Datasets in Azure Data Factory

In the previous post, we looked at the copy data activity and saw how the source and sink properties changed with the datasets used. In this post, we will take a closer look at some common datasets and their properties.
Let’s start with the source and sink datasets we created in the copy data wizard!
Dataset Names
First, a quick note. If you use the copy data tool, you can change the dataset names by clicking the edit button on the summary page…
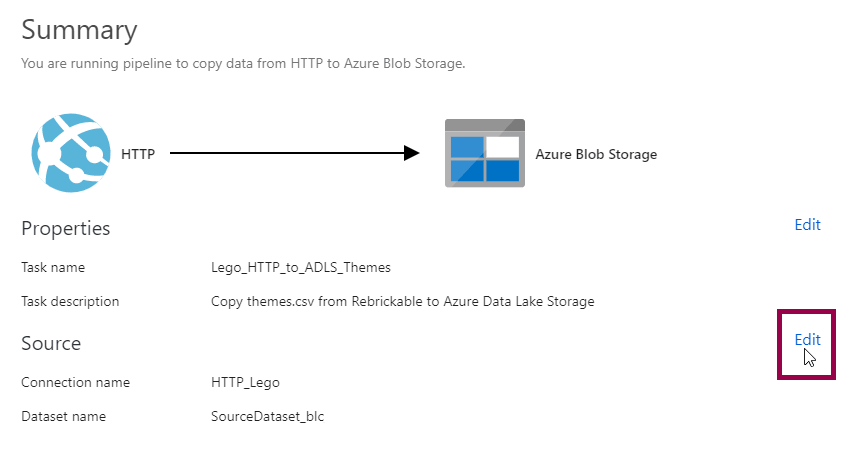
…then renaming the dataset to something more descriptive:
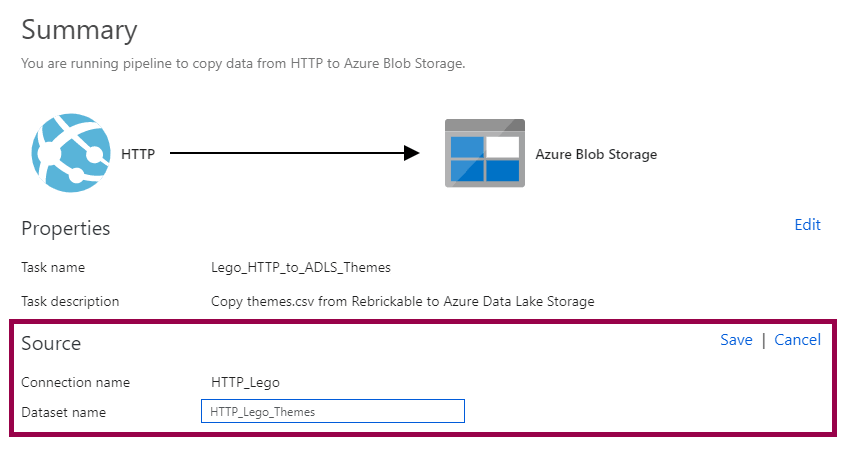
This step can be easy to miss, though. I think I used the copy data wizard like ten times before I noticed this :) If you’re like me, and you miss the edit button, you will end up with datasets using the default naming pattern of “SourceDataset” and “DestinationDataset”:
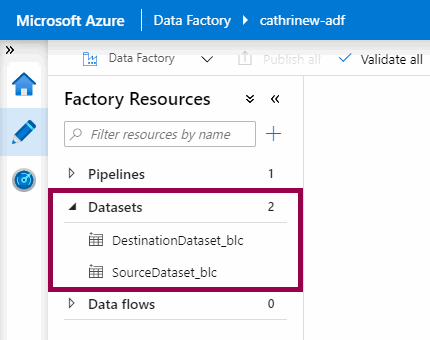
But… please, please, please don’t use “source” or “destination” or “sink” or “input” or “output” or anything like that in your dataset names. It makes sense when you have one pipeline with one copy data activity, but as soon as you start building out your solution, it can get messy. Because what if you realize you want to use the original destination dataset as a source dataset in another copy data activity? Yeah… 🤪
So! Let’s rename the datasets. Open, rename, then publish:
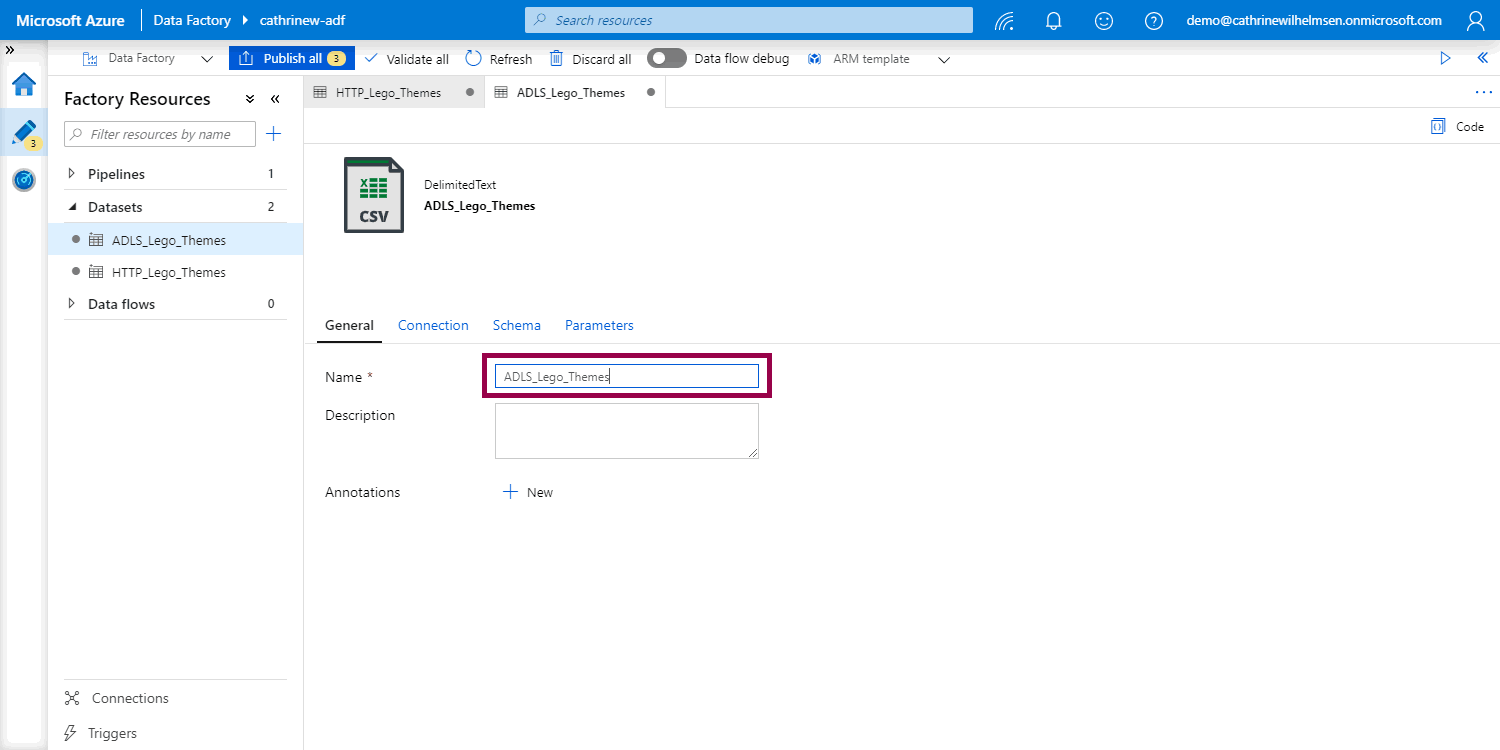
Aaaaah, much better 😊 I like to prefix my datasets with the connection type. Depending on the solution, I add the data type as well. In this case, I chose HTTP_Lego_Themes and ADLS_Lego_Themes as my dataset names. If I also had JSON versions of the files, I would have used something like HTTP_CSV_Lego_Themes and ADLS_CSV_Lego_Themes instead. Again, choose names that make sense to you!
Oh, one last thing before we look at the dataset properties. Remember all the things you could do to create and organize pipelines? You can do the same to create and organize datasets, using the action menus:
Dataset Connections
Since we are working with two CSV files, the connections are very similar. In both datasets, we have to define the file format. The difference is how we connect to the data stores.
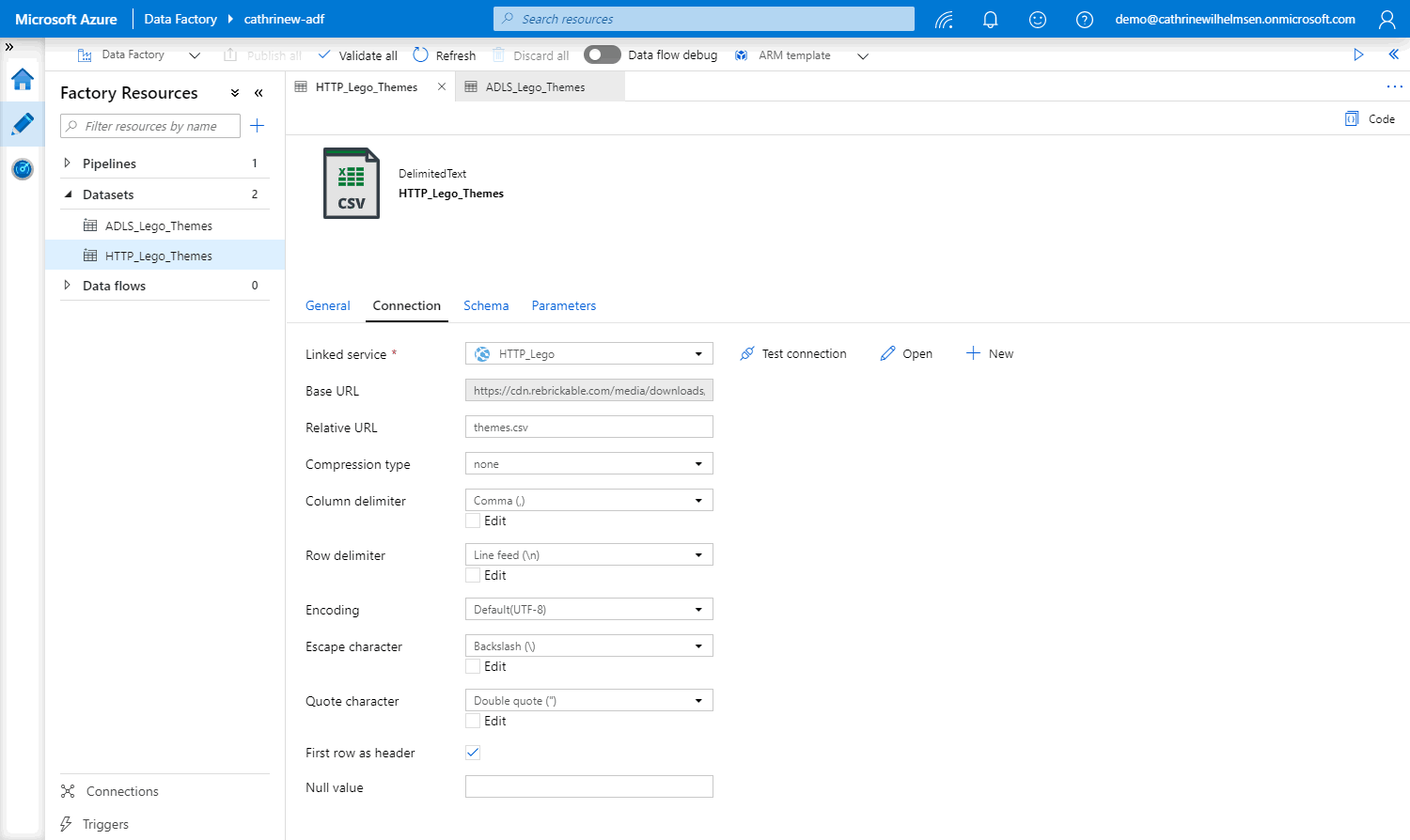
In the HTTP connection, we specify the relative URL:
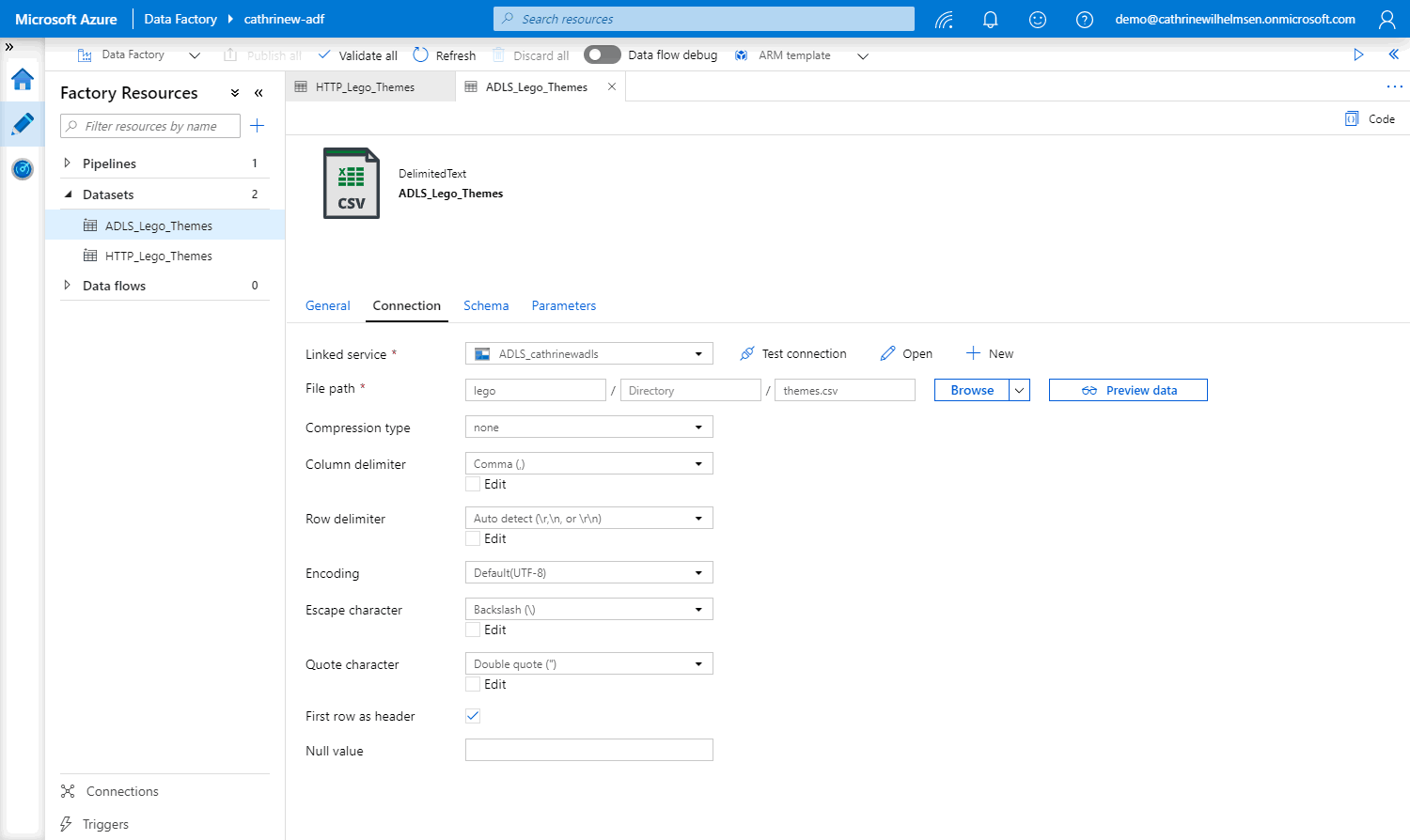
In the ADLS connection, we specify the file path:
Other dataset types will have different connection properties. We’ll look at a different example a little further down.
Dataset Schemas
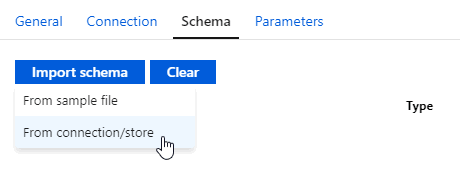
In some datasets, you can specify the schema. You can import the definition from the actual data, or you can upload a definition from a sample file (if the actual data doesn’t exist or you don’t have access to the data source yet):
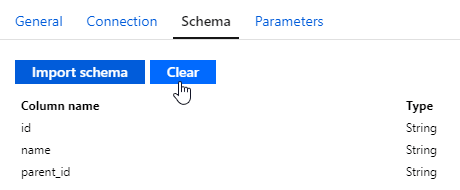
Once the schema has been imported, you can see the column names and types:

However, just like I recommended using implicit mapping whenever possible in the copy data activity, I recommend not specifying schemas unless you need to. The fewer things I have to configure and maintain, the better :) You can clear the schema if it has already been defined:
And! Some datasets don’t even have schema properties. For example, for an Amazon Redshift table, you only specify the connection:

Database Datasets… or Queries?
So far, we’ve looked at file datasets. But what about database datasets? In some ways, they’re much simpler than file datasets. You choose a table:
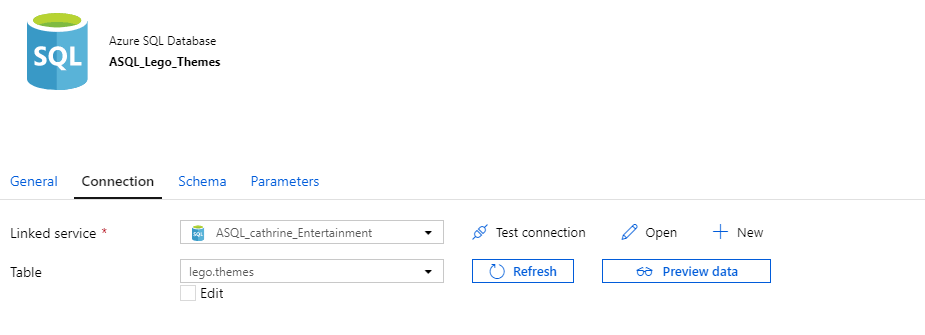
Or you can specify a table:
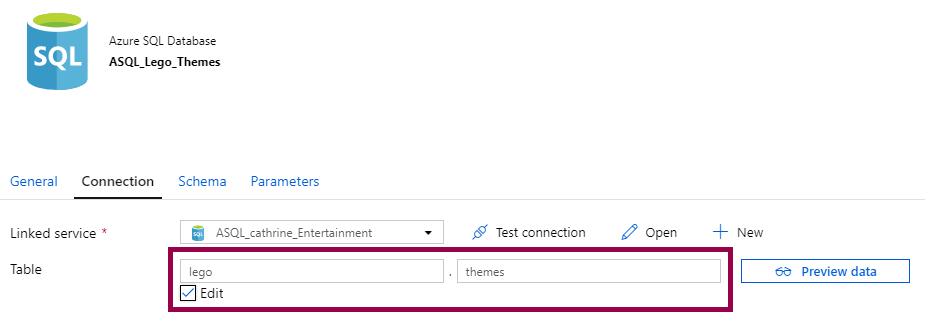
A database dataset is simple. How you use it can be slightly confusing, though. At least it was for me. The reason for that is that you don’t need to use the dataset at all, even when you use that dataset.
…wait, what?
Yeah, exactly 😂
Ok, to explain this, we need to hop back to the copy data activity for a little bit. If you use a database dataset as a source, you have three options. Table, query, or stored procedure:
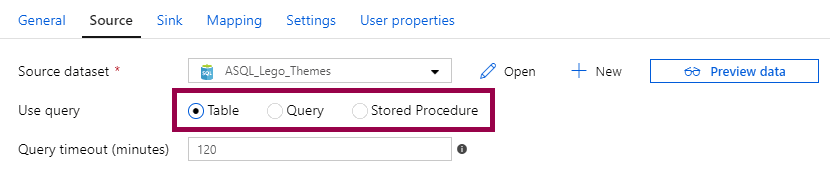
If you choose table, you will connect to the table you chose or specified in the dataset. In this case, you are using the dataset directly.
However, if you choose query or stored procedure, you can override the dataset.
For example, I can write a query to get a subset of the dataset. Or! I can query a completely different table:
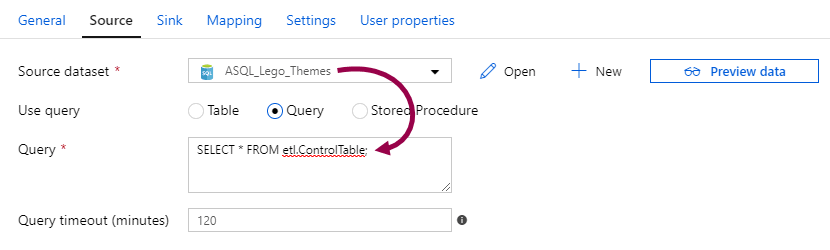
In the example above, I’m using the ASQL_Lego_Themes dataset, which connects to the lego.themes table. But I’m querying the etl.ControlTable! I’m using the dataset without using the dataset.
In this case, the dataset is only used as a bridge to the linked service, because the copy data activity can’t connect to the linked service directly. By using queries or stored procedures in the copy data activity, you only need to create one dataset to connect to the linked service, instead of creating one dataset for each table. A little confusing at first, maybe, but very flexible!
Summary
In this post, we went through the source and sink datasets we previously created. We also looked at how database datasets can be used as a bridge to linked services.
And on that note… let’s look at linked services next!
About the Author
 Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓
Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓