Triggers in Azure Data Factory

In the previous post, we looked at testing and debugging pipelines. But how do you schedule your pipelines to run automatically? In this post, we will look at the different types of triggers in Azure Data Factory.
Let’s start by looking at the user interface, and dig into the details of the different trigger types.
Pssst! Triggers have been moved into the management page. I'm working on updating the descriptions and screenshots, thank you for your understanding and patience 😊
Creating Triggers
First, click Triggers. Then, on the linked services tab, click New:
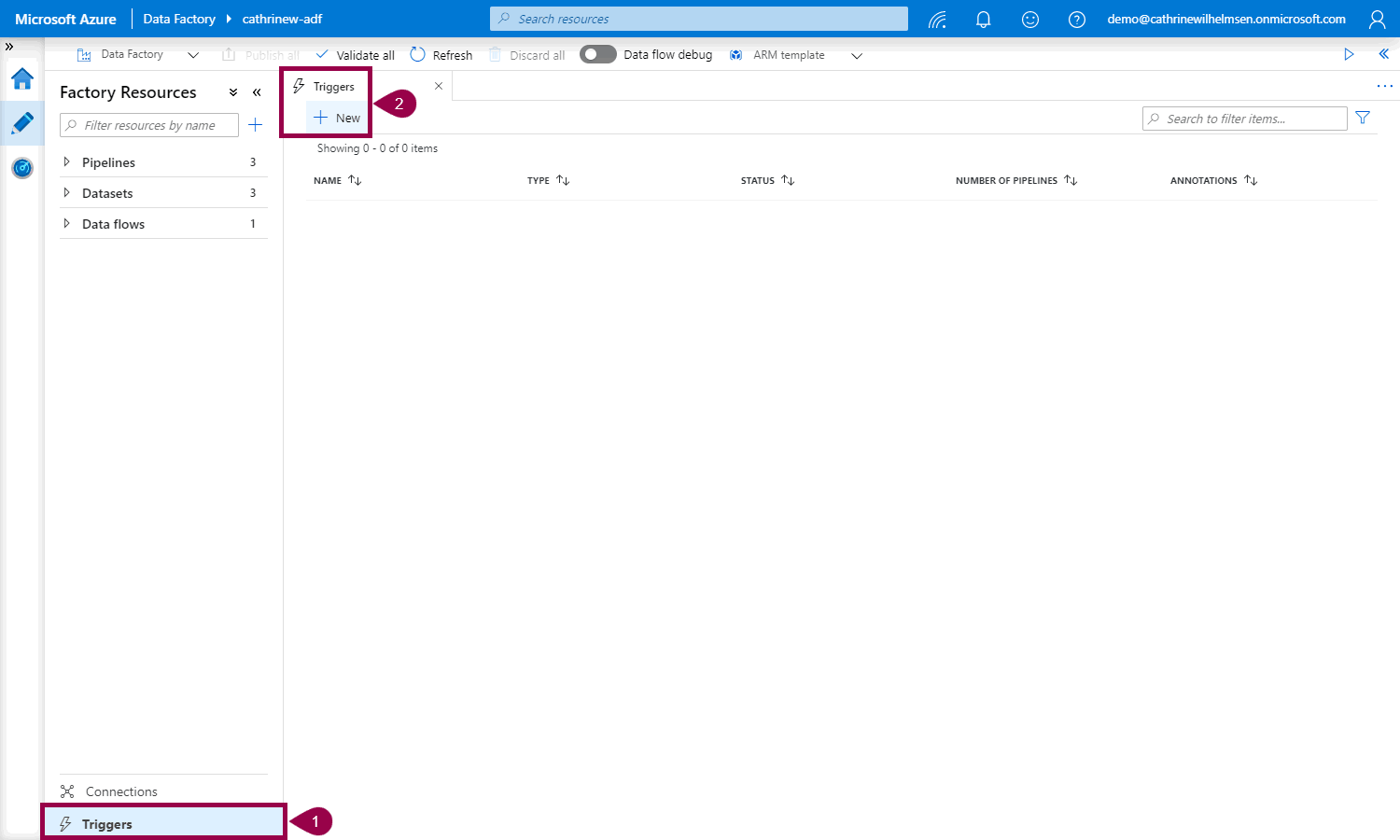
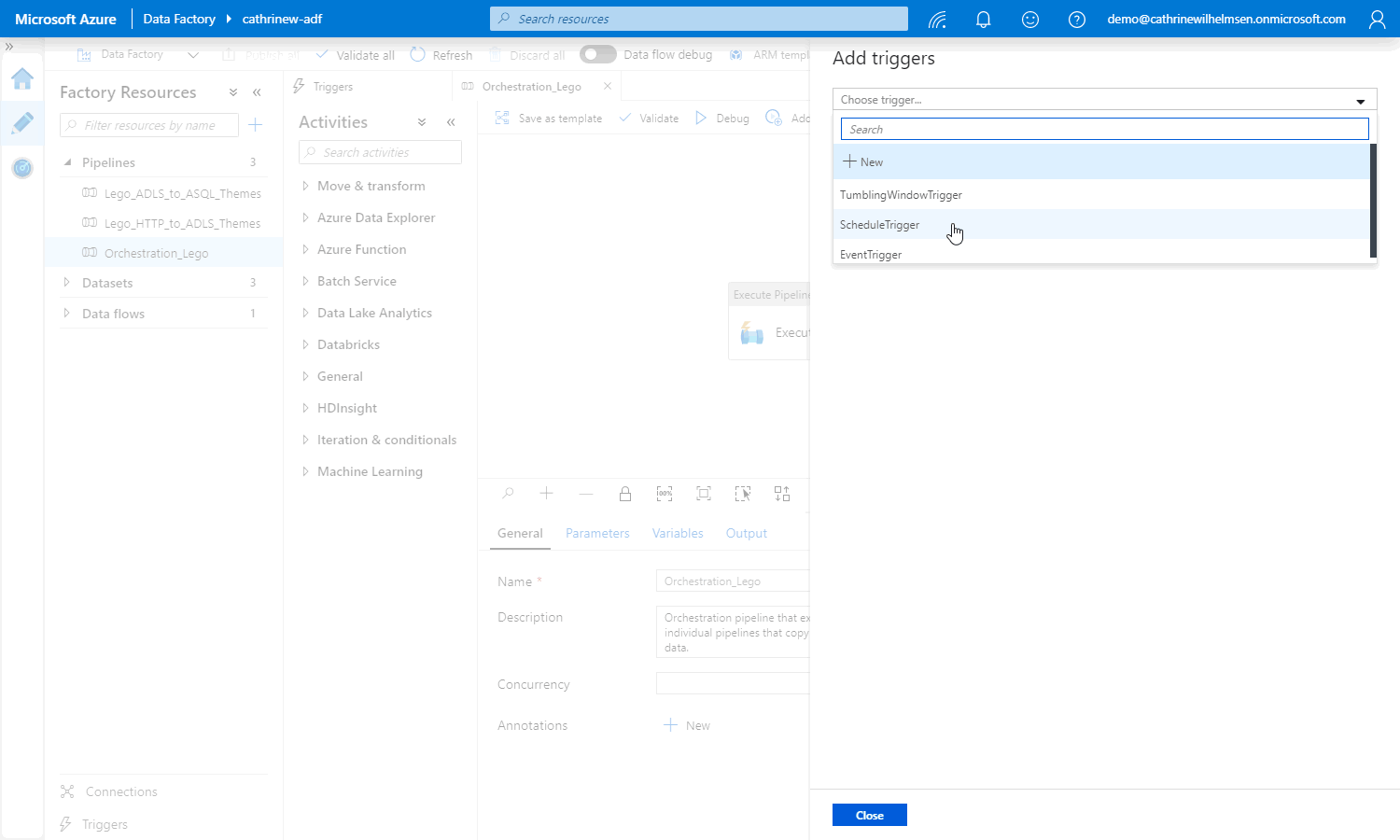
The New Trigger pane will open. The default trigger type is Schedule, but you can also choose Tumbling Window and Event:
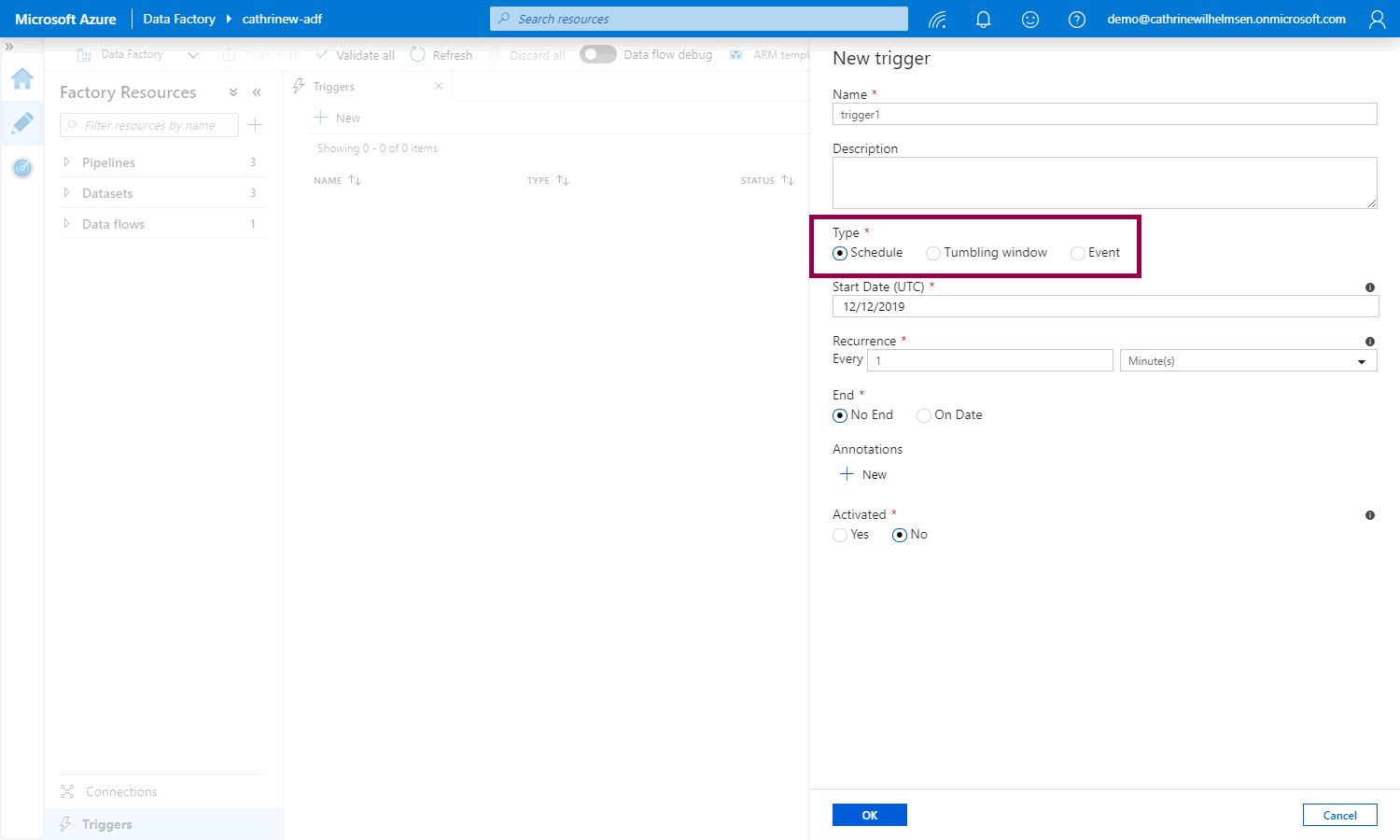
Let’s look at each of these trigger types and their properties!
Schedule Triggers

Schedule triggers can execute one or more pipelines on a set schedule. You have full control and flexibility of the day(s) and time(s) you want to run the trigger, and you can define a start and end date for when the trigger should be active.
You can define a basic recurring schedule, such as:
- Every 2 hours
- Every Sunday at 16:00 UTC and 22:00 UTC
You can also define an advanced calendar schedule, such as:
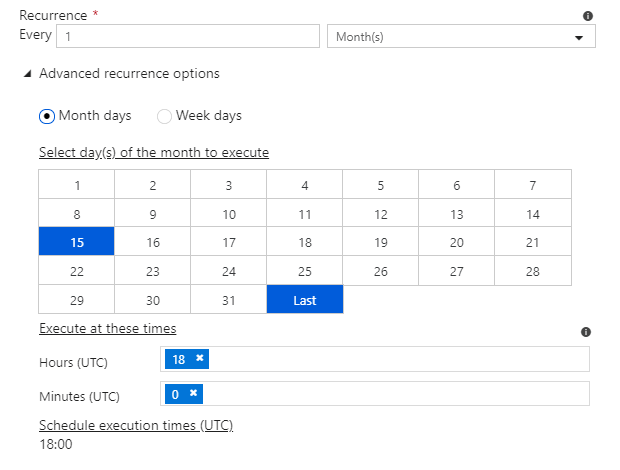
- Every 15th day and last day of the month at 18:00 UTC
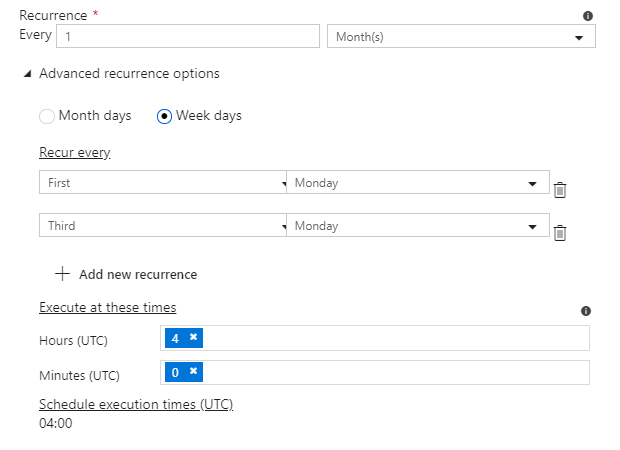
- Every first and third Monday of the month at 04:00 UTC
Schedule triggers and pipelines have a many-to-many relationship. That means that one schedule trigger can execute many pipelines, and one pipeline can be executed by many schedule triggers.
How do I configure a schedule trigger?
Choose the start date, optionally an end date, and whether or not to activate the trigger immediately after you publish it:
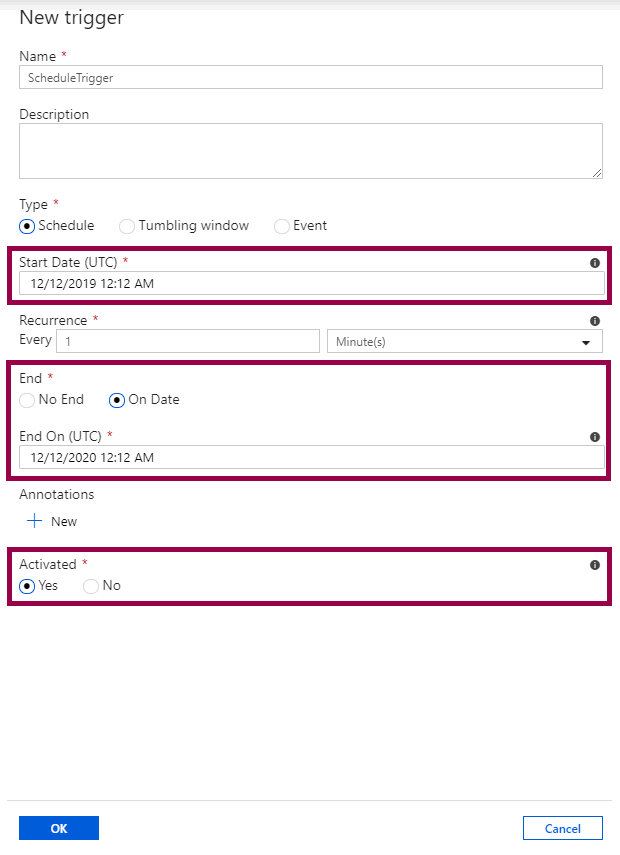
Even if you choose a start time in the past, the trigger will only start at the first future valid execution time after it has been published. (You can find all the details in the official documentation.)
Choose the recurrence, either minutes, hours, days, weeks, or months:
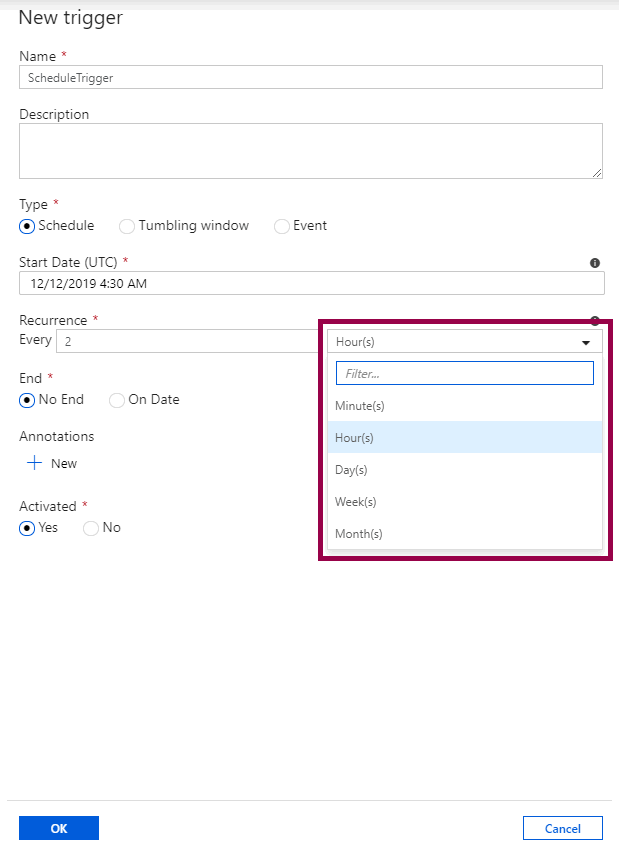
Depending on the recurrence you choose, you can also configure the advanced settings.
If you choose days, you can configure the times:
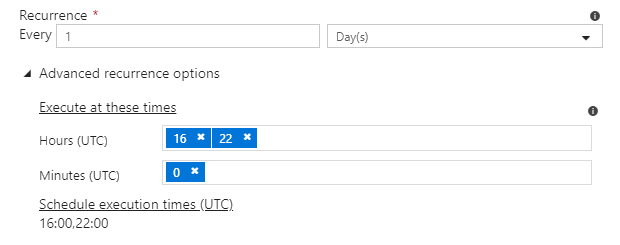
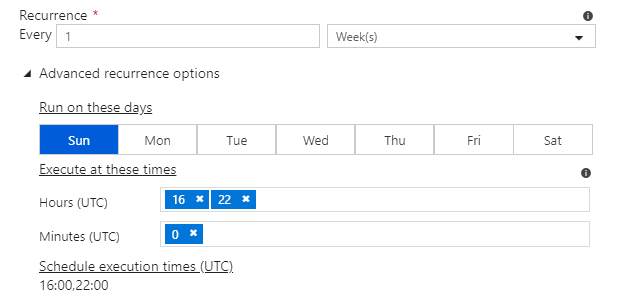
If you choose weeks, you can configure both the days and times:
Months has two options. You can either configure month days and times, such as the 15th day and the last day…
…or week days and times, like the first Monday or the last Sunday:
As you can see, you have full control and flexibility!
And! You don’t even need to figure out the logic to decide what the last day of the month is. Or how to handle leap years. Or which date the second Tuesday of the month is. Thank you, Azure Data Factory 🤩
Tumbling Window Triggers

Tumbling window triggers can execute a single pipeline for each specified time slice or time window. You use them when you need to work with time-based data, do something with each slice of data, and each time slice or time window is the same size.
A common use case is when you want to copy data from a database into a data lake, and store data in separate files or folders for each hour or for each day. In that case, you define a tumbling window trigger for every 1 hour or for every 24 hours. The tumbling window trigger can pass the start and end time for each time window into the database query, which then returns all data between that start and end time. Finally, the data is saved in separate files or folders for each hour or each day.
The cool thing about this is that Azure Data Factory takes care of all the heavy lifting! All you have to do is specify the start time (and optionally the end time) of the trigger, the interval of the time windows, and how to use the time windows. (For example how to use the start and end times in a source query.) Then, for each time window, Azure Data Factory will calculate the exact dates and times to use, and go do the work. This even works for dates in the past, so you can use it to easily backfill or load historical data.
Tumbling window triggers and pipelines have a one-to-one relationship, because of the tight integration between the time windows in the trigger and how they are used in the pipeline.
How do I configure a tumbling window trigger?
Tumbling window triggers have the same settings as schedule triggers for start date, end date, and activation. However, the recurrence setting is different, you can only choose minutes or hours:
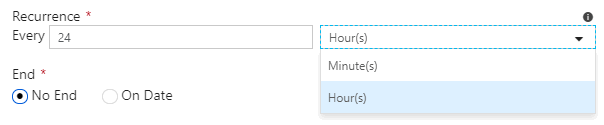
You can also specify several advanced settings:
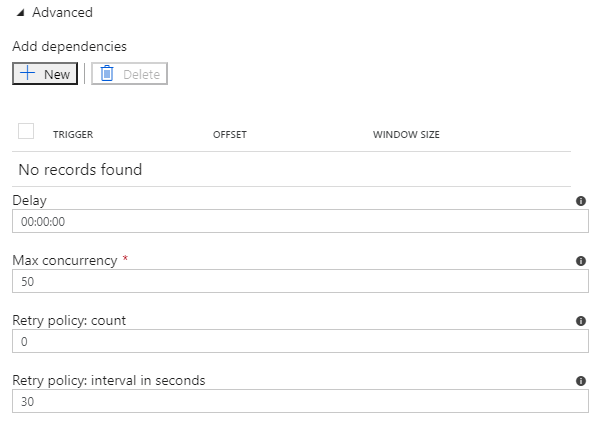
Add dependencies to ensure that the tumbling window trigger only starts after another tumbling window trigger has completed successfully. You can create a self-referencing dependency, to ensure that time windows are always executed sequentially, and not in parallel.
Configure the delay if you want to wait a certain amount of time after the window start time to start executing the pipeline.
If you choose a start time in the past to backfill data, and you don’t configure any self-referencing dependencies, the tumbling window trigger will execute as many time windows as possible in parallel. The default is 50. You can limit the max concurrency to minimize the load on your source system.
Event Triggers

Event triggers can execute one or more pipelines when events happen. (Surprising, huh? 😁) You use them when you need to execute a pipeline when something happens, instead of at specific times.
Event triggers currently only respond to blobs. That means that you can trigger a pipeline when you:
- Create a blob
- Delete a blob
- Create or delete a blob
Event triggers and pipelines have a many-to-many relationship. That means that one event trigger can execute many pipelines, and one pipeline can be executed by many event triggers.
How do I configure an event trigger?
Event triggers do not have settings for start date and end date, but you can choose whether or not to activate the trigger immediately after you publish it. The main settings for event triggers are container and blob path. Blob path can begin with a folder path and/or end with a file name or extension:
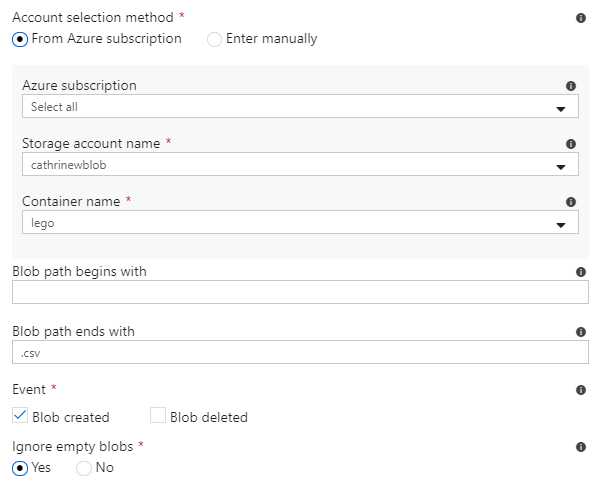
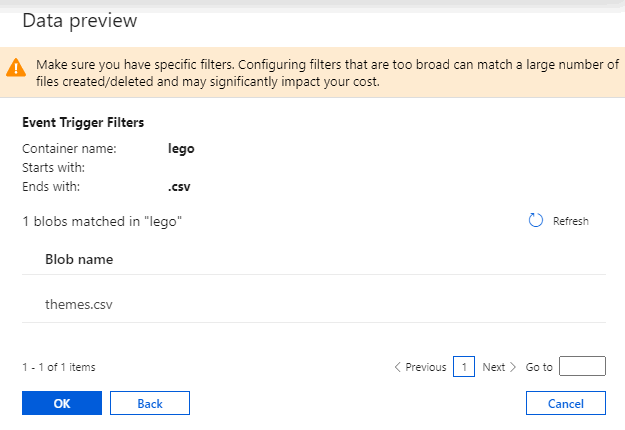
Once you select a path, you can confirm that it has been configured correctly from the data preview page:
Trigger Now

Trigger now isn’t really a trigger type, it’s more like a trigger action. You can manually trigger a pipeline, just like debugging pipelines. After you have triggered a pipeline, you can to open up the Monitor page to check the status and see the output.
Adding triggers to pipelines
Once you have created your triggers, open the pipeline that you want to trigger. From here, you can trigger now or click add trigger, then New/Edit:
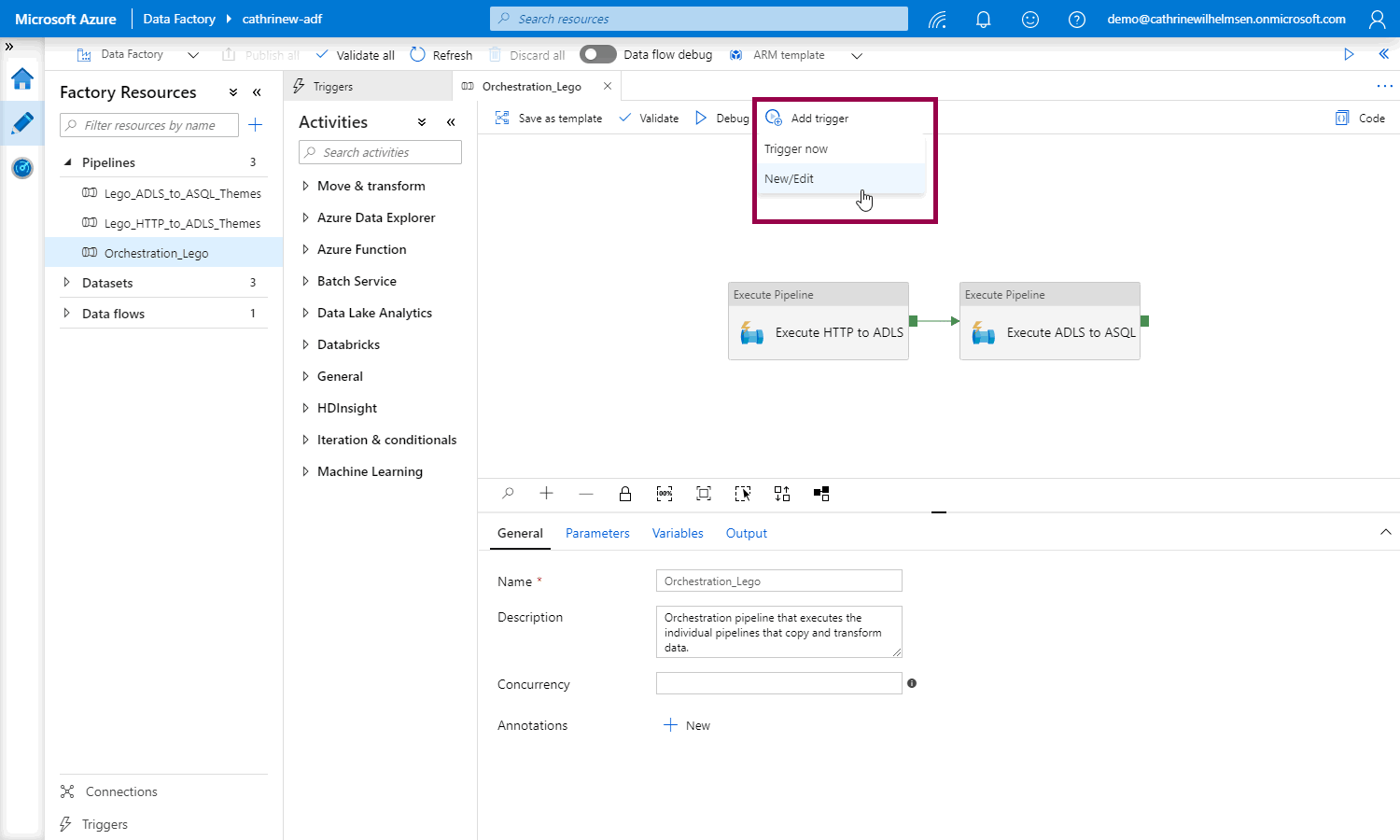
This opens the add triggers pane, where you can select the trigger:
In the triggers tab, you can now see that the trigger has a pipeline attached to it, and you can click to activate it:
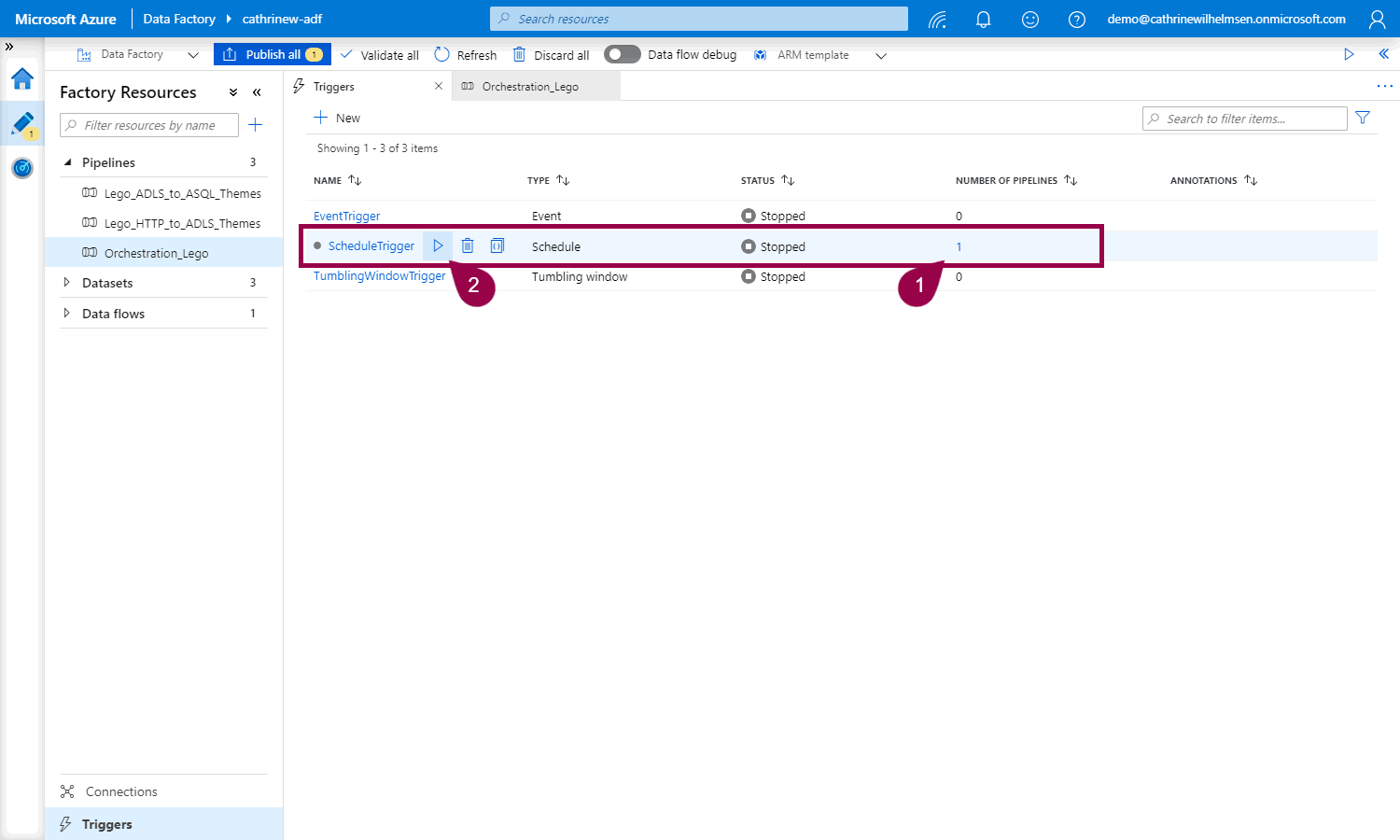
Remember to publish 😊
Summary
In this post, we looked at schedule triggers, tumbling window triggers, event triggers, and how to trigger pipelines on-demand.
In the next post, we will look at monitoring pipelines after they have been triggered.
About the Author
 Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓
Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓