Orchestrating Pipelines in Azure Data Factory

In the previous post, we peeked at the two different data flows in Azure Data Factory, then created a basic mapping data flow. In this post, we will look at orchestrating pipelines using branching, chaining, and the execute pipeline activity.
Let’s continue where we left off in the previous post. How do we wire up our solution and make it look something like this?
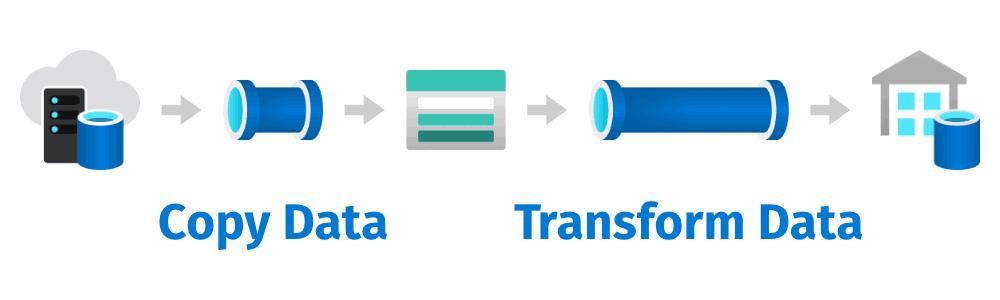
We need to make sure that we get the data before we can transform that data.
One way to build this solution is to create a single pipeline with a copy data activity followed by a data flow activity. But! Since we have already created two separate pipelines, and this post is about orchestrating pipelines, let’s go with the second option 😎
Orchestrating Pipelines using Execute Pipeline Activities

The preferred way to build this solution is by creating an orchestration pipeline with two execute pipeline activities. This gives us a little more flexibility than having a single pipeline, because we can execute each pipeline separately if we want to.
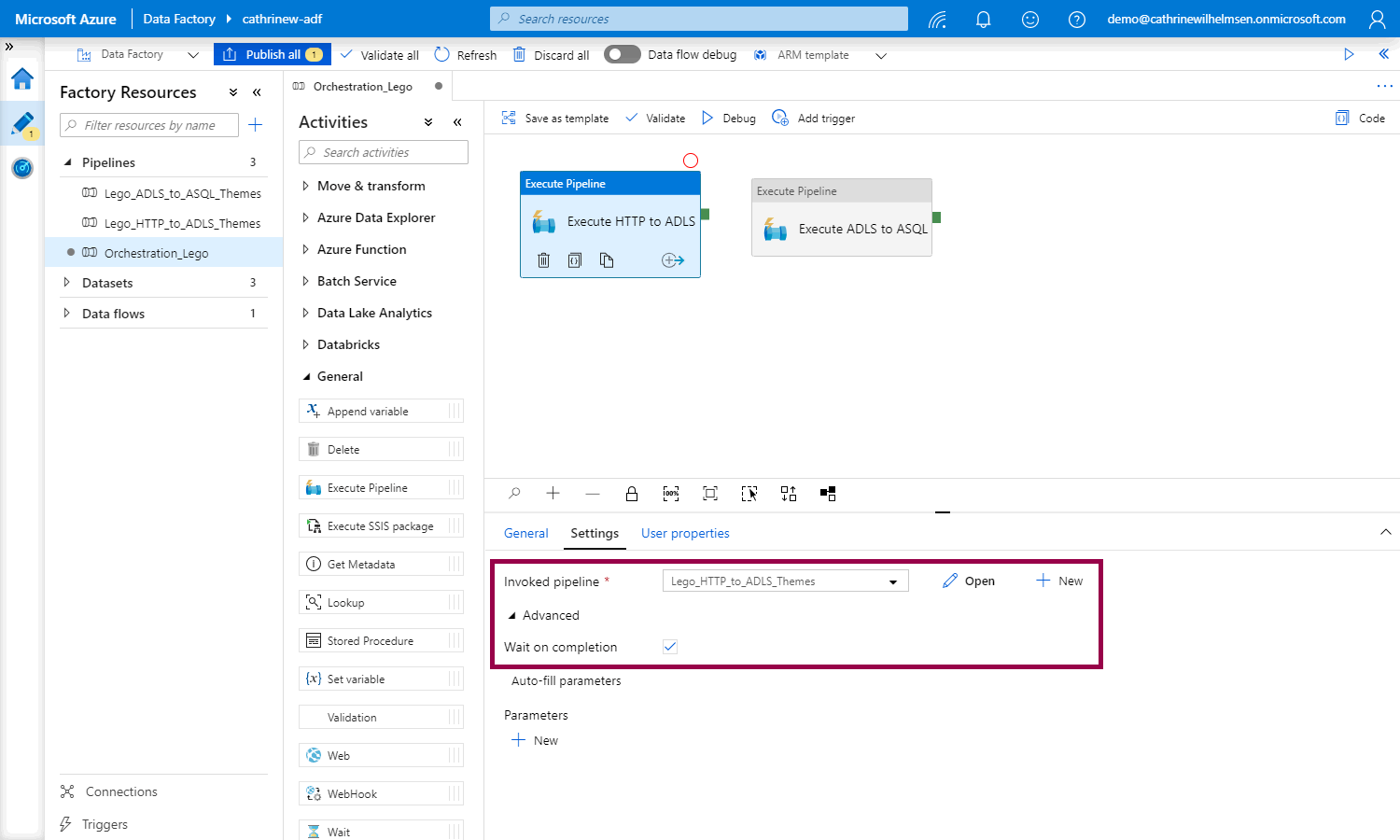
Let’s start by creating a new pipeline and adding two execute pipeline activities to it. In the activity settings, select the pipelines to execute, and check wait on completion:
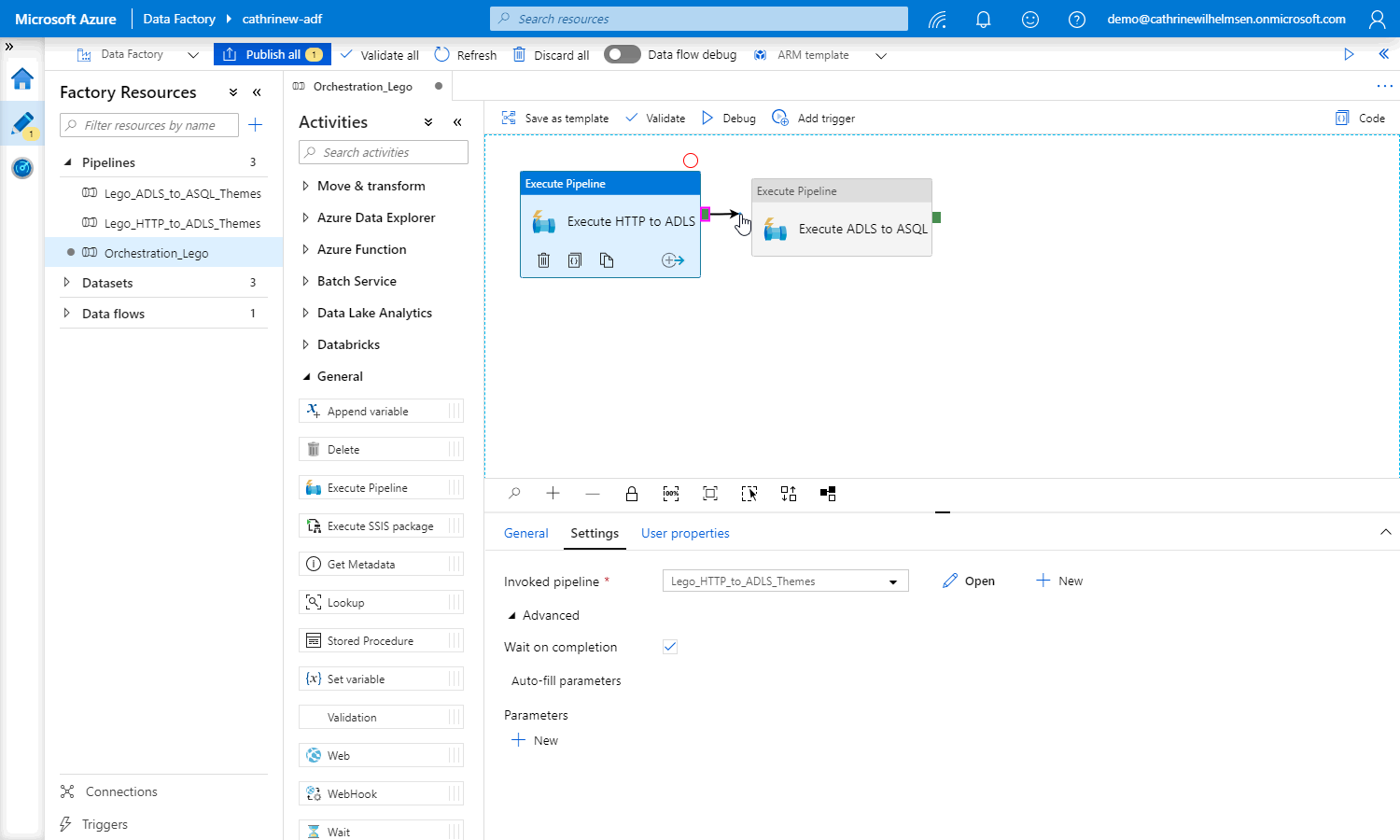
Then, create a dependency between the two execute pipeline activities by clicking the green handle on the right side of the first activity and dragging it onto the second activity:
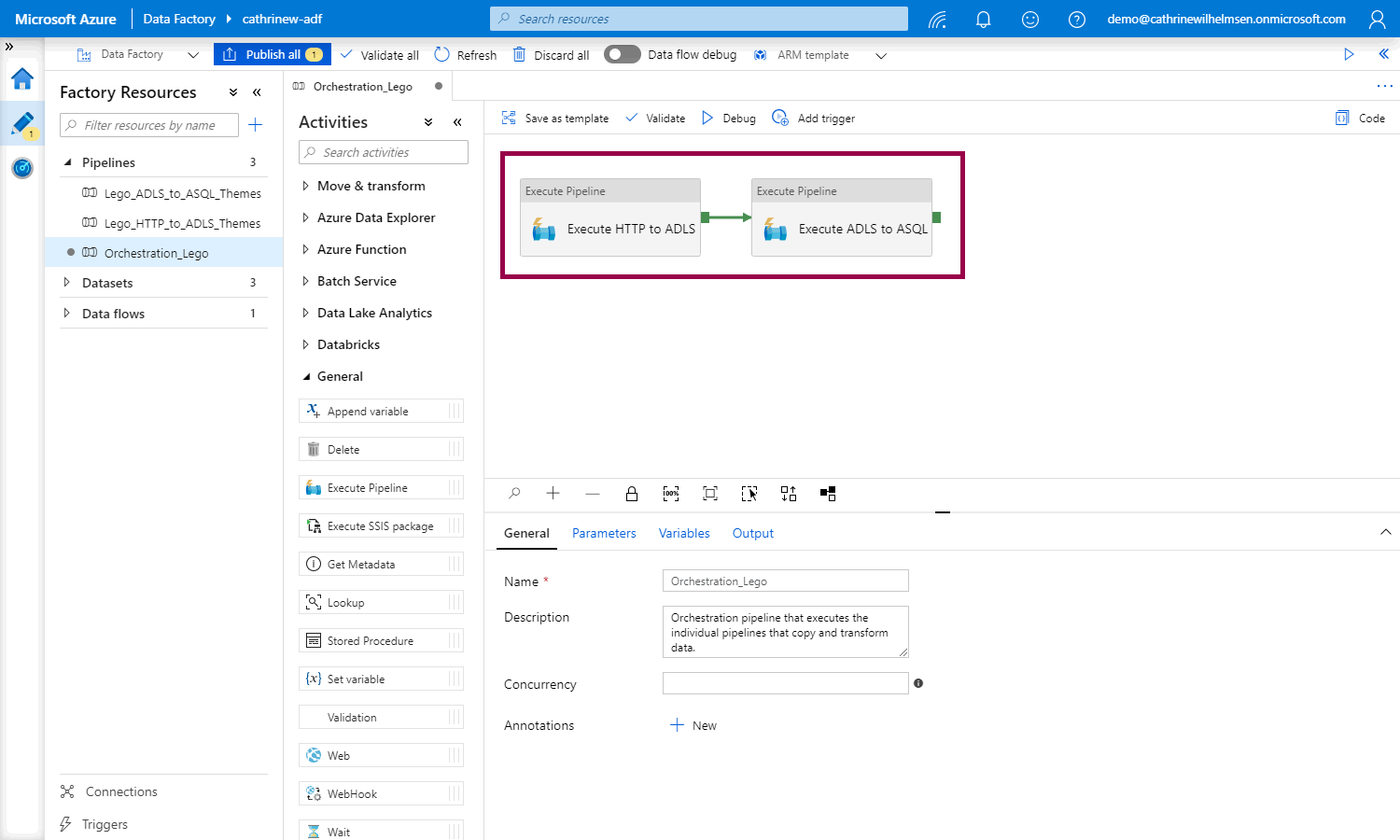
You will now execute the two pipelines sequentially:
When Should I Wait on Completion?
The execute pipeline activity can behave in two ways. The default behavior is to not wait on completion. In this case, the activity will start executing the pipeline. As soon as the pipeline has been started, the activity will go “alright, I pressed play, the pipeline has started, my job here is done!” and report success. In this case, success means that the pipeline was successfully started.
If you choose to wait on completion, the activity will start executing the pipeline, and then wait until the pipeline is completed. If the pipeline fails, the activity will go “oh no, the pipeline failed, now I shall fail too!” and report failure. If the pipeline succeeds, the activity will go “cool cool, the pipeline succeeded, my job here is done!” and report success. In this case, success means that the pipeline was successfully completed.
Activity Dependencies
By default, you will only see the success output on activities. You can add more outputs by clicking the add output button:
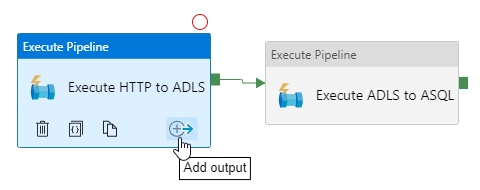
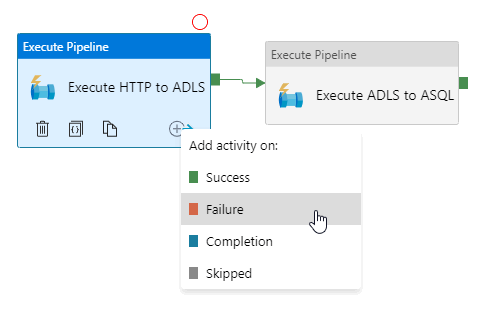
This will open up the output menu showing the four types of outputs you can add to an activity:
Success
The green handles and arrows visualize the success output:
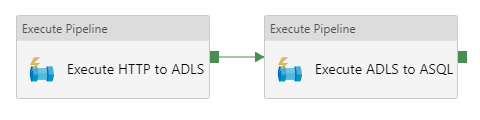
When you add a success dependency, the second activity will only be executed if the first activity succeeds.
Failure
The red handles and arrows visualize the failure output:
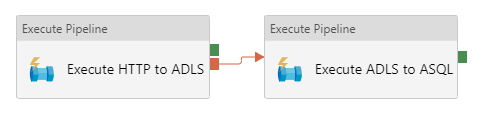
When you add a failure dependency, the second activity will only be executed if the first activity fails.
Completion
The blue handles and arrows visualize the completion output:
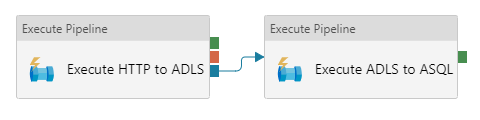
When you add a completion dependency, the second activity will be executed when the first activity completes, regardless of its status.
Skipped
The gray handles and arrows visualize the skipped output:
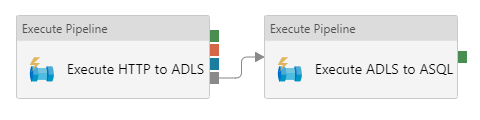
When you add a skipped dependency, the second activity will only be executed if the first activity isn’t executed.
…are you confused about the skipped output? I was! So I made a test for myself 😊
Multiple Dependencies
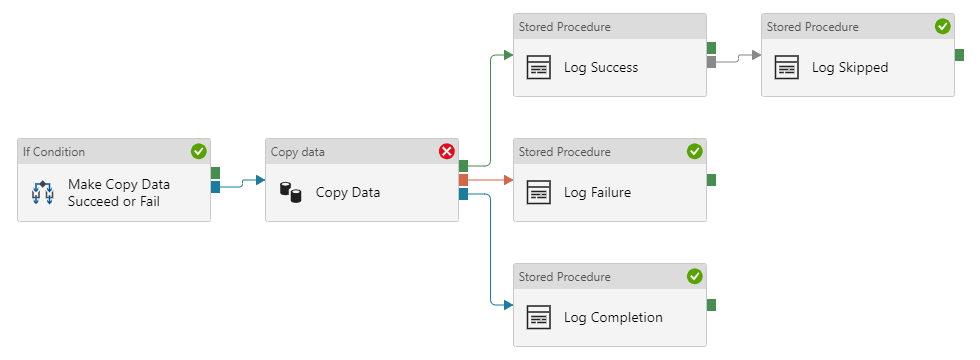
To test the activity dependencies, I created a slightly more complex pipeline. Oh, and I threw in some additional features that aren’t strictly necessary to test the dependencies, just to make it a little more complex. You know, for science 👩🏼🔬
In this pipeline, I can make the copy data activity succeed (by copying a file that exists) or fail (by trying to copy a file that doesn’t exist). I then log the output statuses to a table in my database. Can you guess what happens when the copy data activity succeeds, and what happens when it fails?
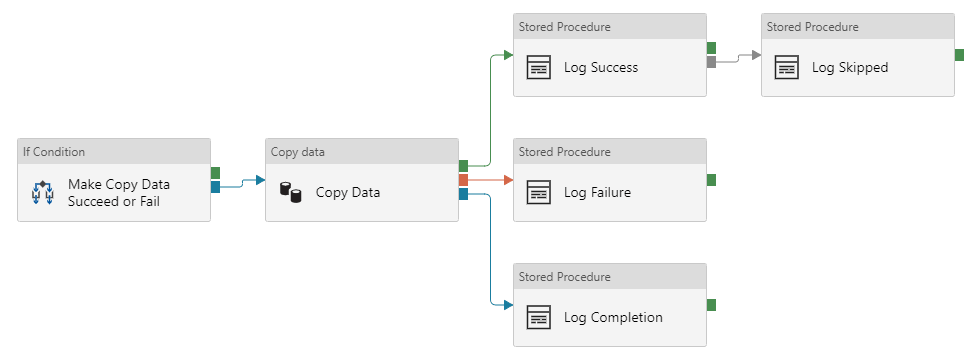
When the copy data activity succeeds, we log both success and completion:
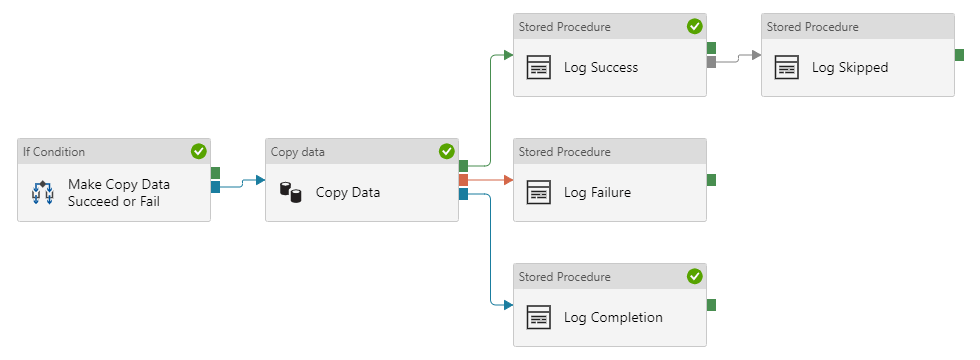
When the copy data activity fails, we log failure, completion, and skipped. In this case, the “log skipped” activity runs because the “log success” activity didn’t run, because the copy data activity didn’t succeed:
Summary
In this post, we looked at orchestrating pipelines using branching, chaining, and the execute pipeline activity. We created a pipeline that executes two other pipelines, and looked at the different activity dependencies.
While my examples work for small projects, you may need a different strategy for larger projects. Paul Andrew (@mrpaulandrew) has a great blog post about his pipeline hierarchy design pattern. He uses the concept of grandparent, parent, child, and infant. Once you start scaling out your project, this is an excellent resource!
Finally, there is a big gotcha when it comes to activity dependencies… Meagan Longoria (@MMarie) has explained this gotcha in her excellent blog post Activity Dependencies are a Logical AND. Once you start building more complex pipelines, make sure you understand how this works, then test your pipelines thoroughly.
And speaking of testing… how do you test your pipelines? We’ll look at debugging pipelines next!
About the Author
 Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓
Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓