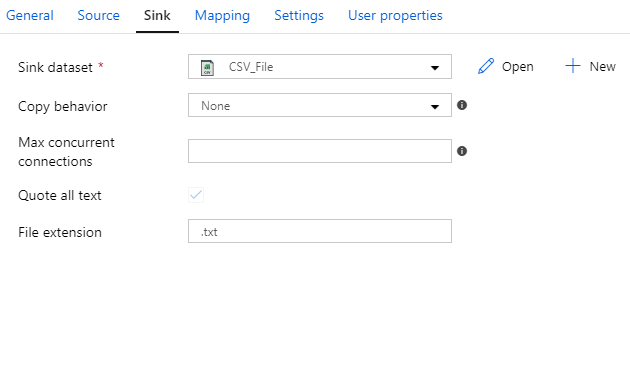
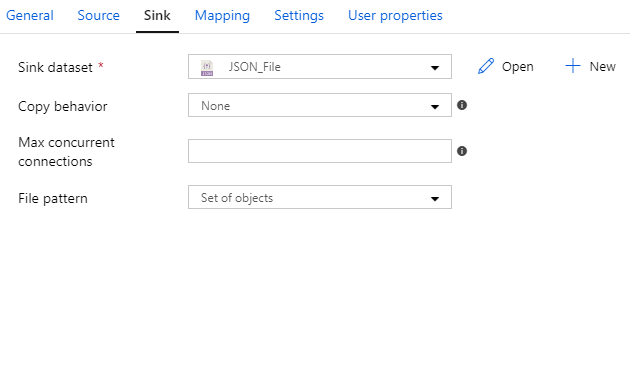
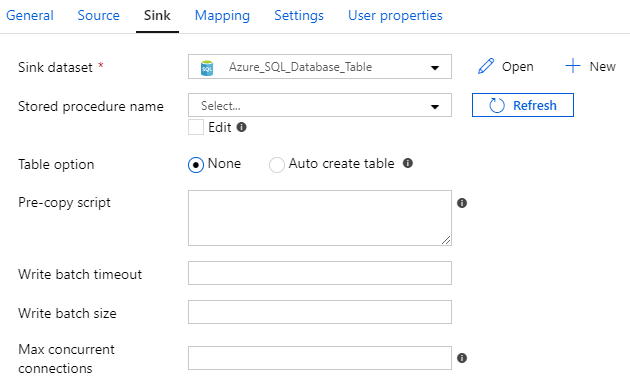
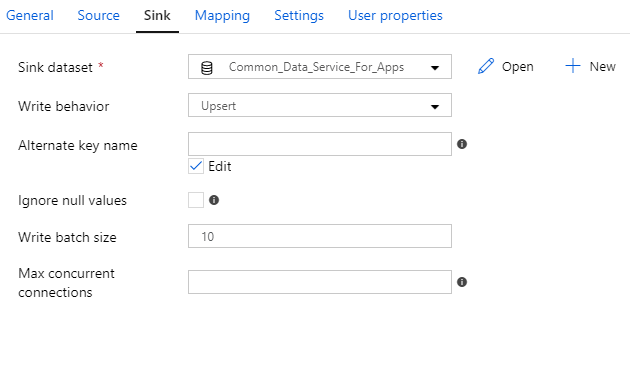
And with over 90 connectors… phew! I don’t even know the details of all the connectors. More importantly, you don’t want me trying to explain ALL THE THINGS. I’m already rambling enough as it is 😄
So! Here’s what I do, and what I recommend you do: Bookmark the Azure Data Factory connector overview. When you use a new dataset or data store, reference that overview, and read up on the details. Then go click and type things in the copy data activity until you configure it the way you need to for your solution. Easy! 😉
Mapping
In the copy data activity, you can map columns from the source to the sink implicitly or explicitly.
Implicit mapping is the default. If you leave the mappings empty, Azure Data Factory will do its best to map columns by column names:
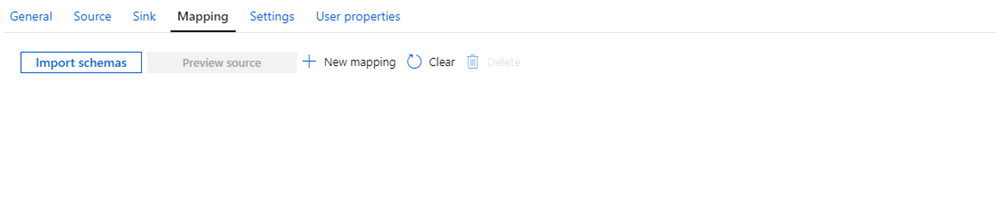
Explicit mapping is when you decide how to map columns from the source to the sink. You have to do this if the source and sink are different:
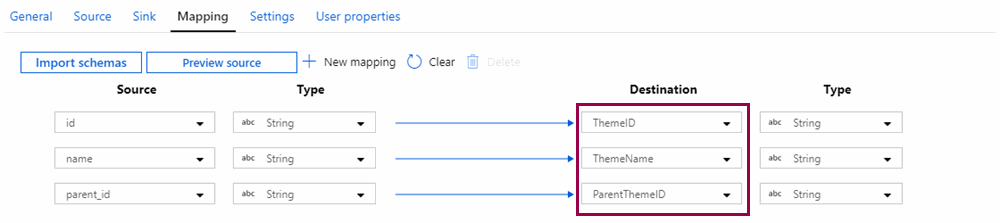
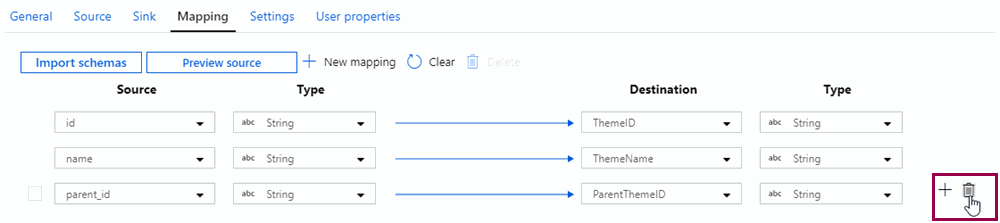
You can also remove mappings, for example if you are copying data to a text file and only want to keep a subset of the columns from the source. Hover over the mapping, and click the delete button that appears next to it:
You can also preview the source dataset:
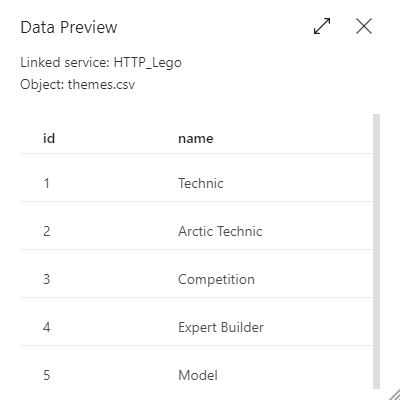
If you have deleted a mapping, the preview will only show you the remaining columns:
You have full control and flexibility when mapping columns from the source to the sink. I still recommend using implicit mapping whenever possible, because you will have one fewer thing to configure and maintain.
(Saving clicks and time, yay! 😁)
Settings
You can adjust the copy data activity settings for data integration units, degree of copy parallelism, fault tolerance, and staging:
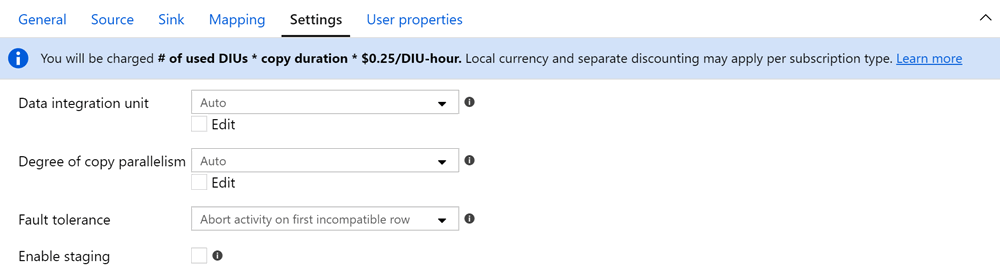
Data Integration Units (DIUs)
Azure Data Factory runs on hardware managed by Microsoft. You can’t configure this hardware directly, but you can specify the number of Data Integration Units (DIUs) you want the copy data activity to use:
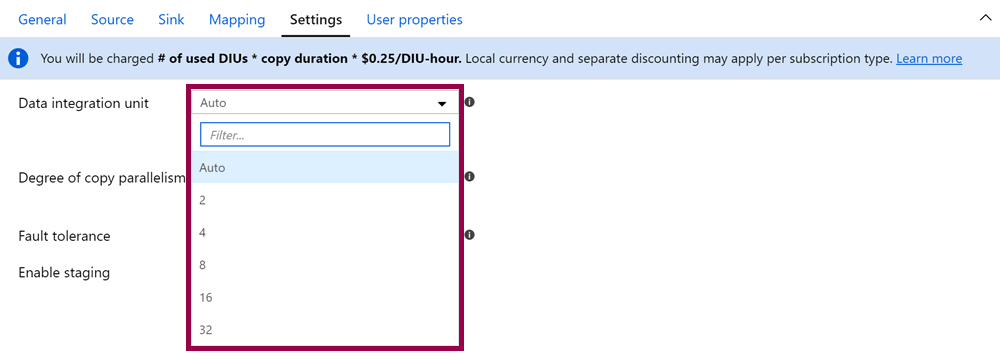
One Data Integration Unit (DIU) represents some combination of CPU, memory, and network resource allocation. I have absolutely no idea what 1 DIU actually is, but it doesn’t really matter. What matters is that the more DIUs you specify, the more power you throw at the copy data activity.
And the more power you throw at the copy data activity, the more you pay for it. (Or for those of us who speak emoji as our second language: 💪 = 💰)
But what number of DIUs is Auto, the default value? Maybe the information button can help:
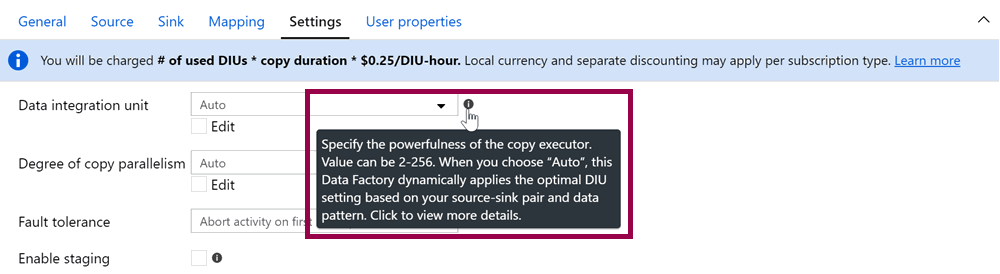
“Value can be 2-256. When you choose ‘Auto’, this Data Factory dynamically applies the optimal DIU setting based on your source-sink pair and data pattern.”
So… if the DIU value is set to Auto, the number of DIUs used starts at 2? Nope. If we click the information button, we are redirected to the official documentation:

If you leave the Data Integration Unit value to Auto, the copy data activity uses a minimum of 4 DIUs.
For larger datasets, this might be optimal! But for smaller datasets, you might be wasting money leaving the setting to Auto. This is why I recommend starting with 2 DIUs, and then scaling up if and when necessary 😊
Degree of Copy Parallelism
The degree of copy parallelism value specifies the maximum number of connections that can read from your source or write to your sink in parallel:
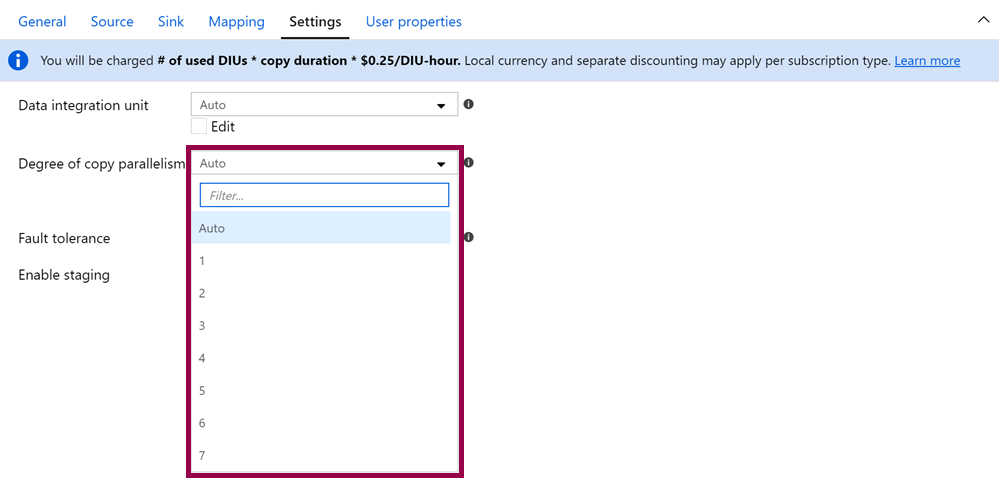
In most cases, I tweak the DIUs, but leave this setting to Auto and let Azure Data Factory decide how to chunk up and copy my data. If I change this value, I usually set it explicitly to 1 to reduce the load on my sources. This could have a huge effect on your solution, though, so make sure you read the documentation and do some testing!
Fault Tolerance
In our example, we set the fault tolerance to “skip and log incompatible rows” in the copy data tool:
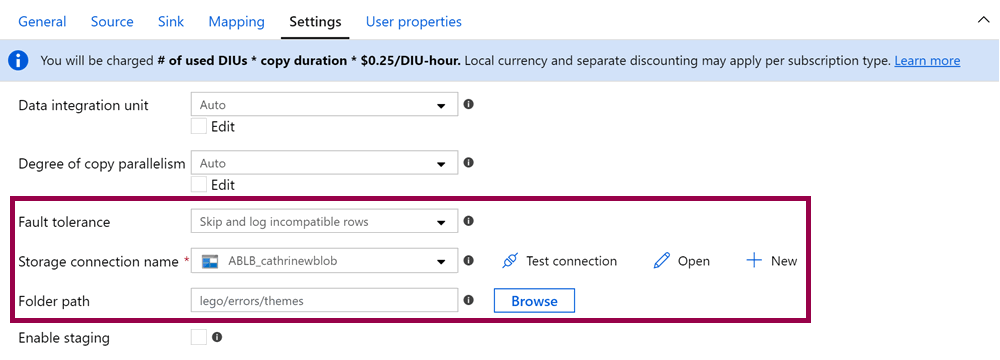
You can also set this to “abort activity on first incompatible row” or “skip incompatible row”. Choose the one that is most appropriate for your use case.
Staging
Alright, this is another interesting feature. One-click staging? Whaaaaat!
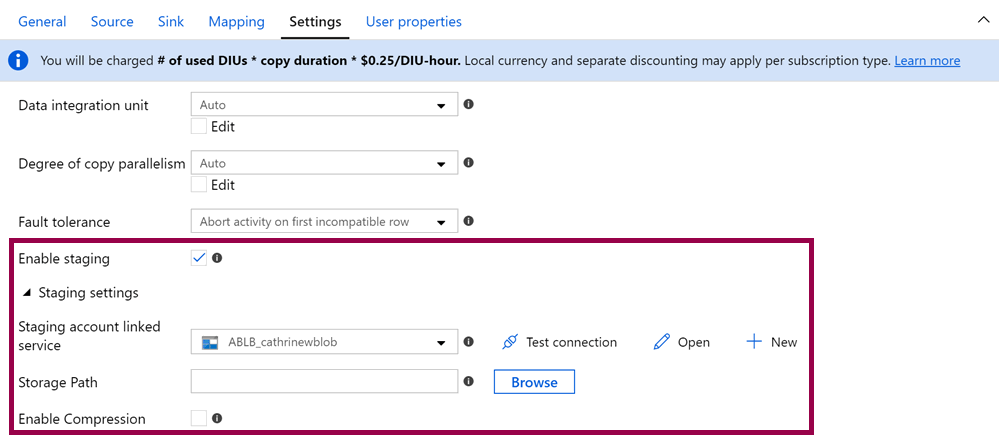
You can enable staging to temporarily store data in blob storage, before loading into the final destination. This is mainly used for optimal loading into Azure Synapse Analytics (formerly Azure SQL Data Warehouse) via PolyBase.
Now, there are two things you need to be aware of here. One, you only store the staging data temporarily. All the staging data is deleted once the copy data activity finishes. If you want to keep the staging data, you need to build your own solution. And two, behind the scenes, this works like using two copy data activities.
You may save time not having to configure a second copy data activity yourself, but you will still pay for that second execution 💰
Copy Data Process
When you copy binary files and other files as-is, the copy data process is fast and simple, like copying files on your computer. You take one file, and copy it into a different location:

However, the copy data activity is powerful. You are not limited to copying files as-is 😃 The copy data activity can do some pretty cool things during copying:

Serialization and deserialization can be explained as converting file formats during copying. For example, we can use a CSV file as a source and copy it into an Azure SQL Database destination. To do that, we need to read the source data in CSV format and transfer it as bits and bytes over the network (serialization), then convert that stream of bits and bytes to a SQL format so we can load it into our database (deserialization).
Similarly, compression and decompression can be explained as zipping and unzipping files during copying. You don’t need to first copy the file and then zip or unzip it. You just specify that the source is zipped and the destination is unzipped, or vice versa.
The cool thing is, you don’t even need to know that these things happen! (Well, I mean, except when you’re reading my post and I call it out because I’m a total geek and I find this interesting…) You don’t need to know what these processes are called or how they work. All you need to do is tell the copy data activity what you want to achieve, and it does the heavy lifting for you. Yay!
Summary
In this post, we looked at the copy data activity, how it works, and how to configure its settings. We also called out a few things that affect the cost, like the number of Data Integration Units (DIUs) and enabling staging.
In the next post, we’re going to look more at our source and sink datasets!
About the Author
 Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓
Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓