Pipelines in Azure Data Factory

In the previous post, we used the Copy Data Tool to copy a file from our demo dataset to our data lake. The Copy Data Tool created all the factory resources for us: pipelines, activities, datasets, and linked services.
In this post, we will go through pipelines in more detail. How do we create and organize them? What are their main properties? Can we edit them without using the graphical user interface?
How do I create pipelines?
So far, we have created a pipeline by using the Copy Data Tool. There are several other ways to create a pipeline.
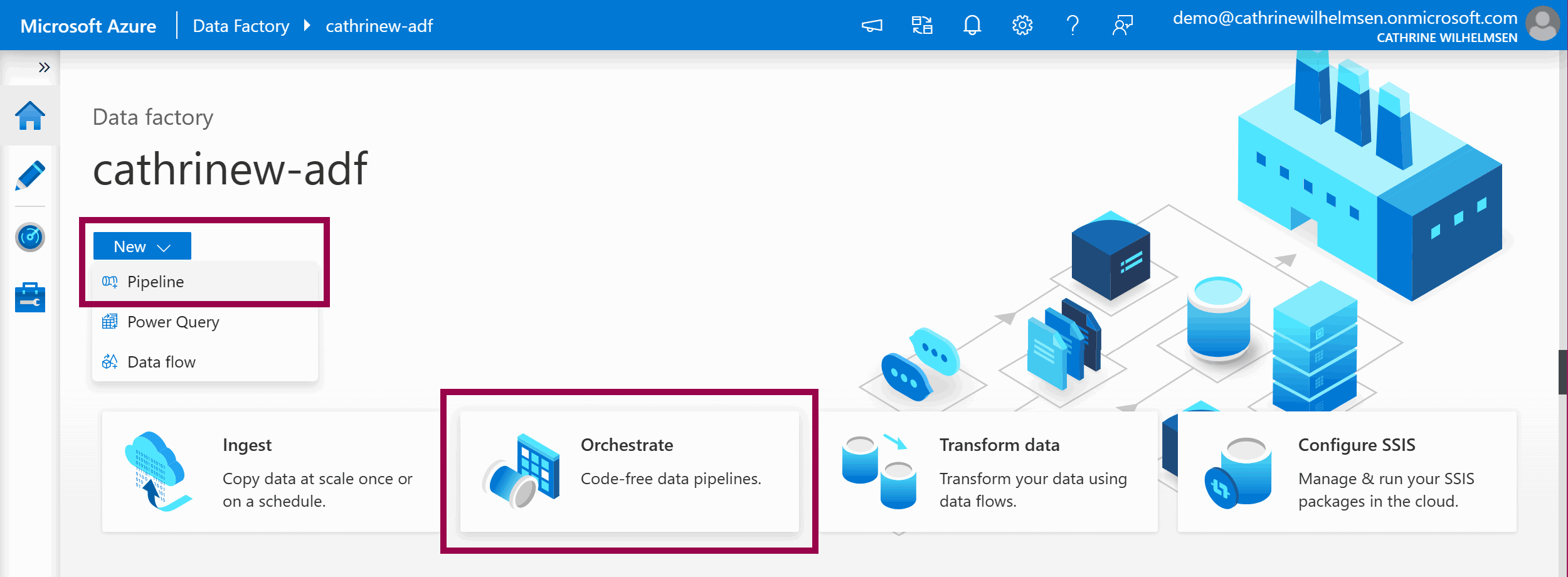
On the Home page, click on the New → Pipeline dropdown menu, or click on the Orchestrate shortcut tile:
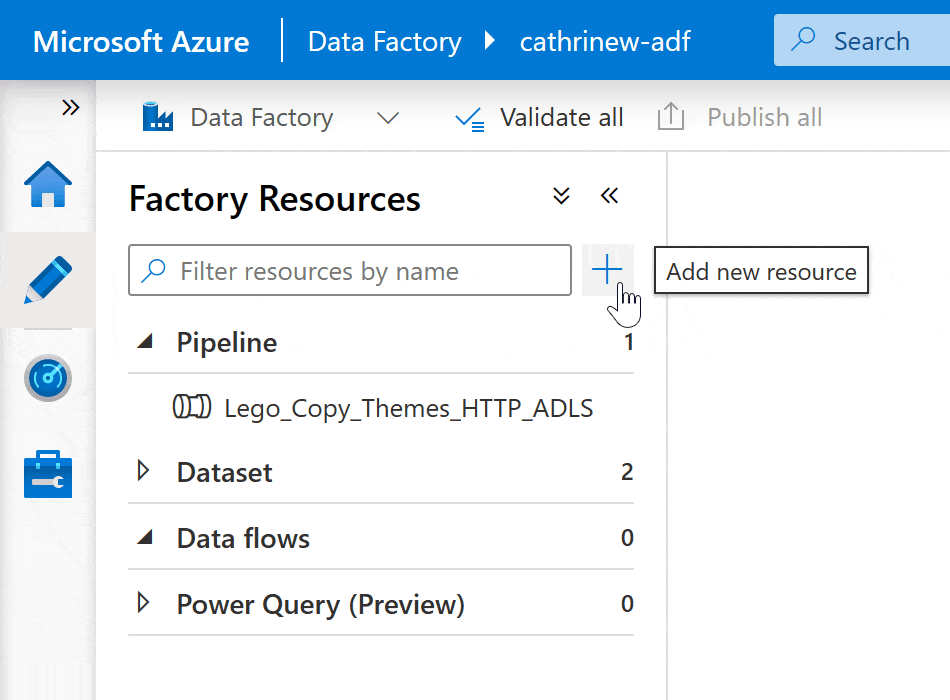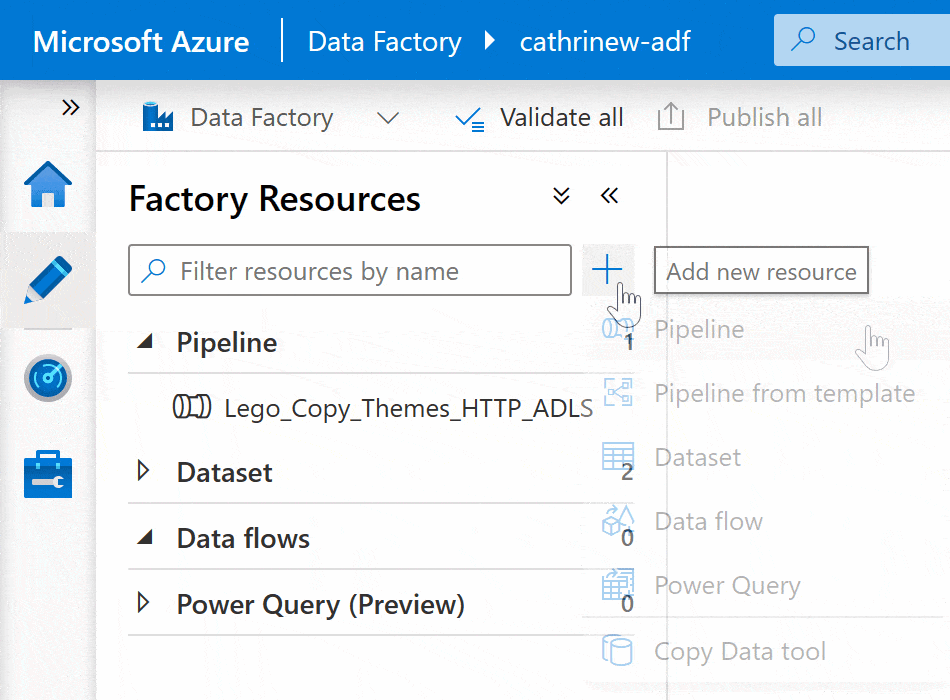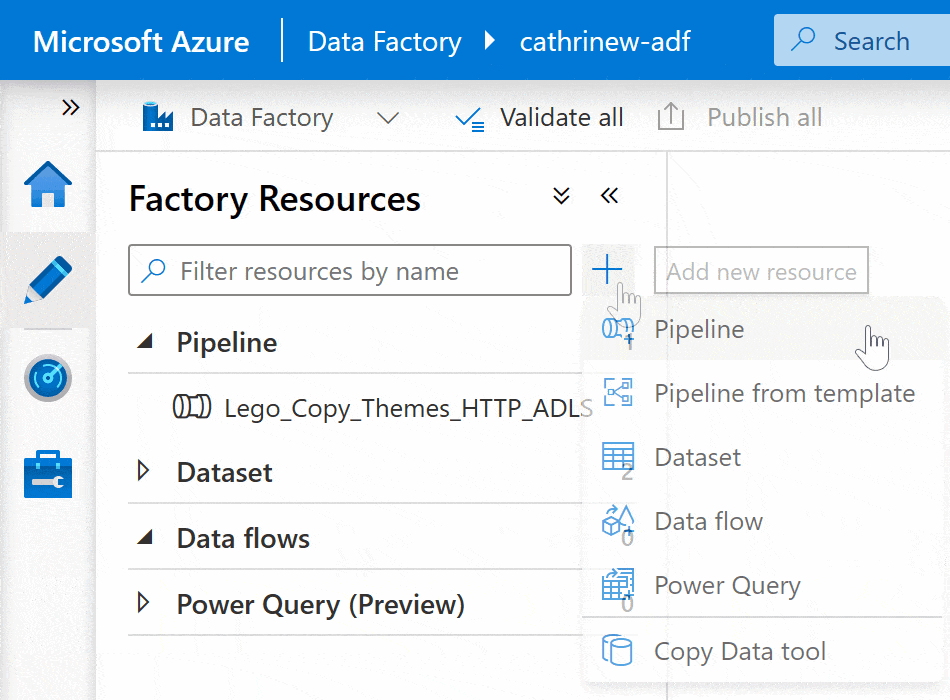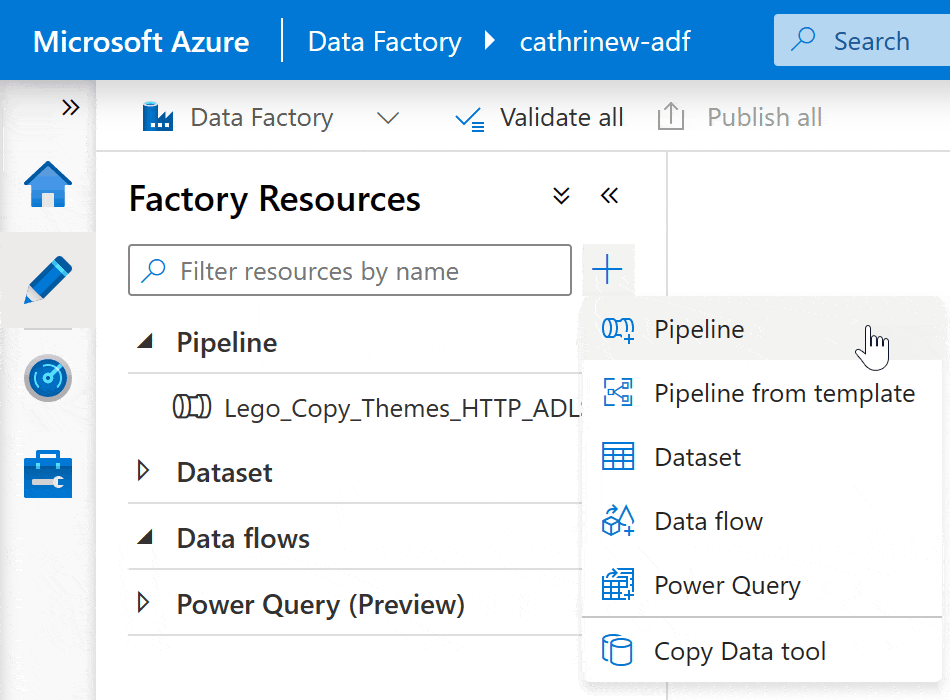
On the Author page, click + (Add new resource) under factory resources and then click Pipeline:
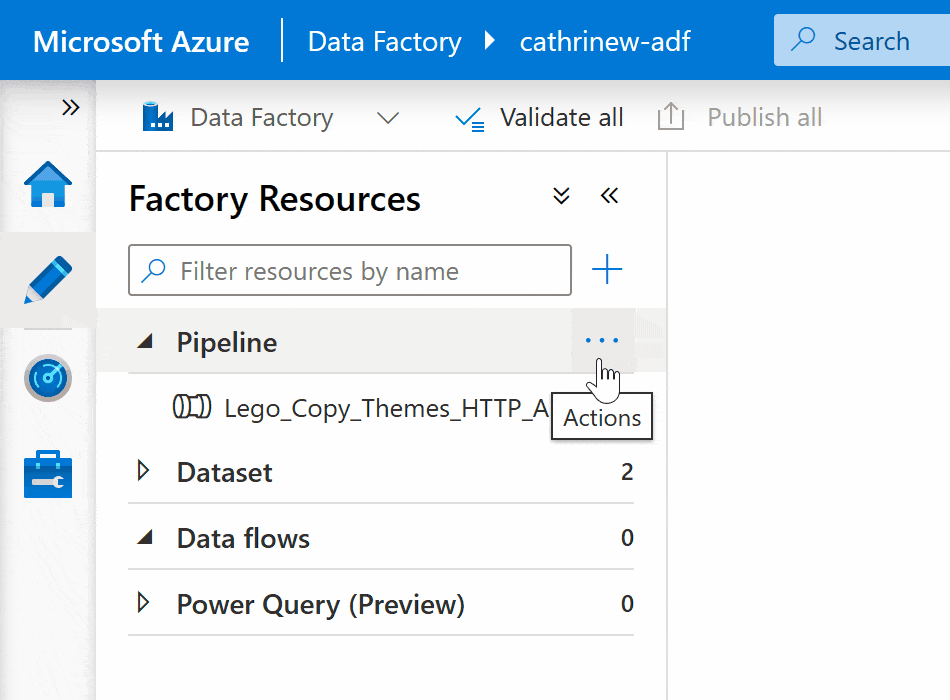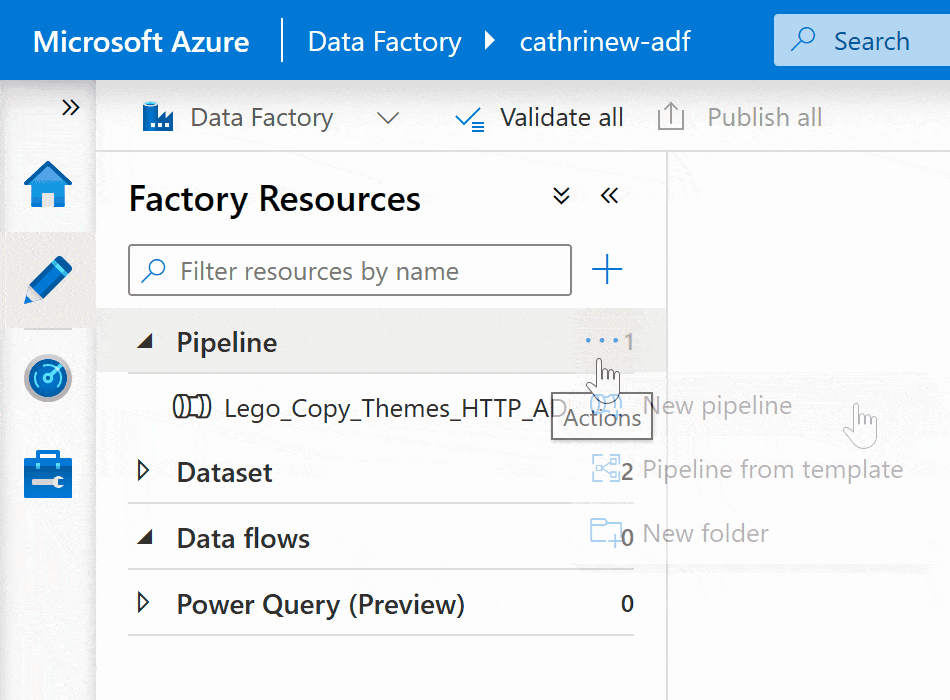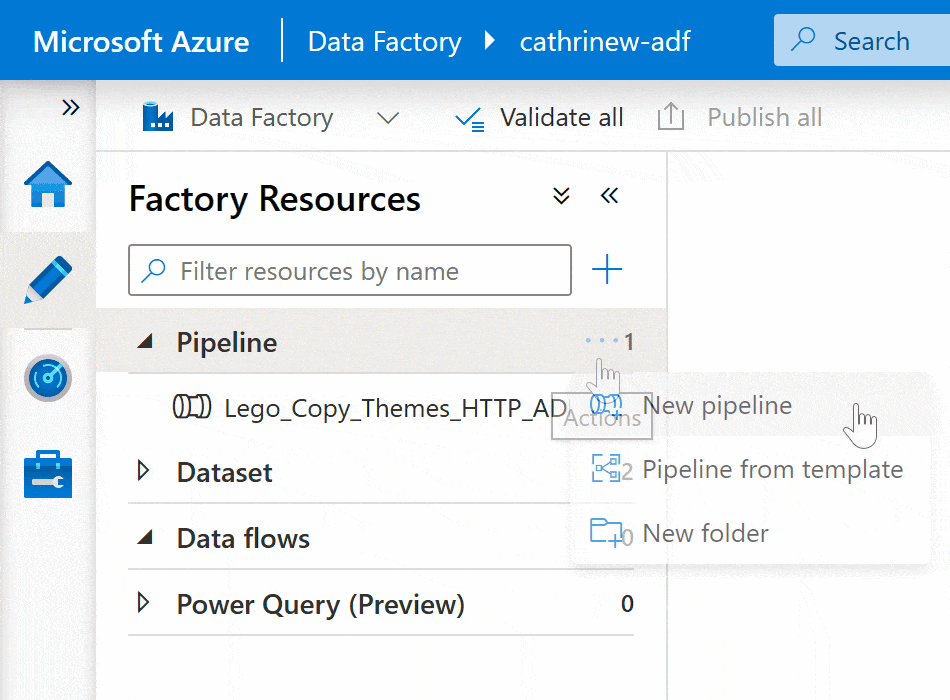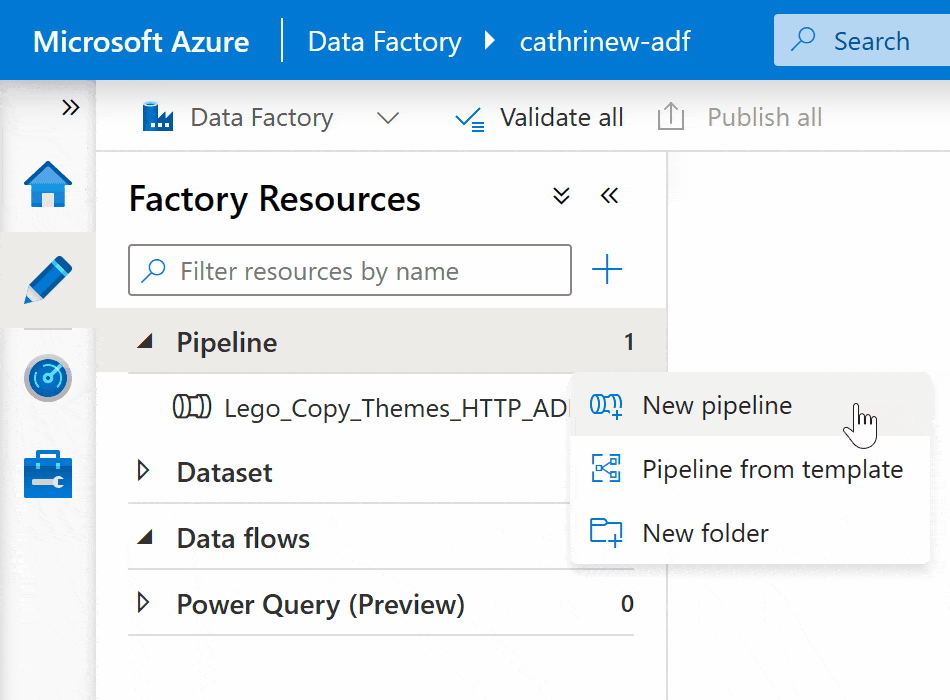
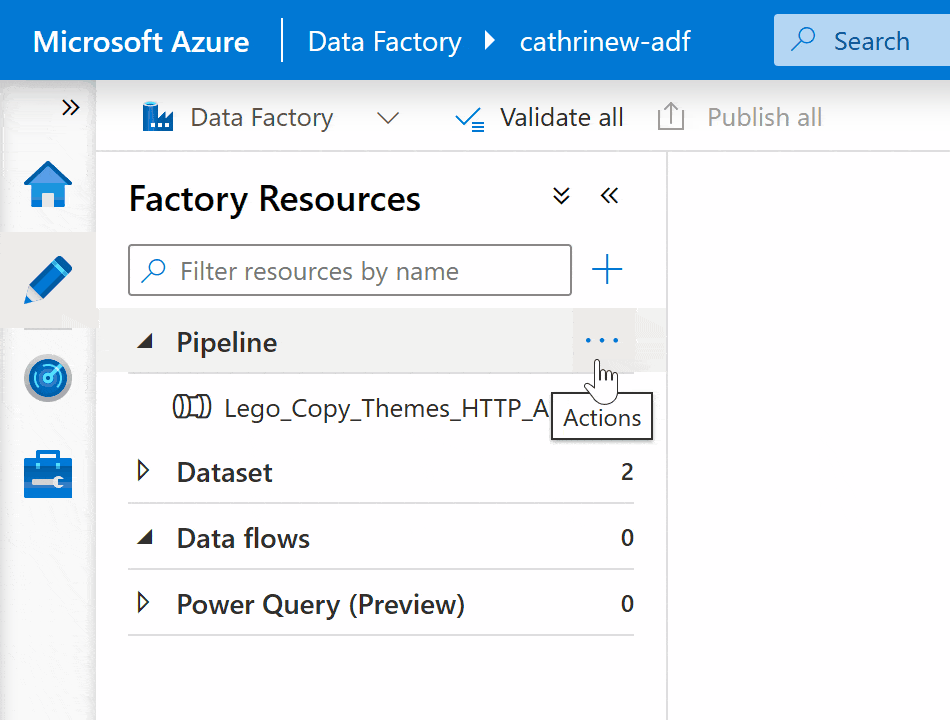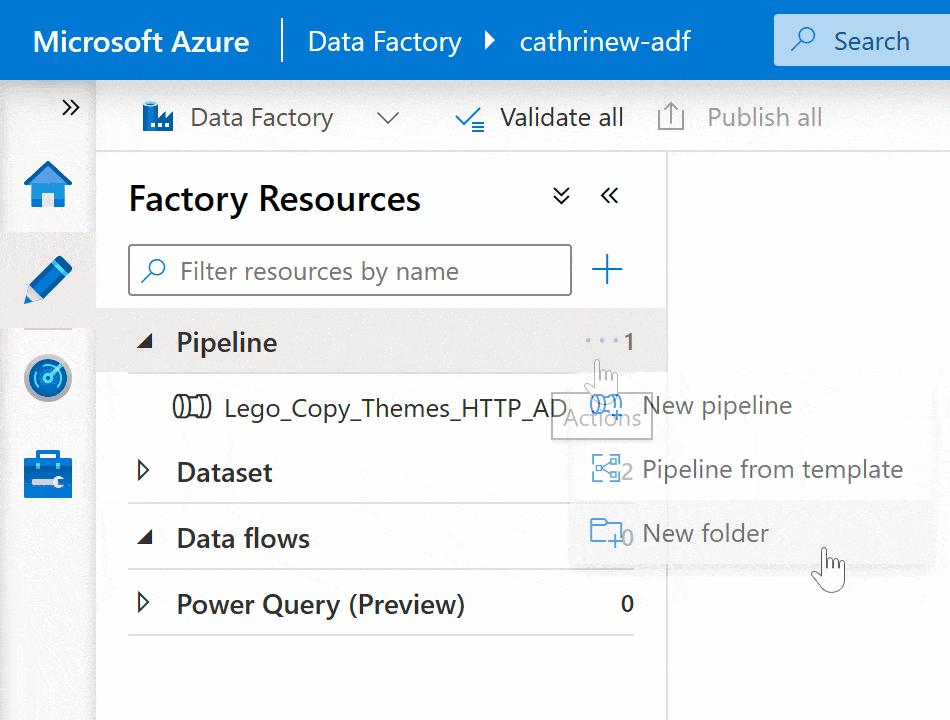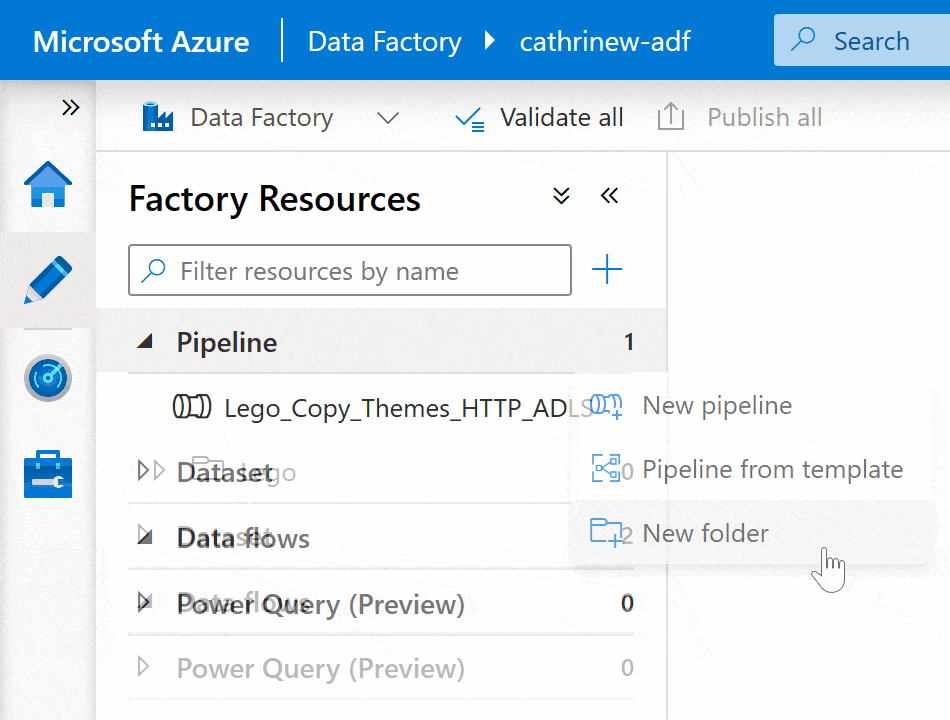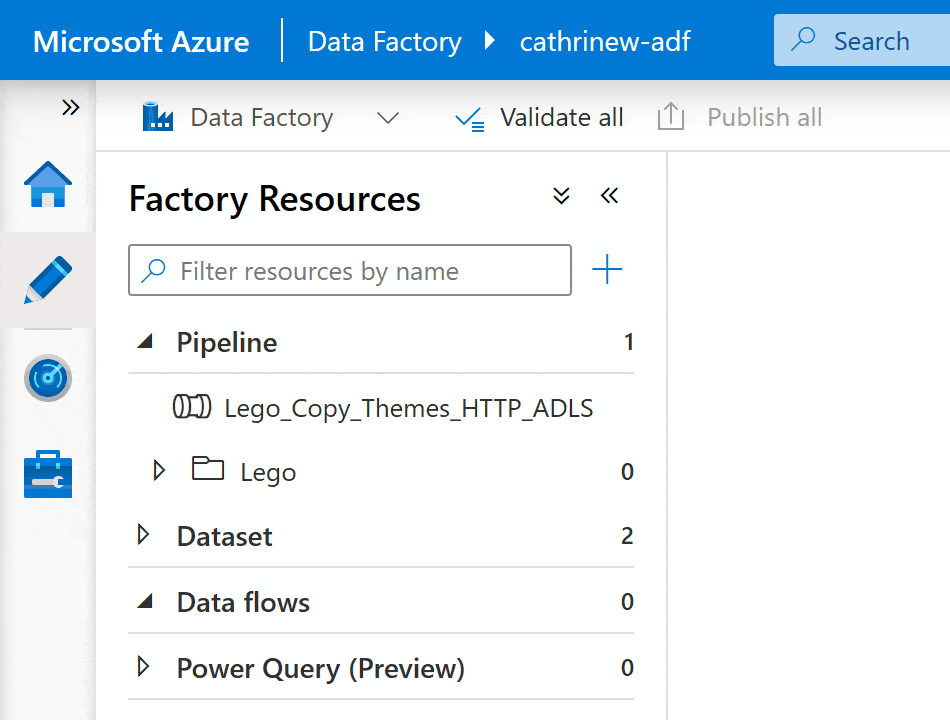
Right-click on the pipeline group header or click on the three-dot (…) Actions menu, then click New pipeline:
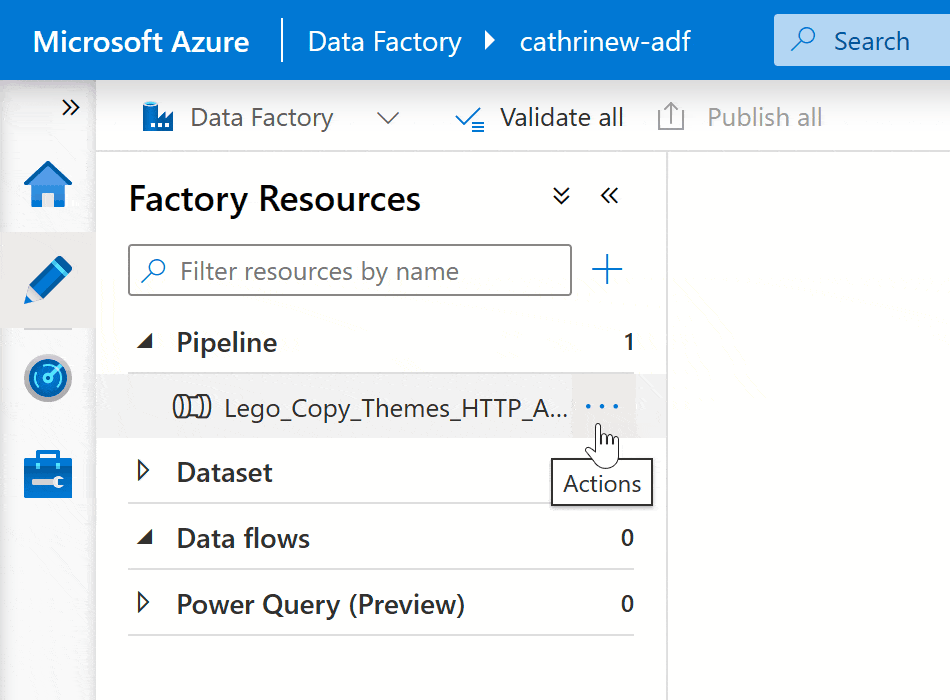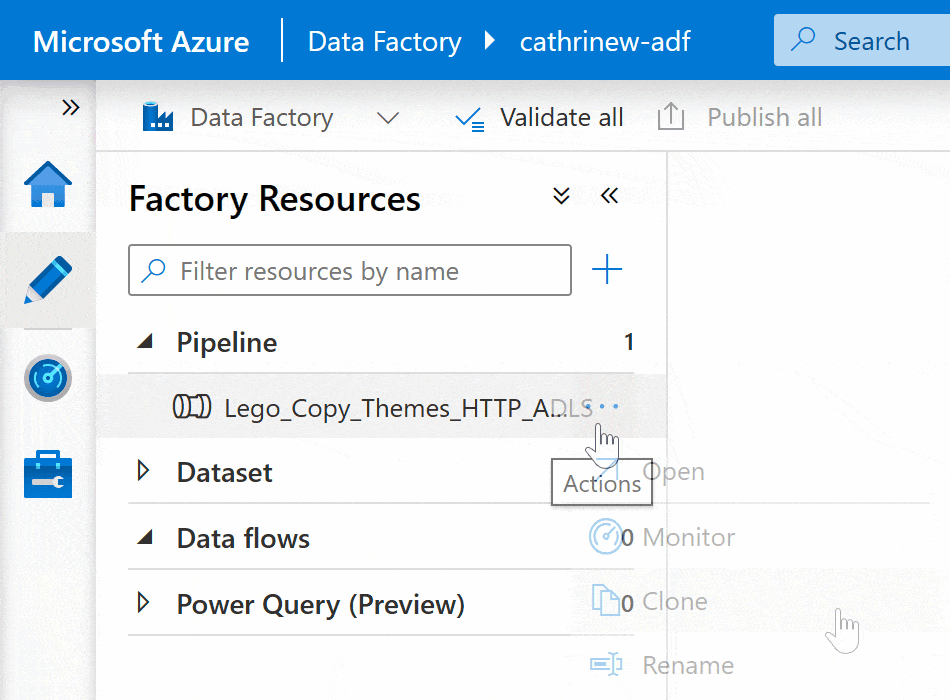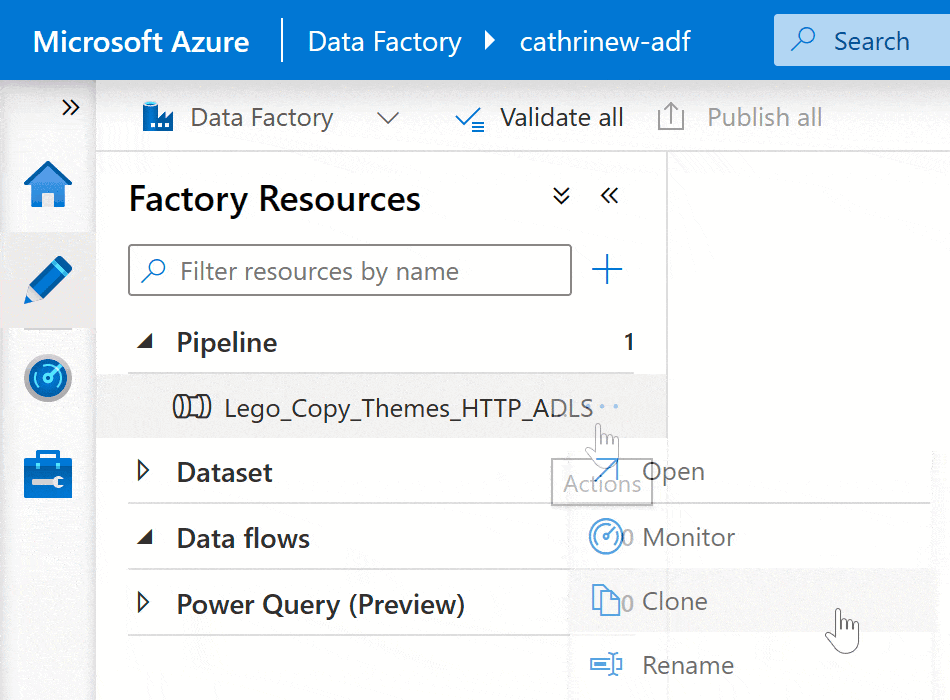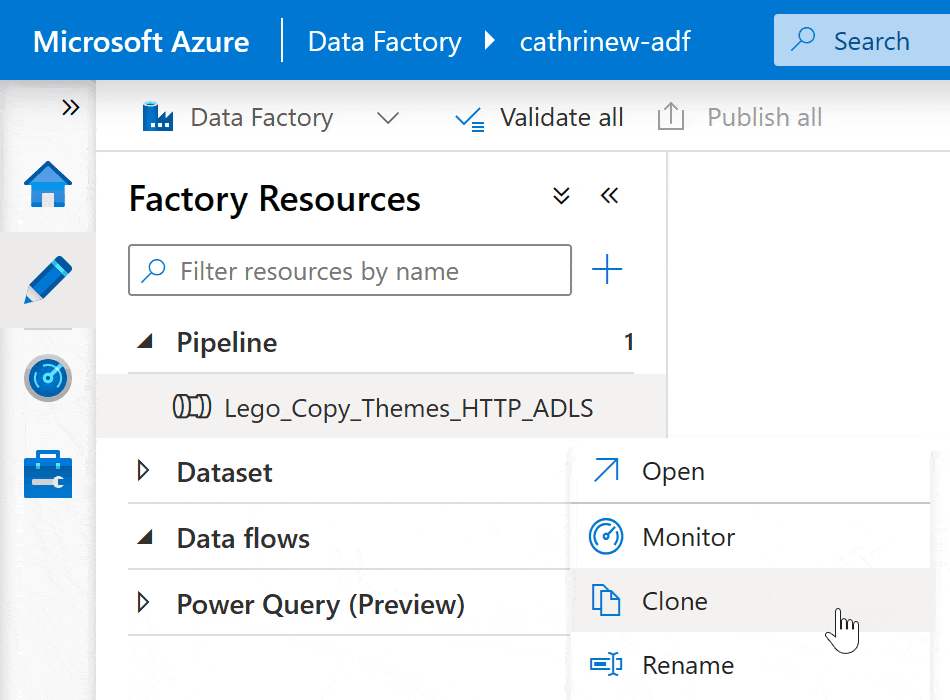
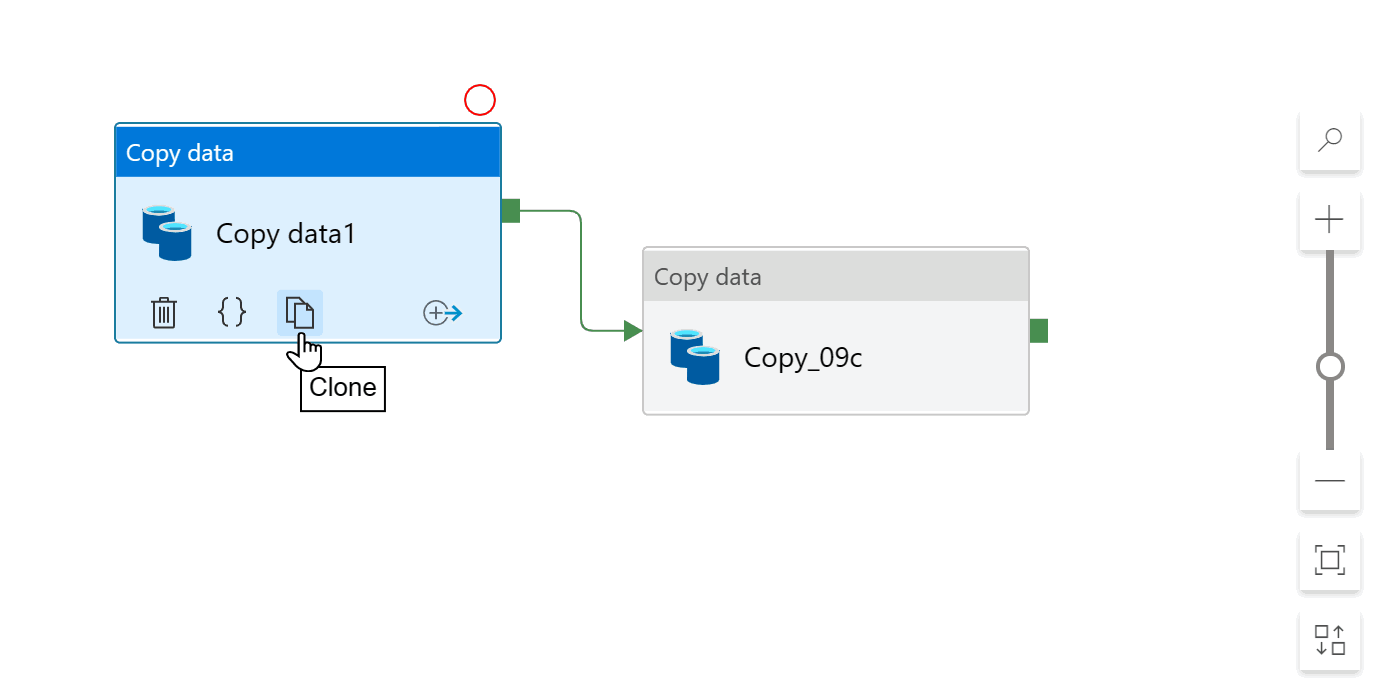
If you already have a pipeline, you can make a copy of it instead of starting from scratch. Right-click on the pipeline or click on the three-dot (…) Actions menu, then click Clone:
How do I organize pipelines?
Pipelines are sorted by name, so I recommend that you decide on a naming convention early in your project. Don’t worry if you end up renaming your pipelines several times while you work on your project. It happens, and that’s completely fine! Just try to stick to some kind of naming convention throughout your project. In addition to naming conventions, you can create folders and subfolders to organize your pipelines.
Right-click on the pipeline group header or click on the three-dot (…) Actions menu, then click New folder:
If you want to create a folder hierarchy, right-click on the folder or click the three-dot (…) Actions menu, then click New subfolder:
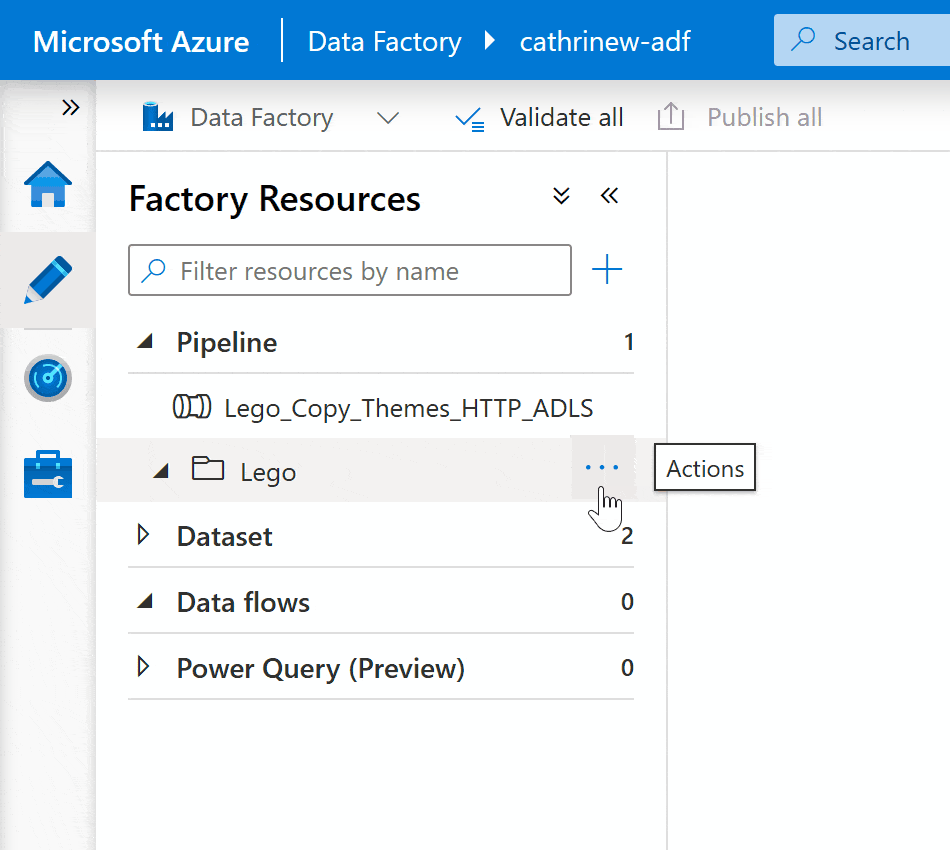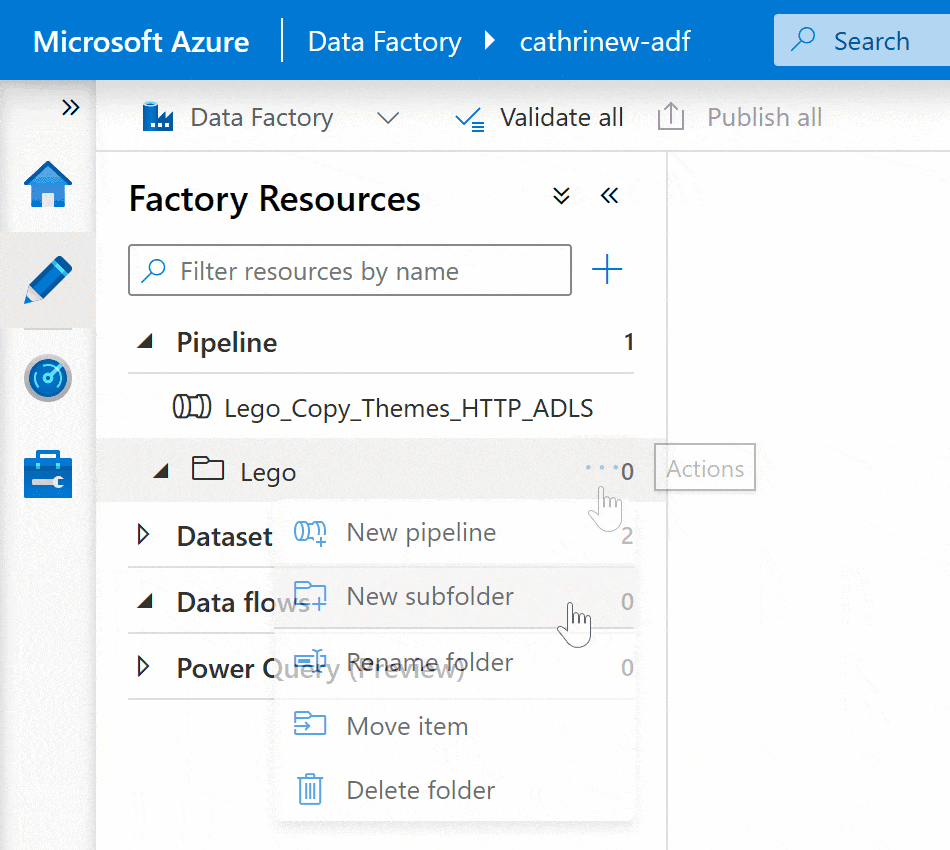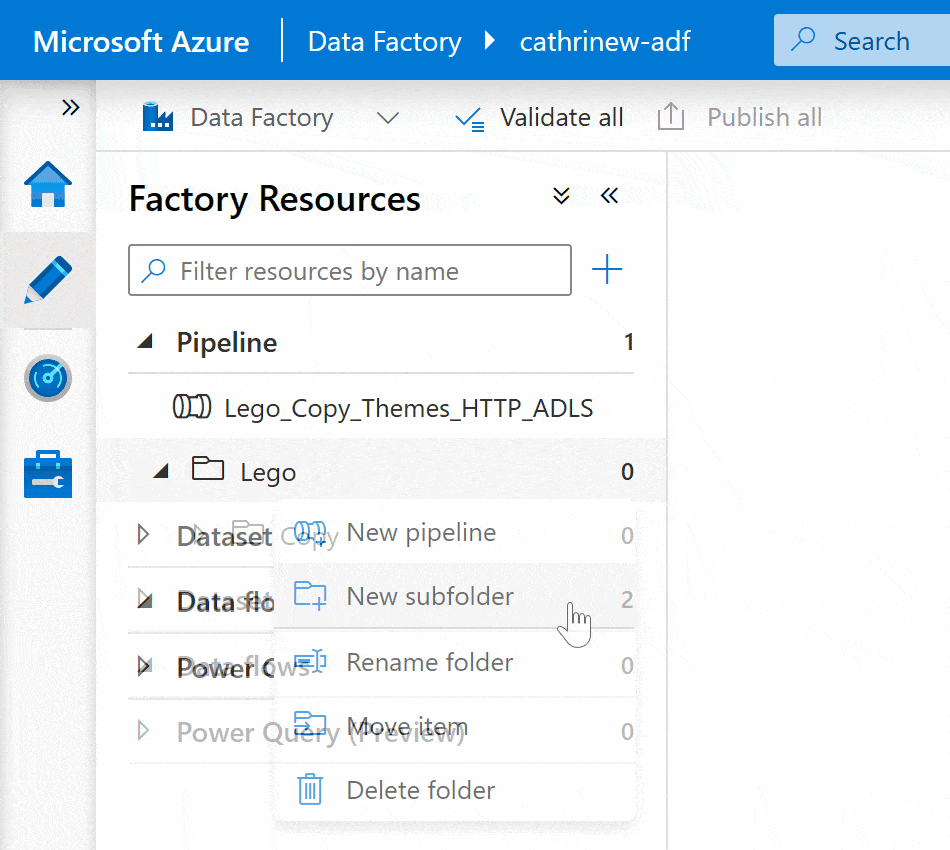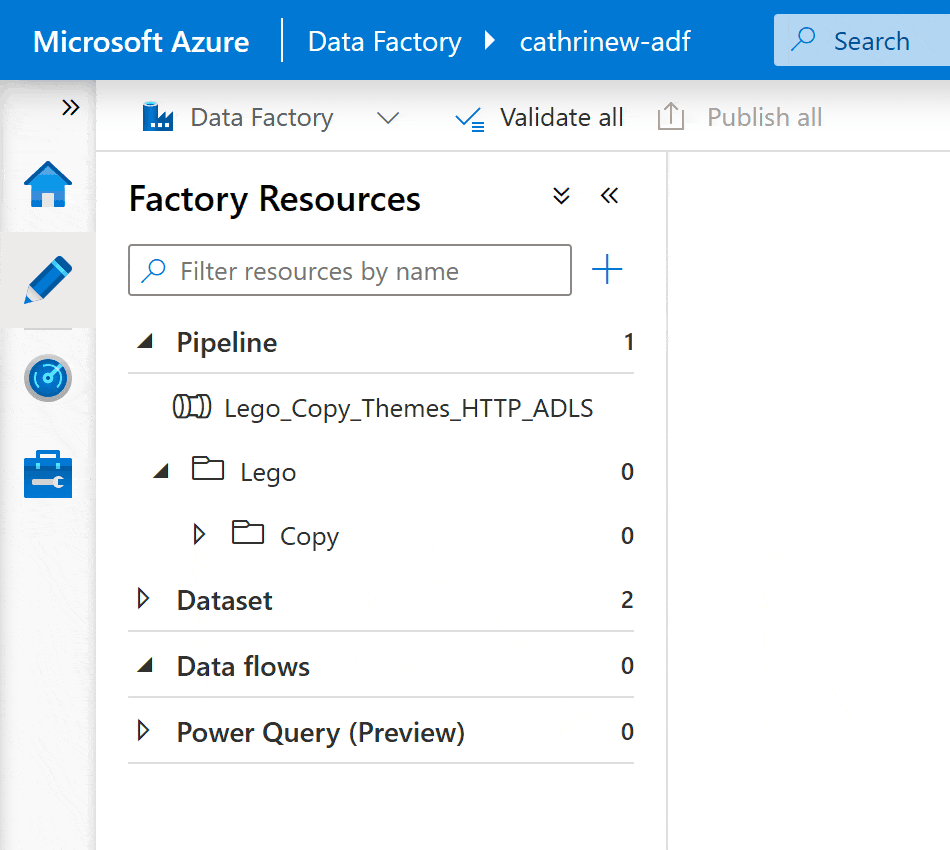
After creating folders, you can create new pipelines directly in them:
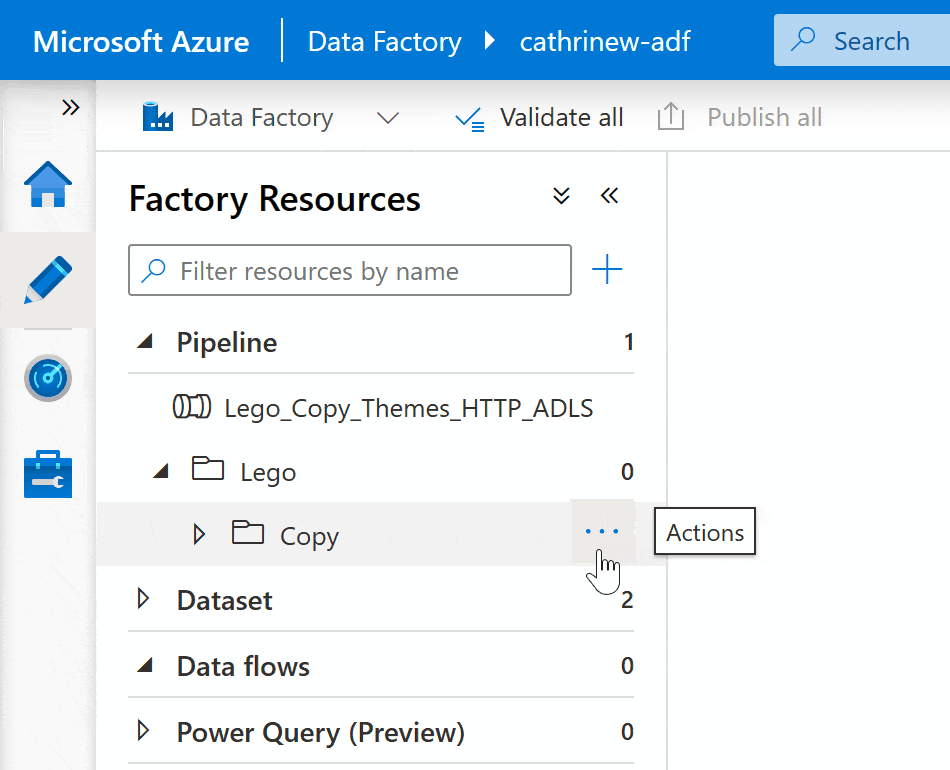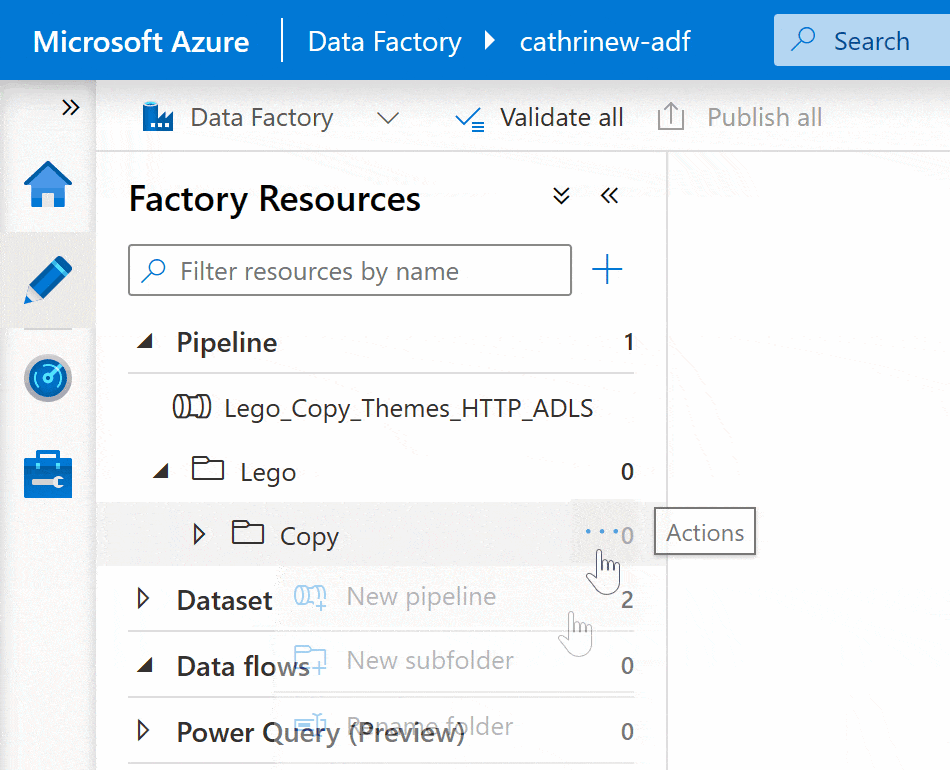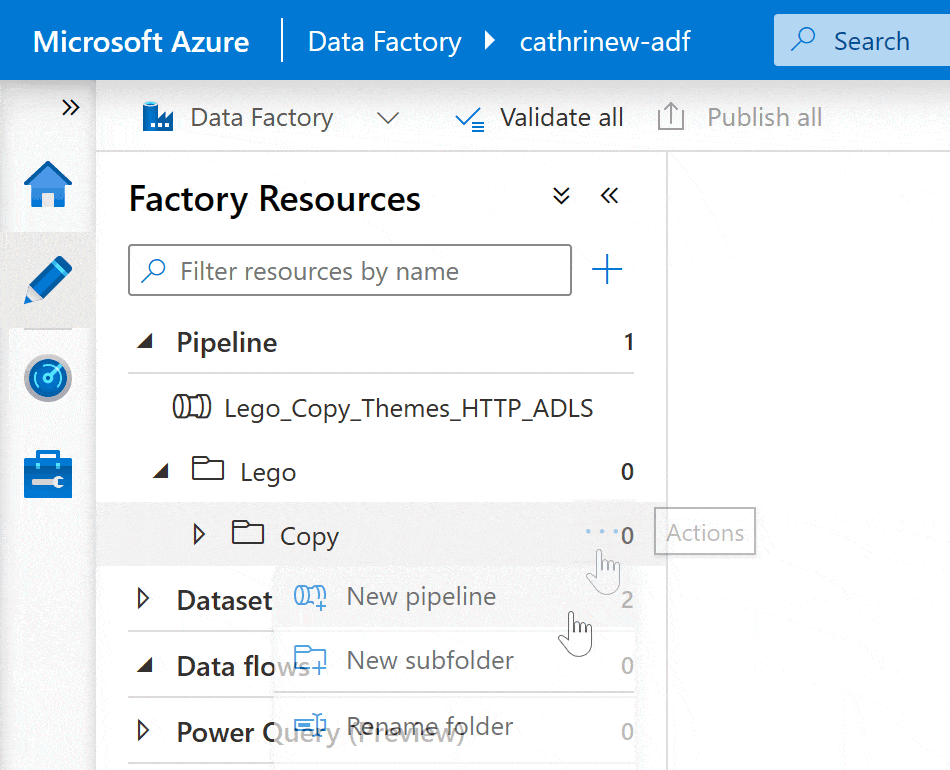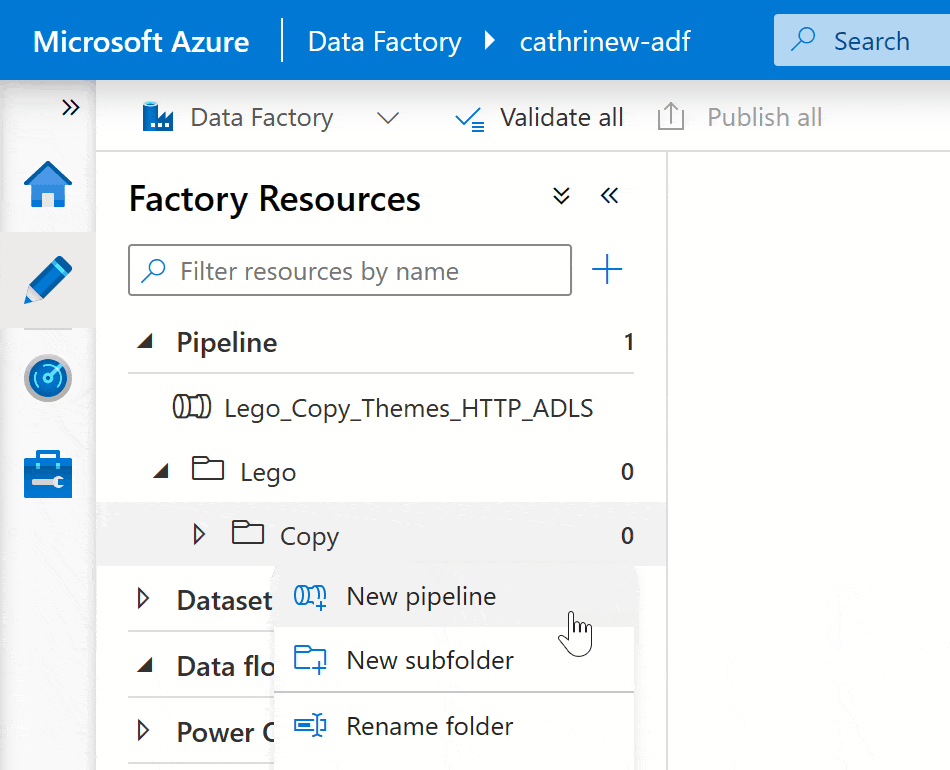
You can move pipelines into folders and subfolders by dragging and dropping:
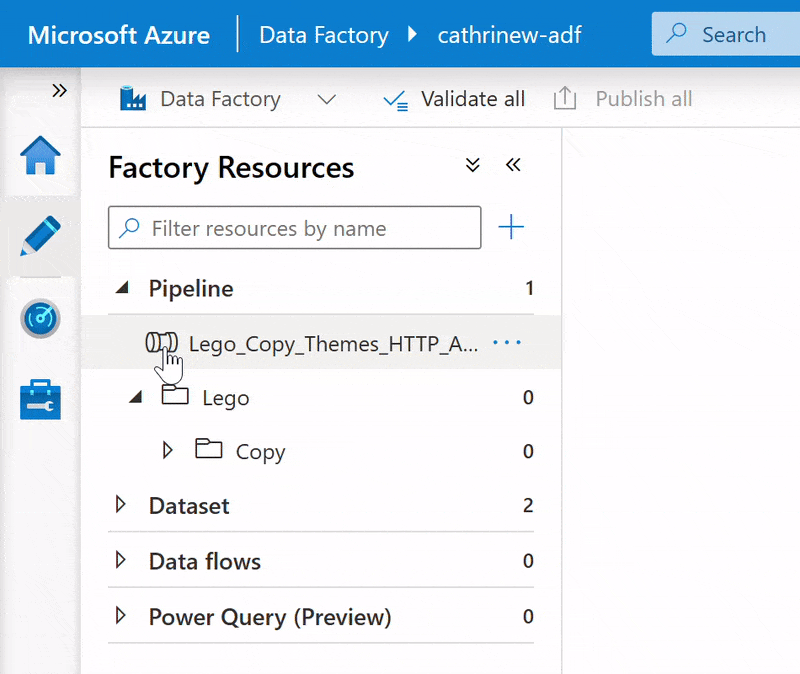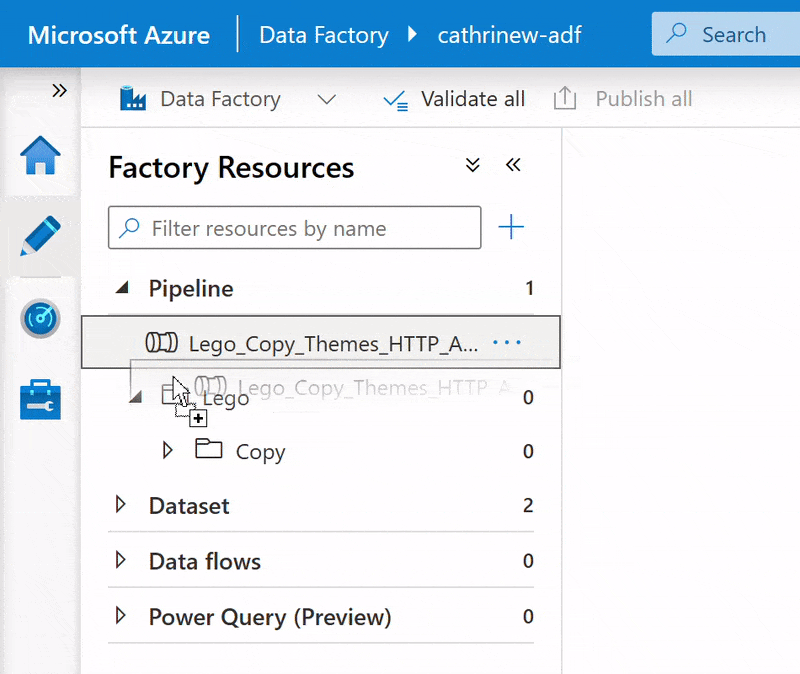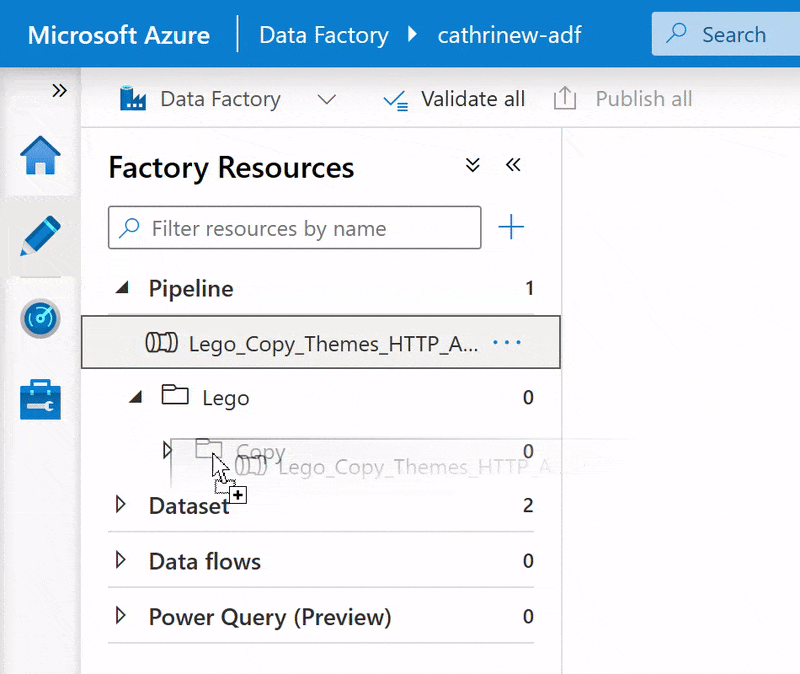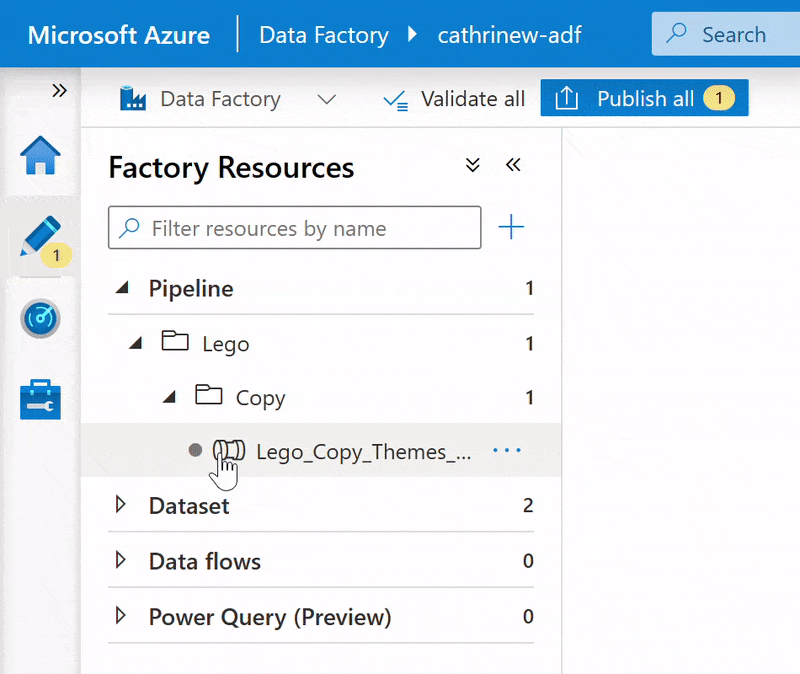
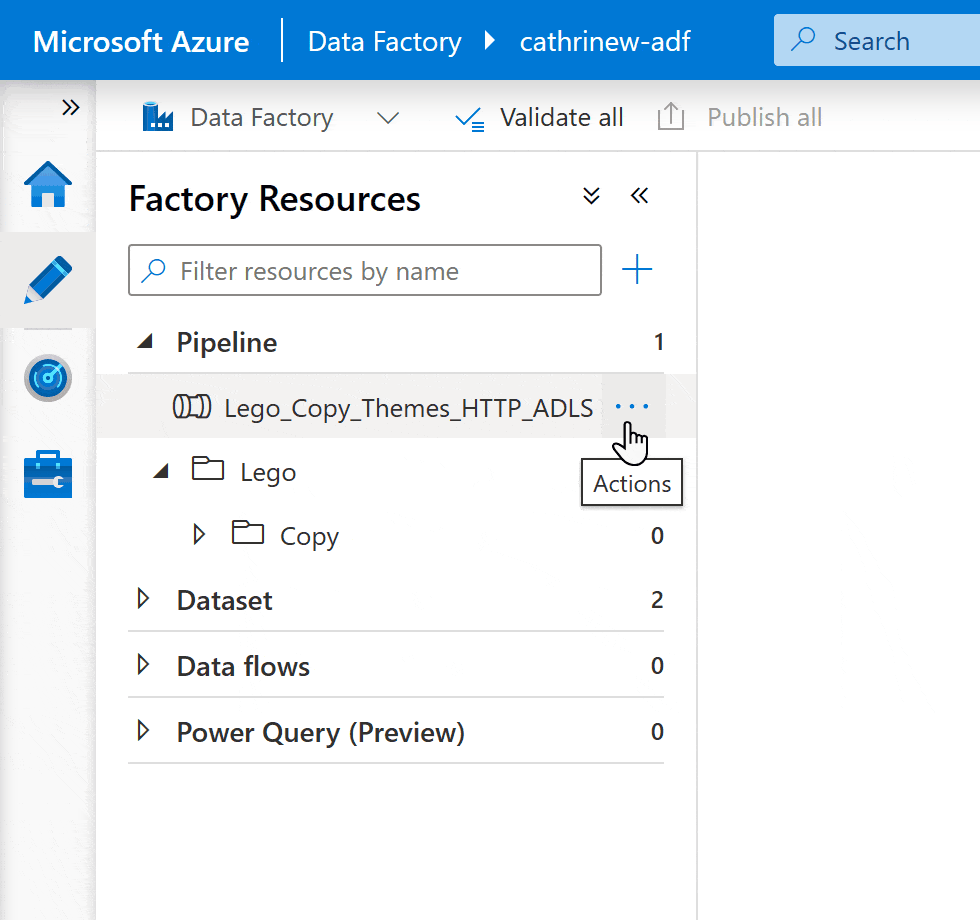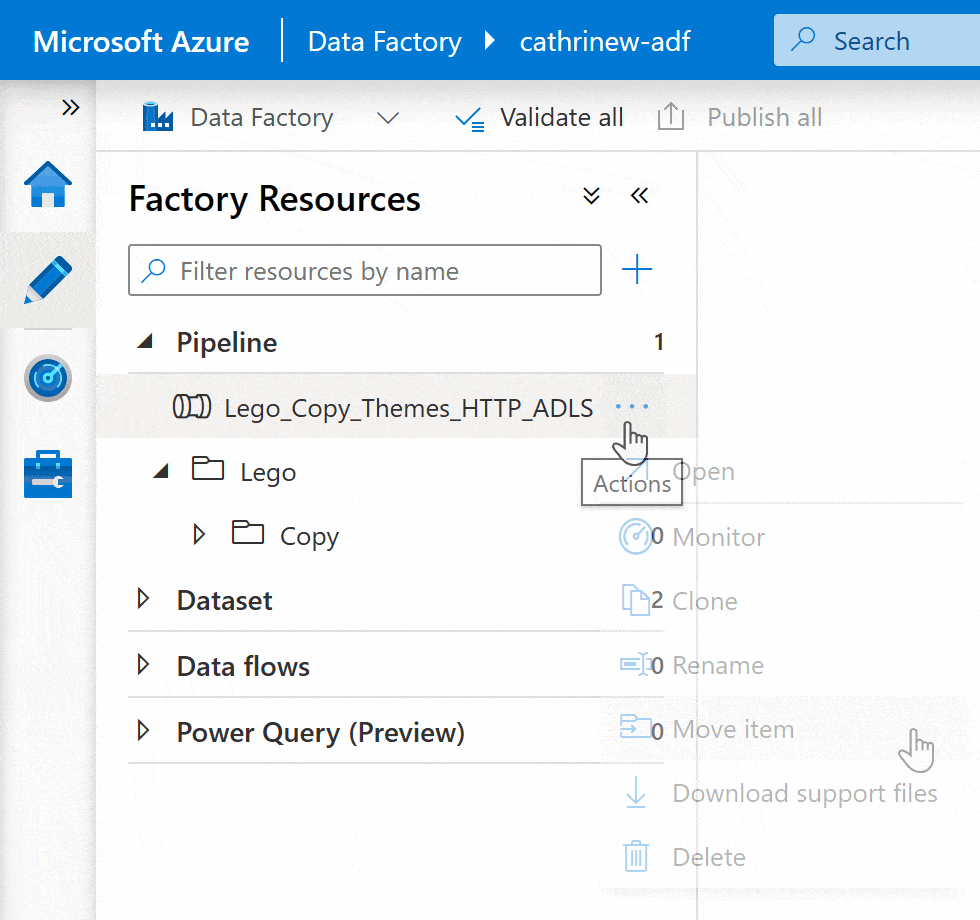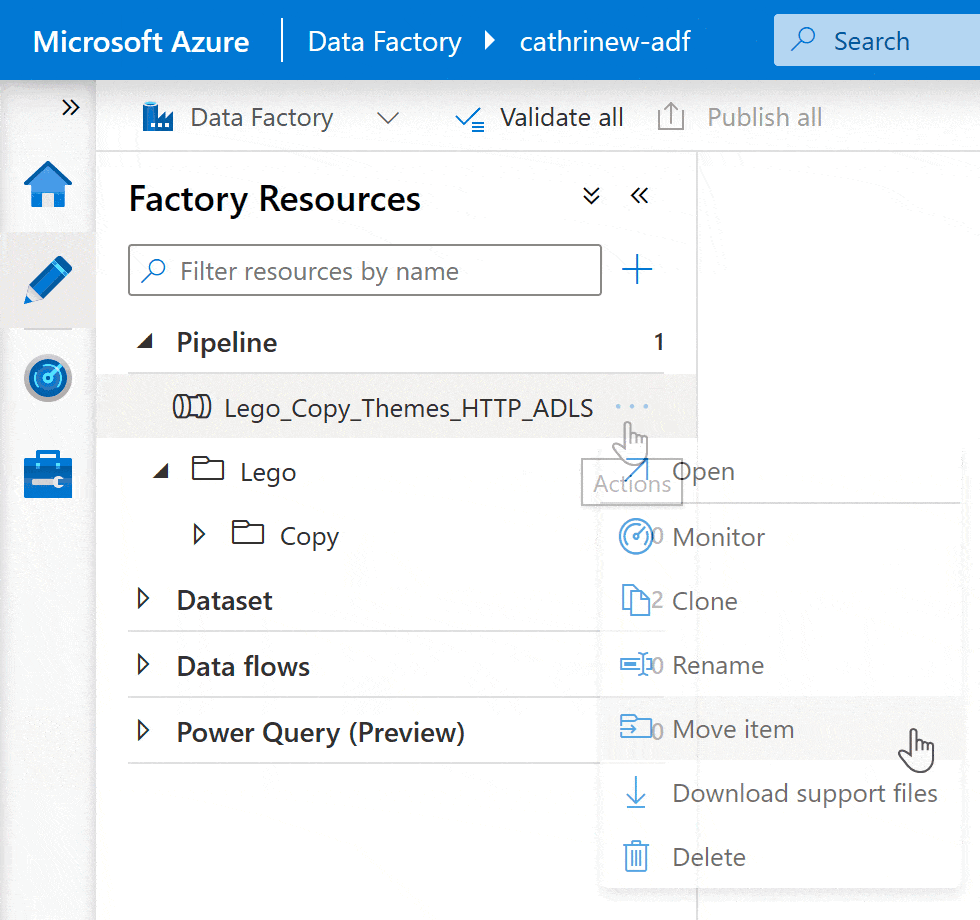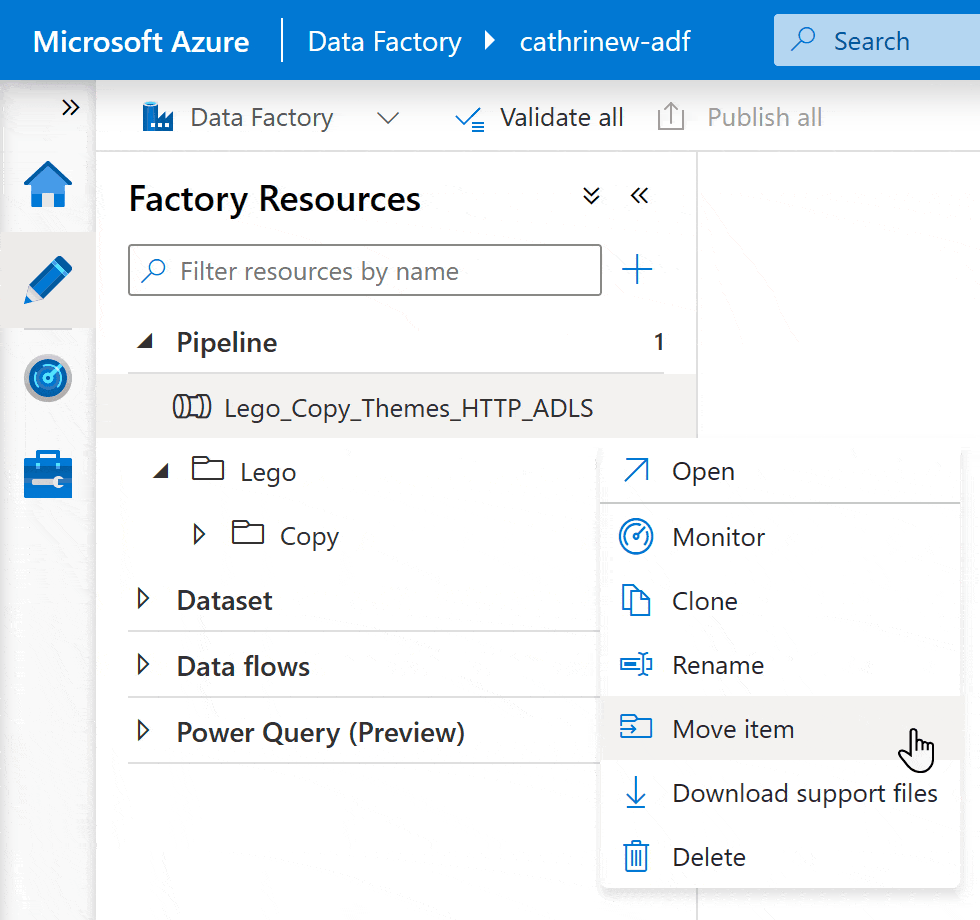
I prefer dragging and dropping when I have a small number of folders and pipelines. Once the list extends below the visible part of the screen, it can be easier to use Move item:
How do I build pipelines?
You build pipelines by adding activities to it. To add an activity, expand the activity group and drag an activity onto the design canvas:
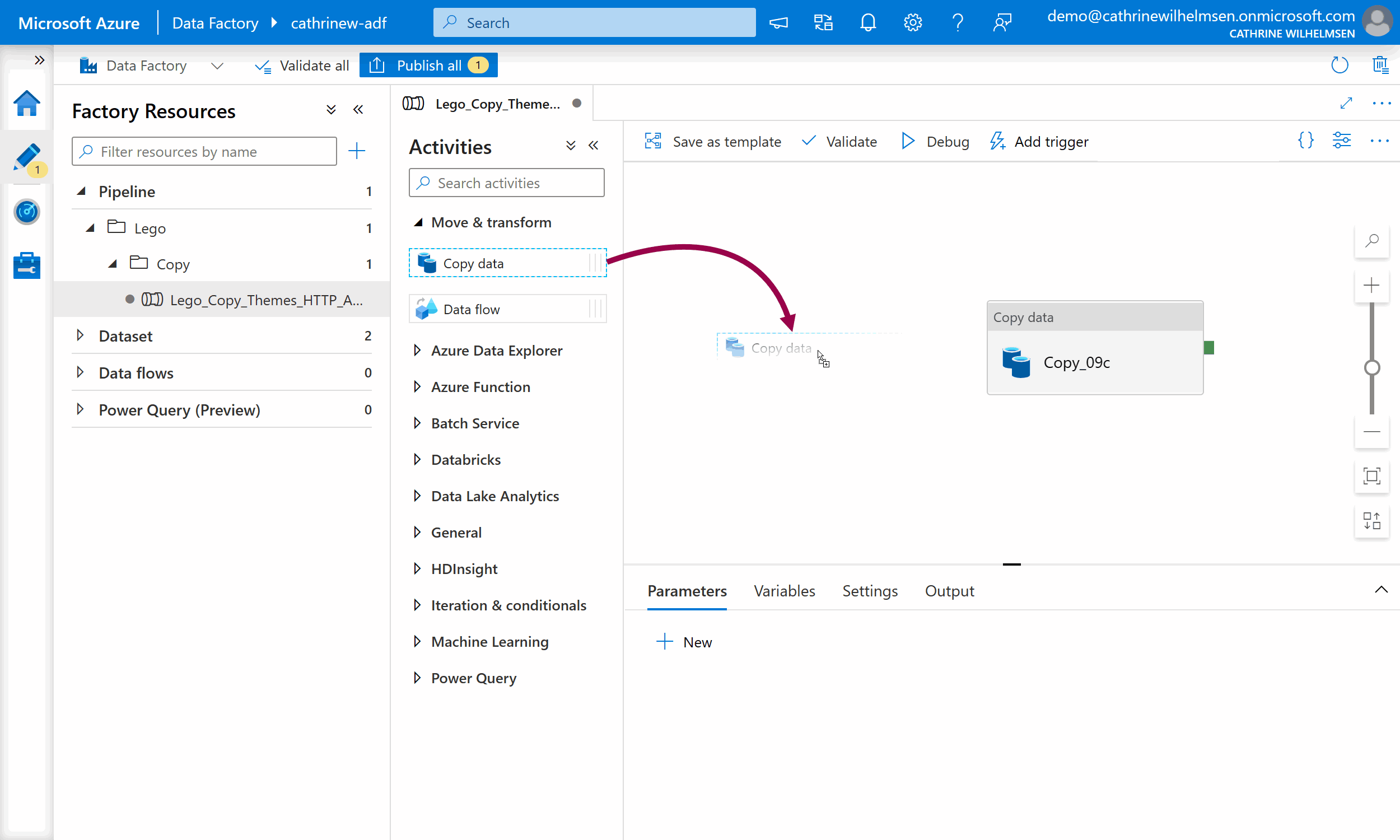
You can move the activity by selecting it, then dragging it. If you click on the blank design canvas and drag, you will move the entire pipeline around.
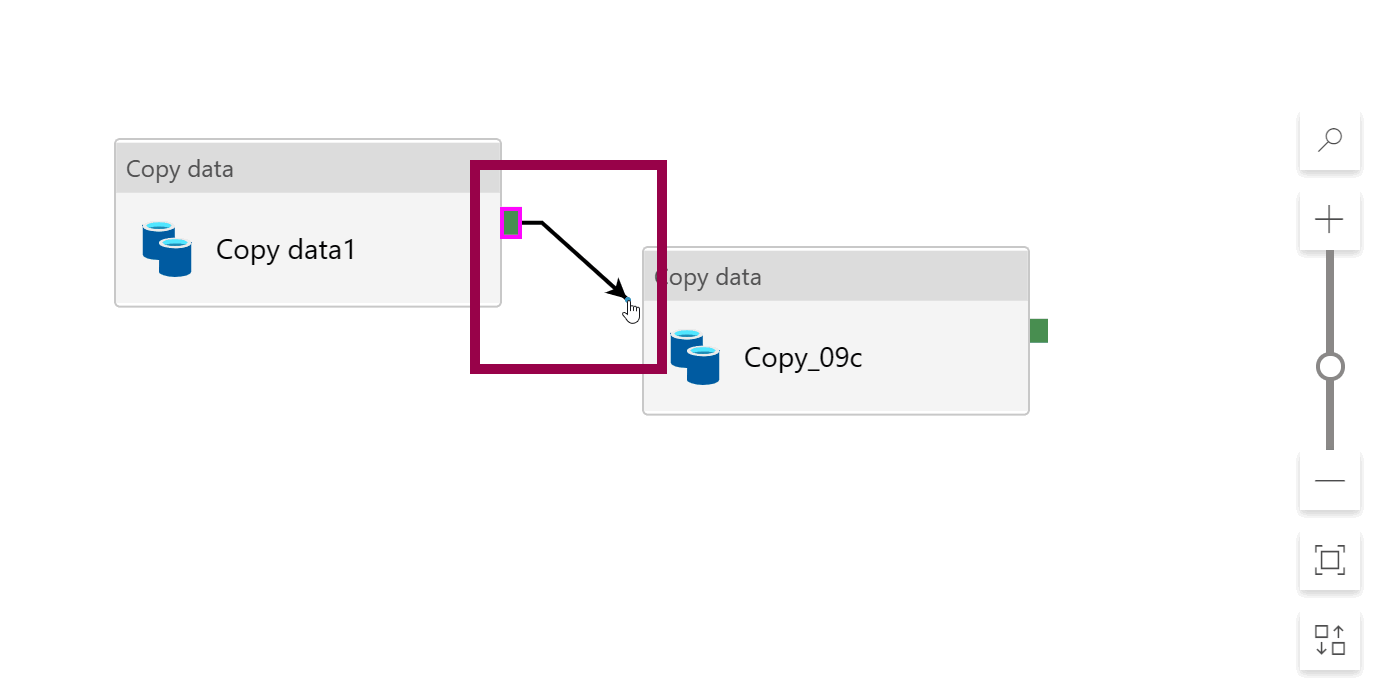
To chain activities, click and hold the little, green square on the right side of the first activity, then drag the arrow onto the second activity. The activities will now be executed sequentially instead of in parallel:
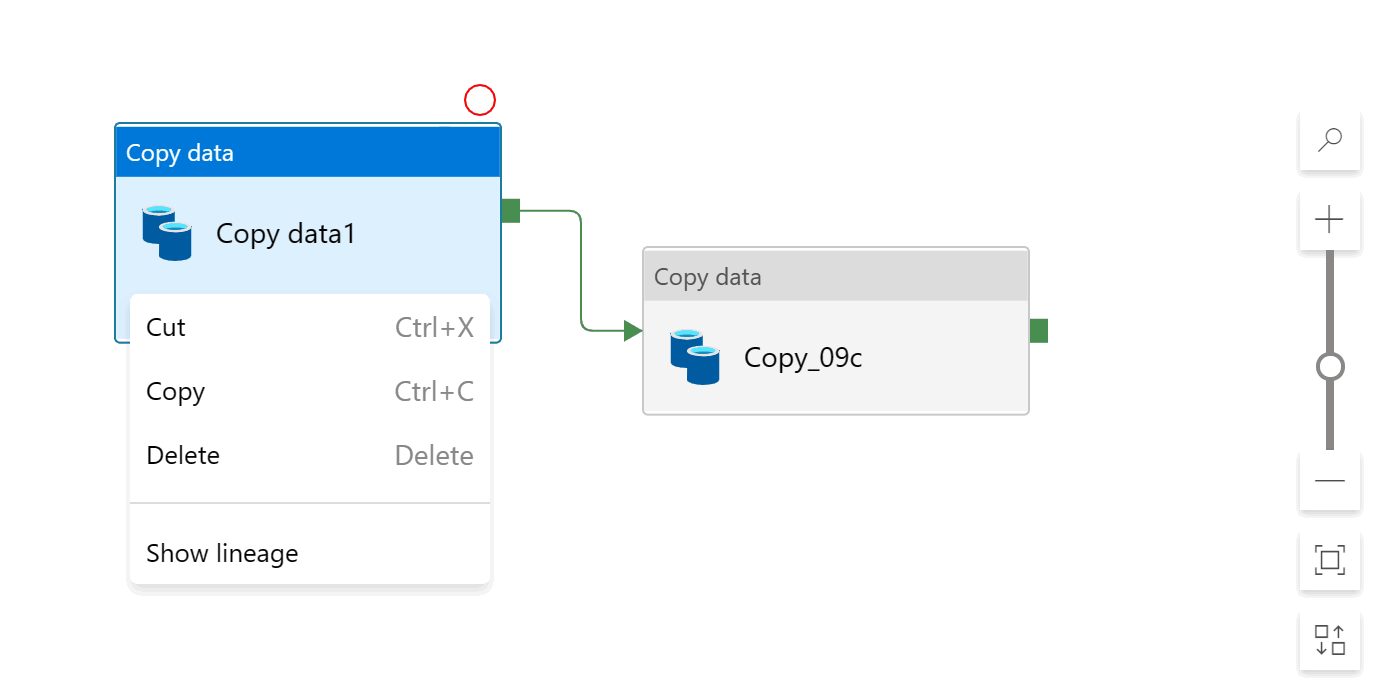
You can cut, copy, paste, and delete activities by using the keyboard shortcuts Ctrl+X, Ctrl+C, Ctrl+V, and Delete, or by right-clicking and using the menu:
Instead of copying and pasting, it might be easier to click the clone button:
How do I adjust the layout of a pipeline?
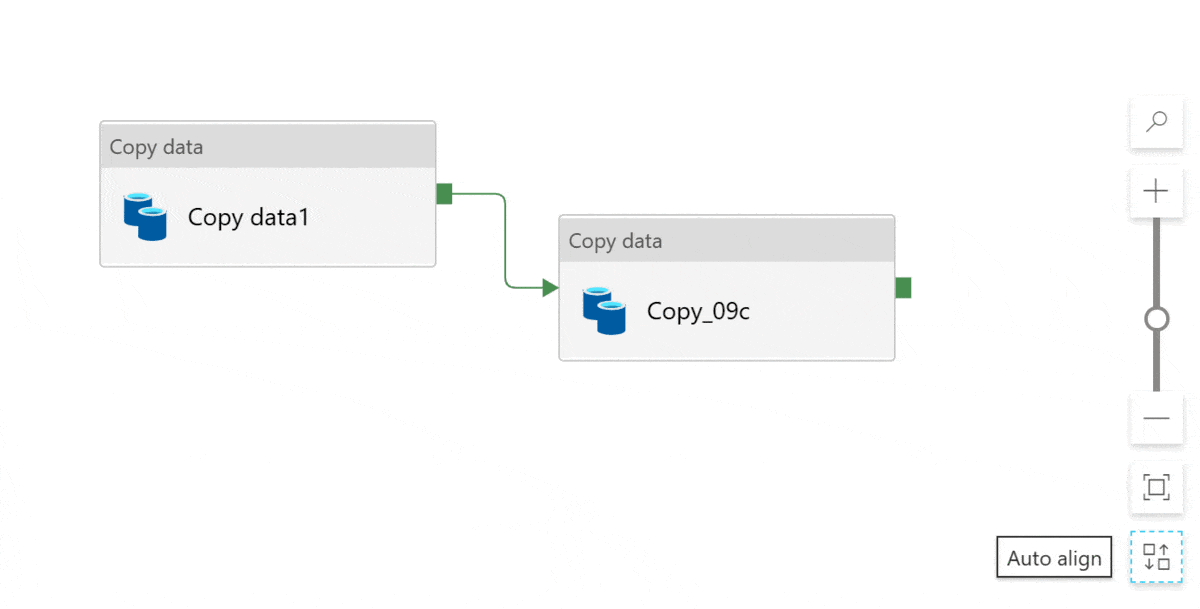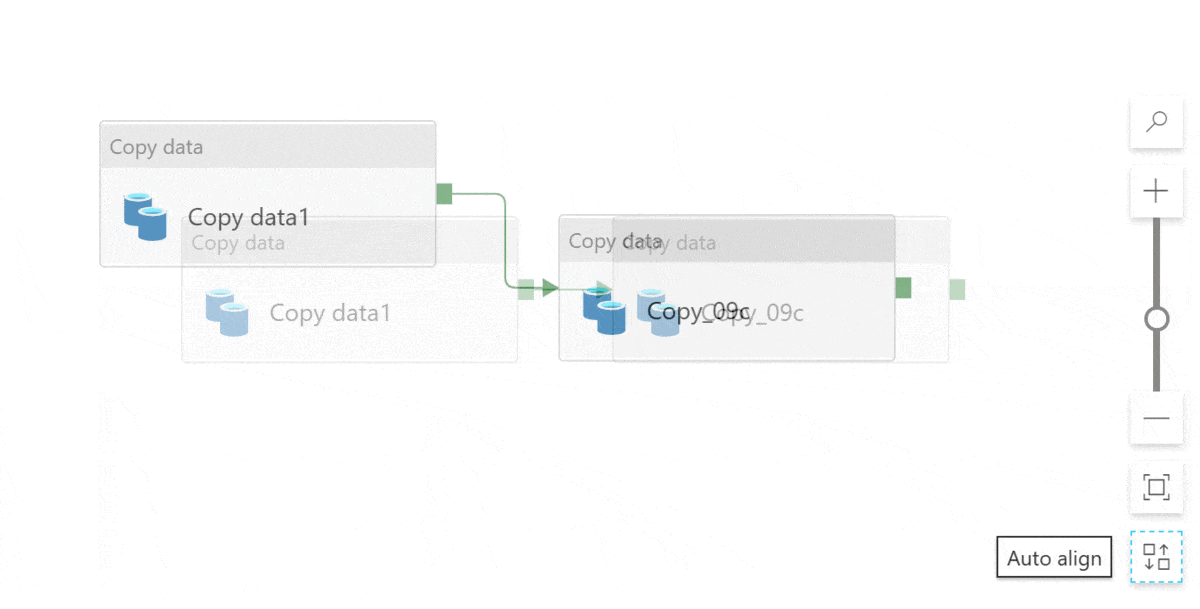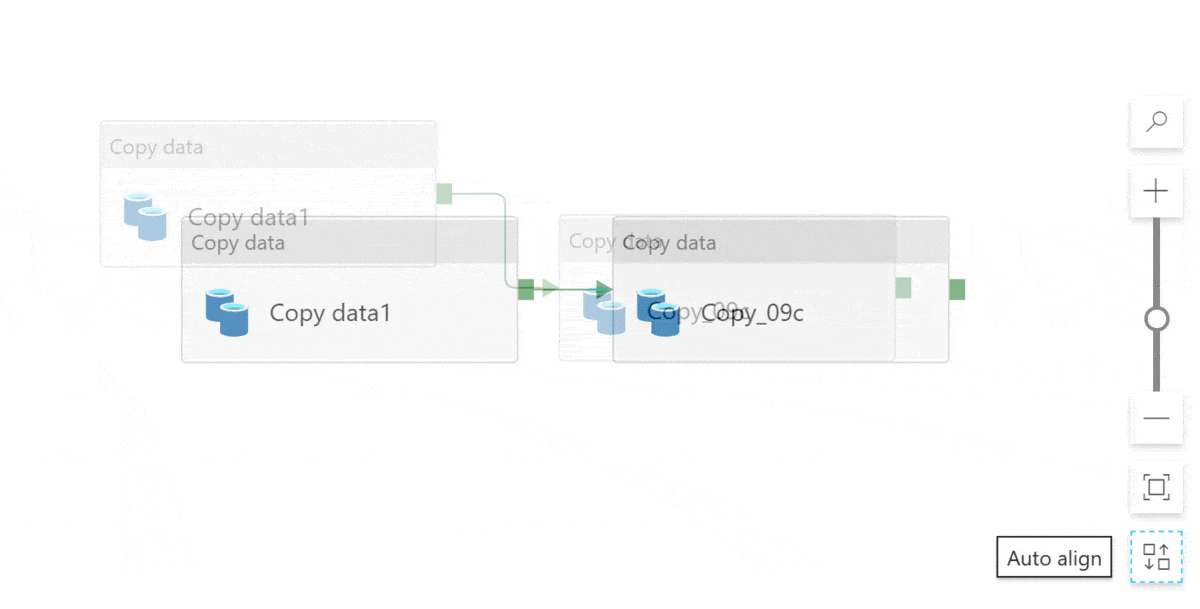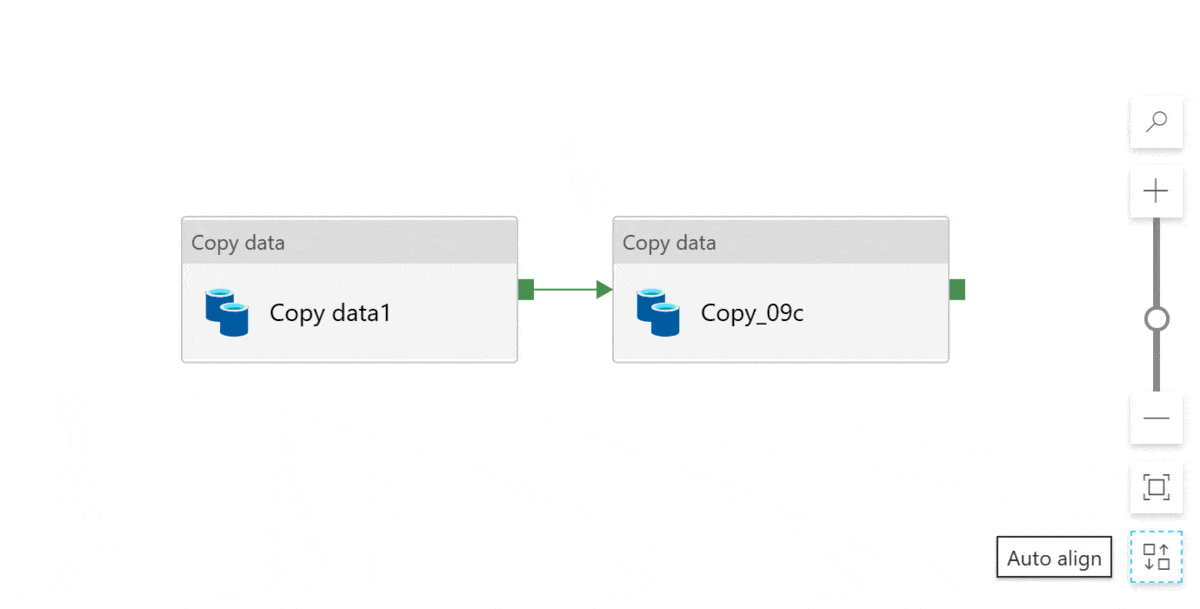
If you are like me and cringe when you see messy layouts, don’t worry! There’s a couple of buttons just for us 😅 Click auto align to clean up the layout. Magic! That looks better:
You can zoom in and out using the + and - buttons. You can also zoom to fit the entire pipeline. If you have many activities, it will zoom out for you. If you have few activities, it will zoom in for you:
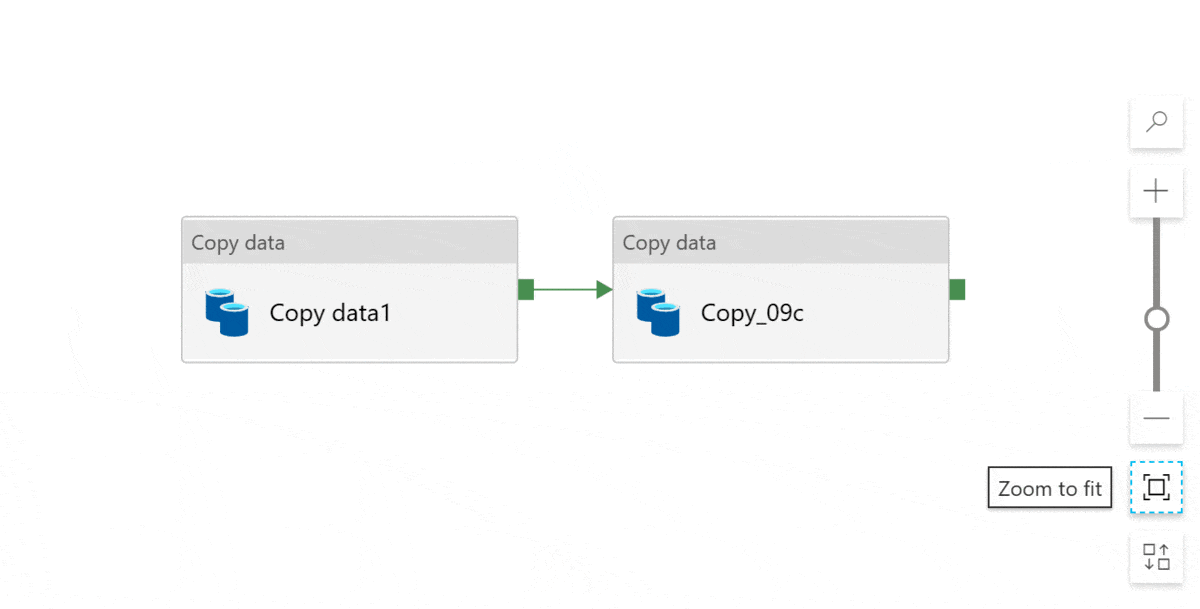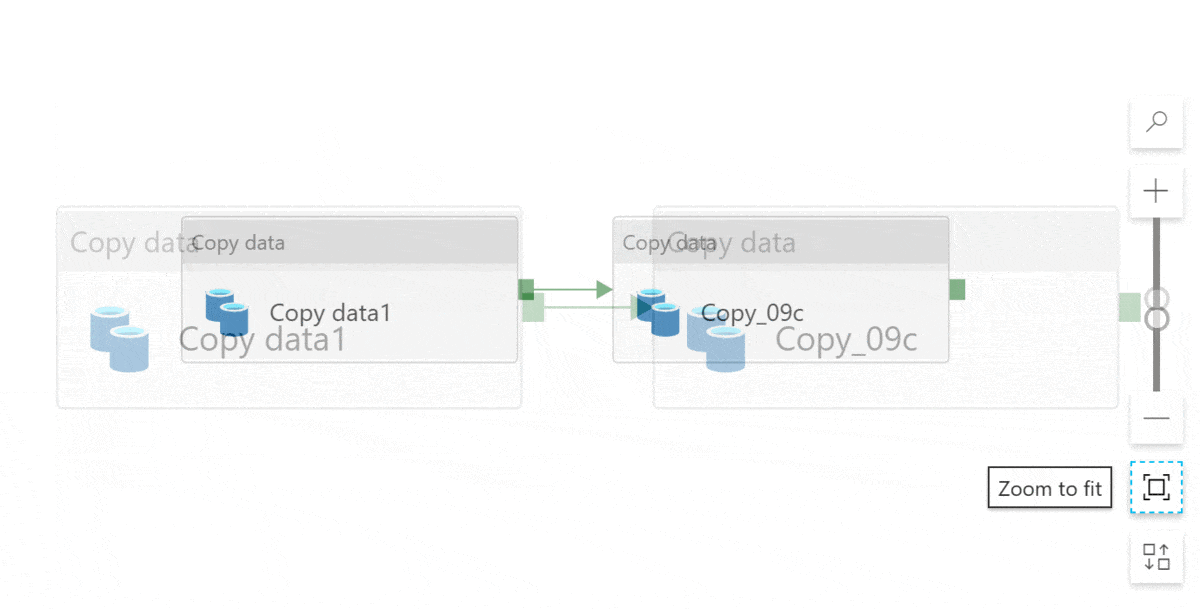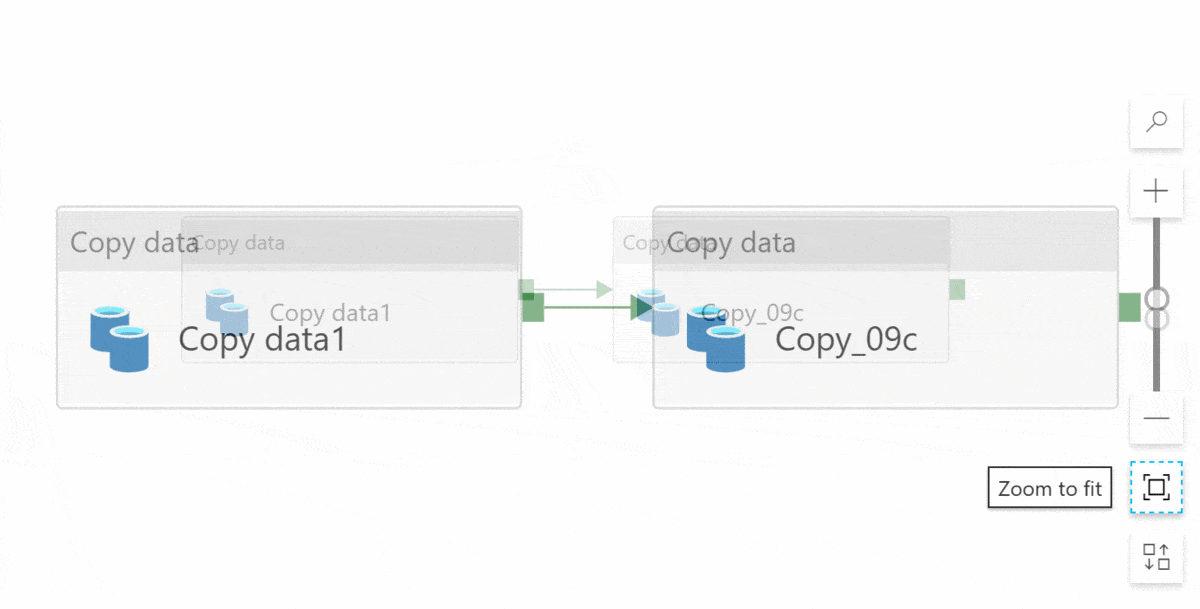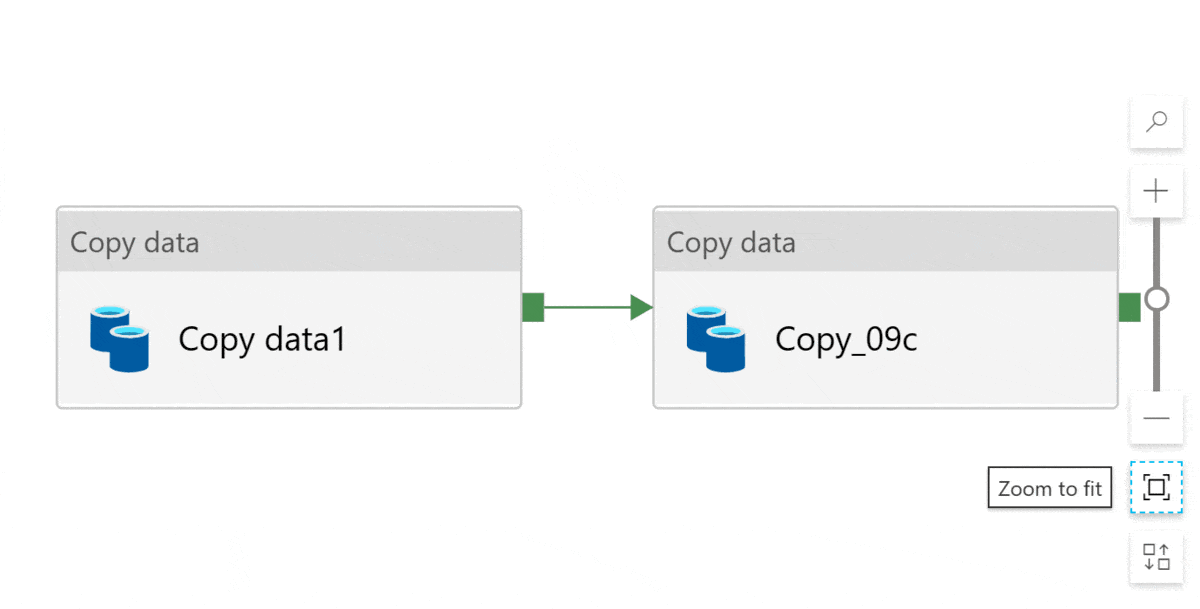
If you want to reset the design canvas, click reset zoom level:
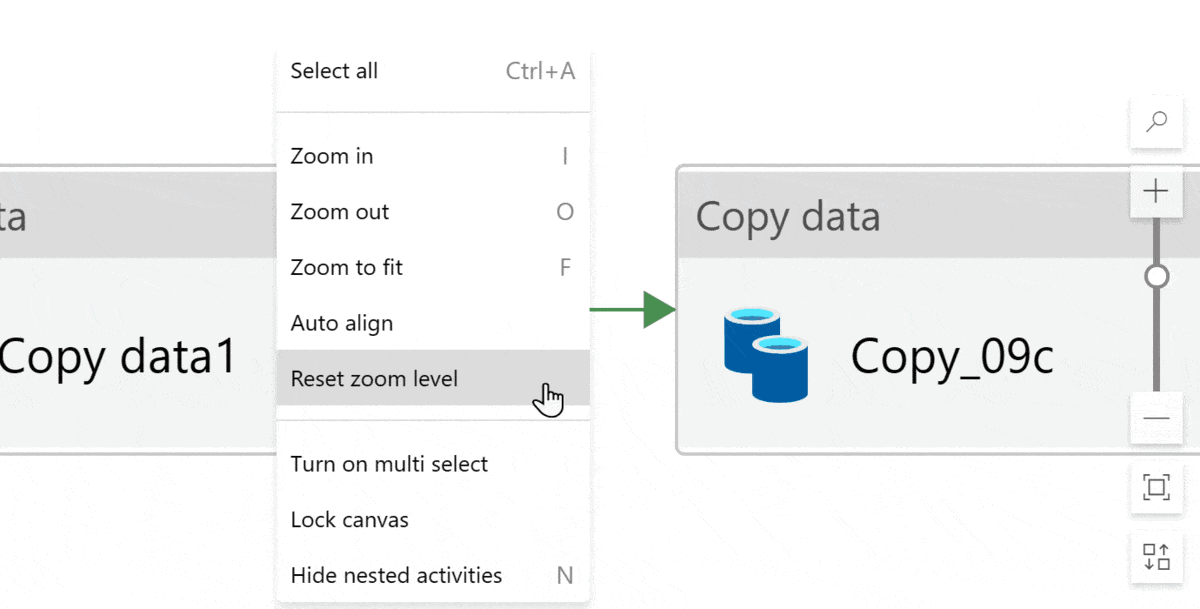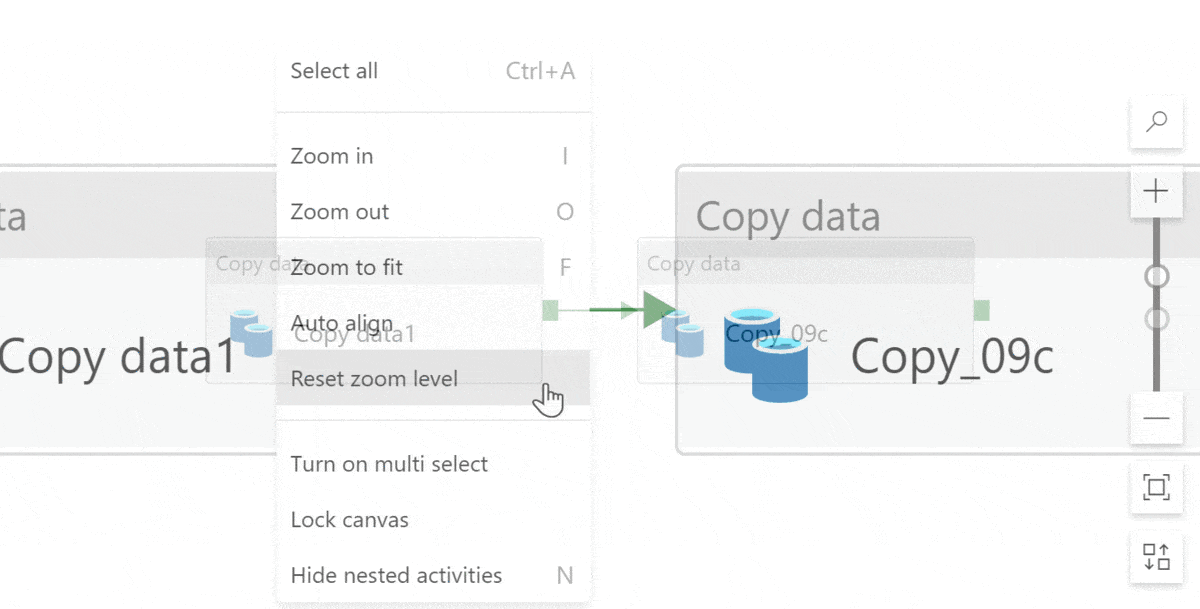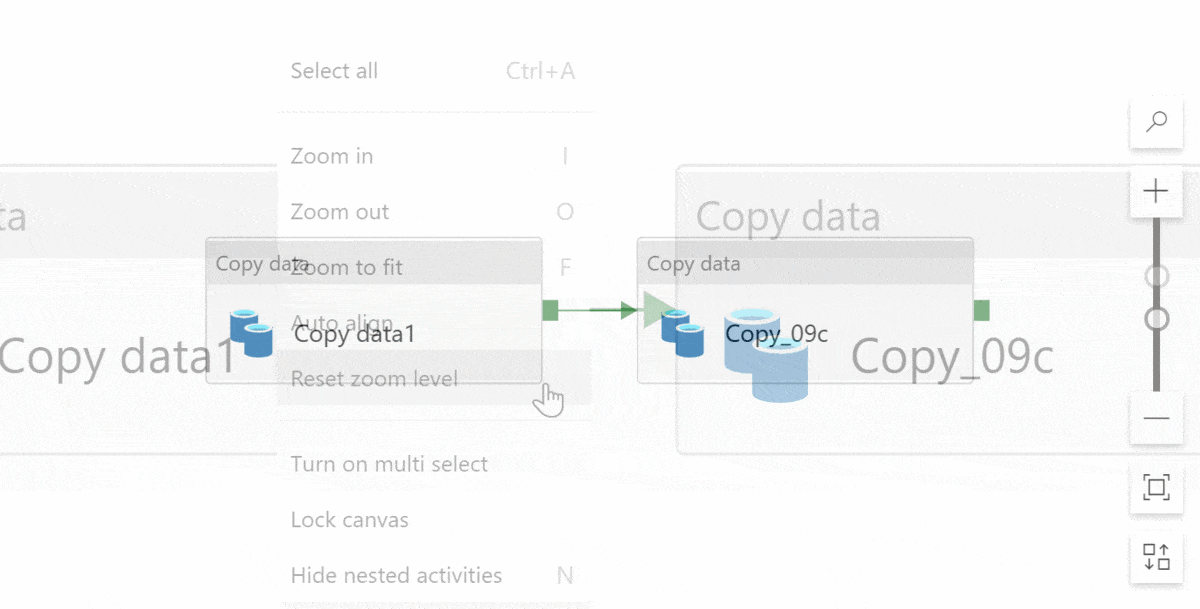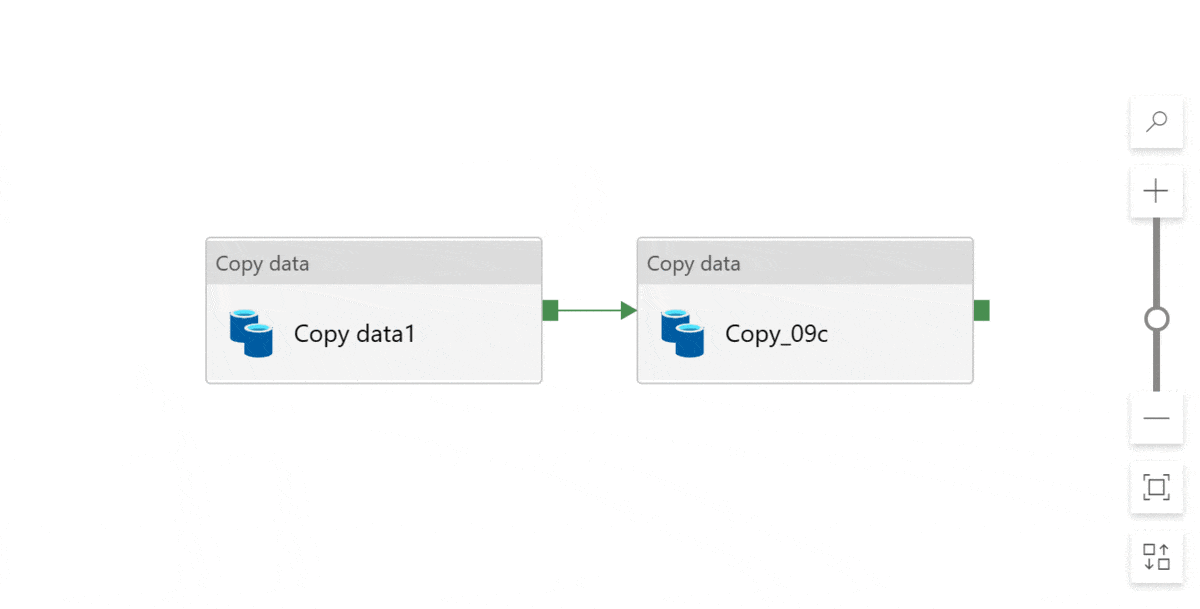
And! If you accidentally scroll or drag too much and all the activities disappear off the design canvas… (It happens more often than I want to admit…) Click zoom to fit and then reset zoom level. Tadaaa! This centers the pipeline on your screen. It’s a handy trick 🤓
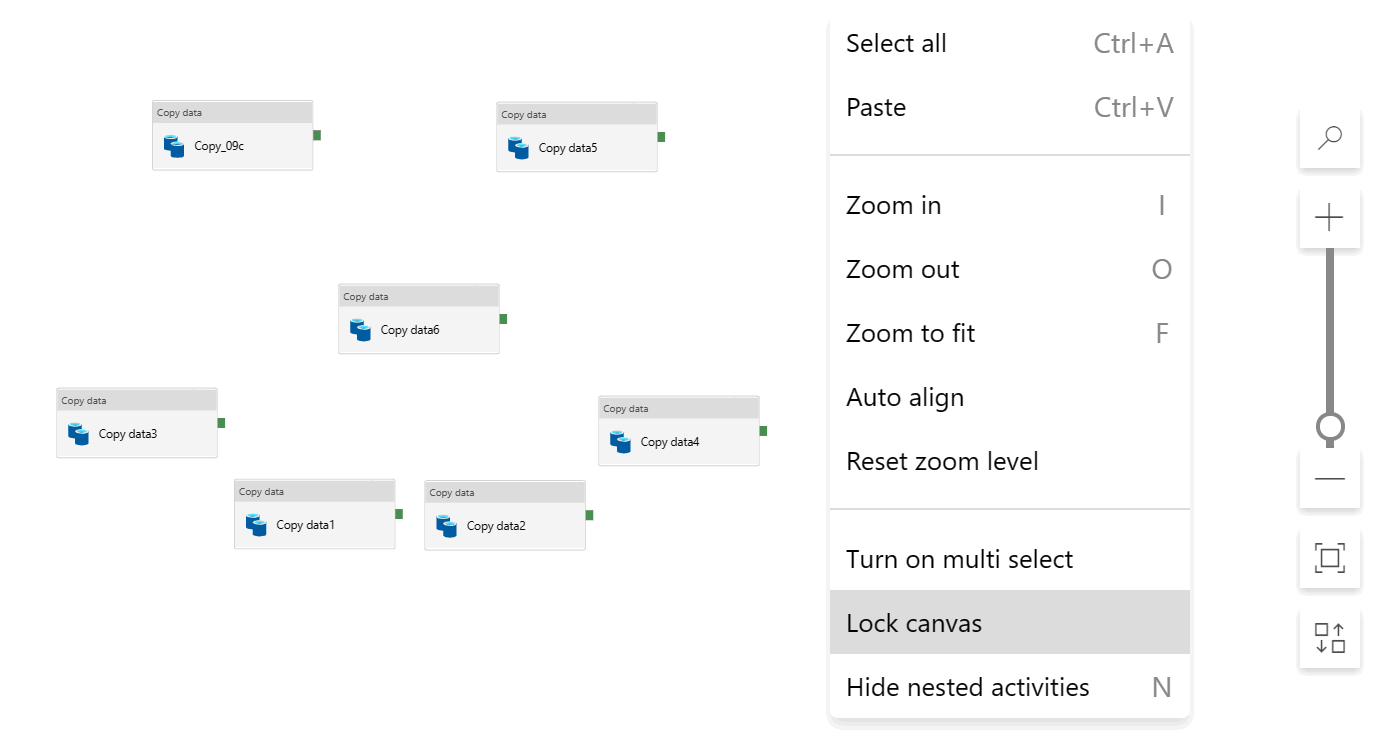
Now, if you prefer to align your activities in a specific way, you can absolutely get creative and move them around as you like. Once you have finished your artwork, you can click Lock canvas so you don’t accidentally move anything. Just remember to not click auto align afterwards:
How do I rename a pipeline or change its description?
To rename a pipeline, you can right-click on the pipeline or click on the three-dot (…) Actions menu, then click Rename. You can also open the General Properties by clicking the properties button in the top right corner:
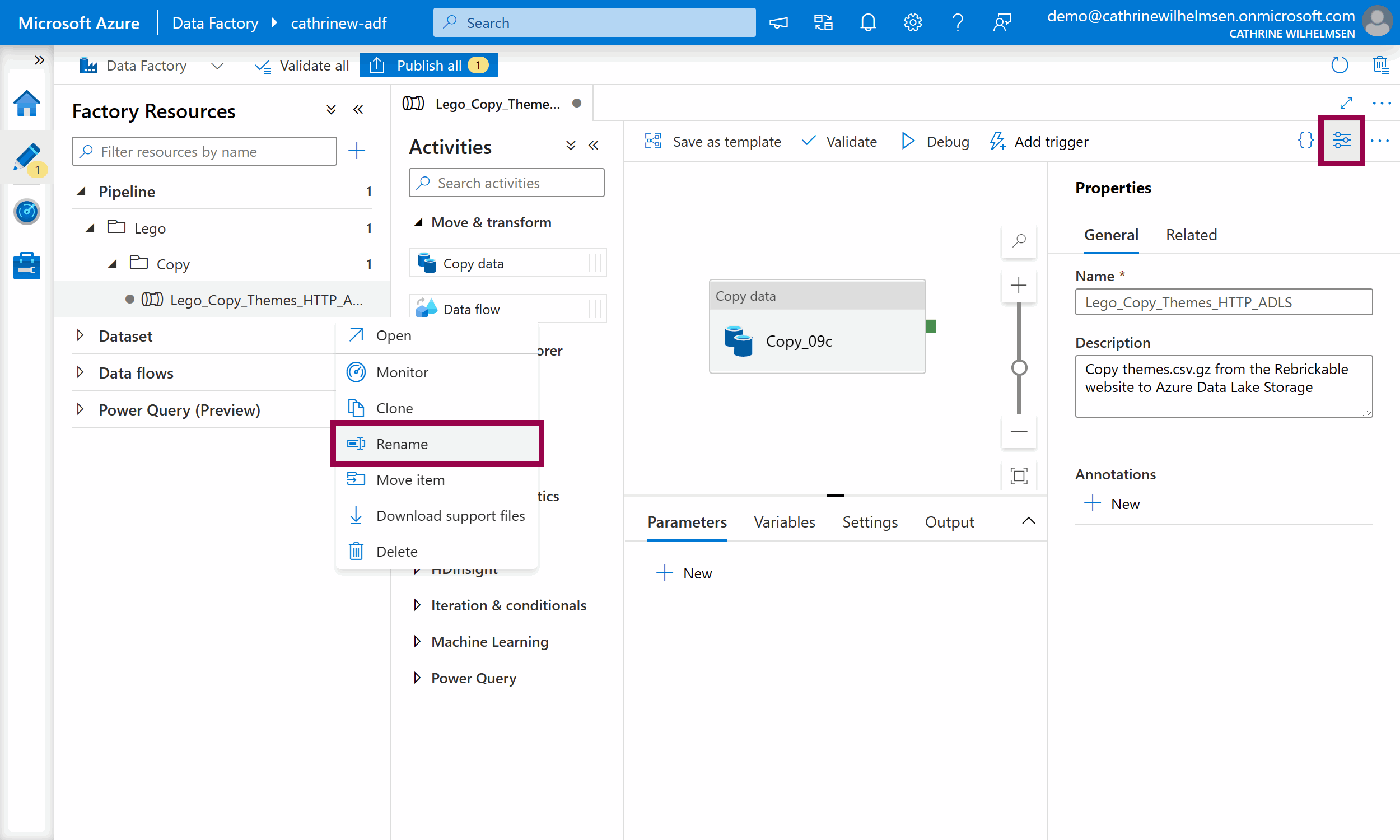
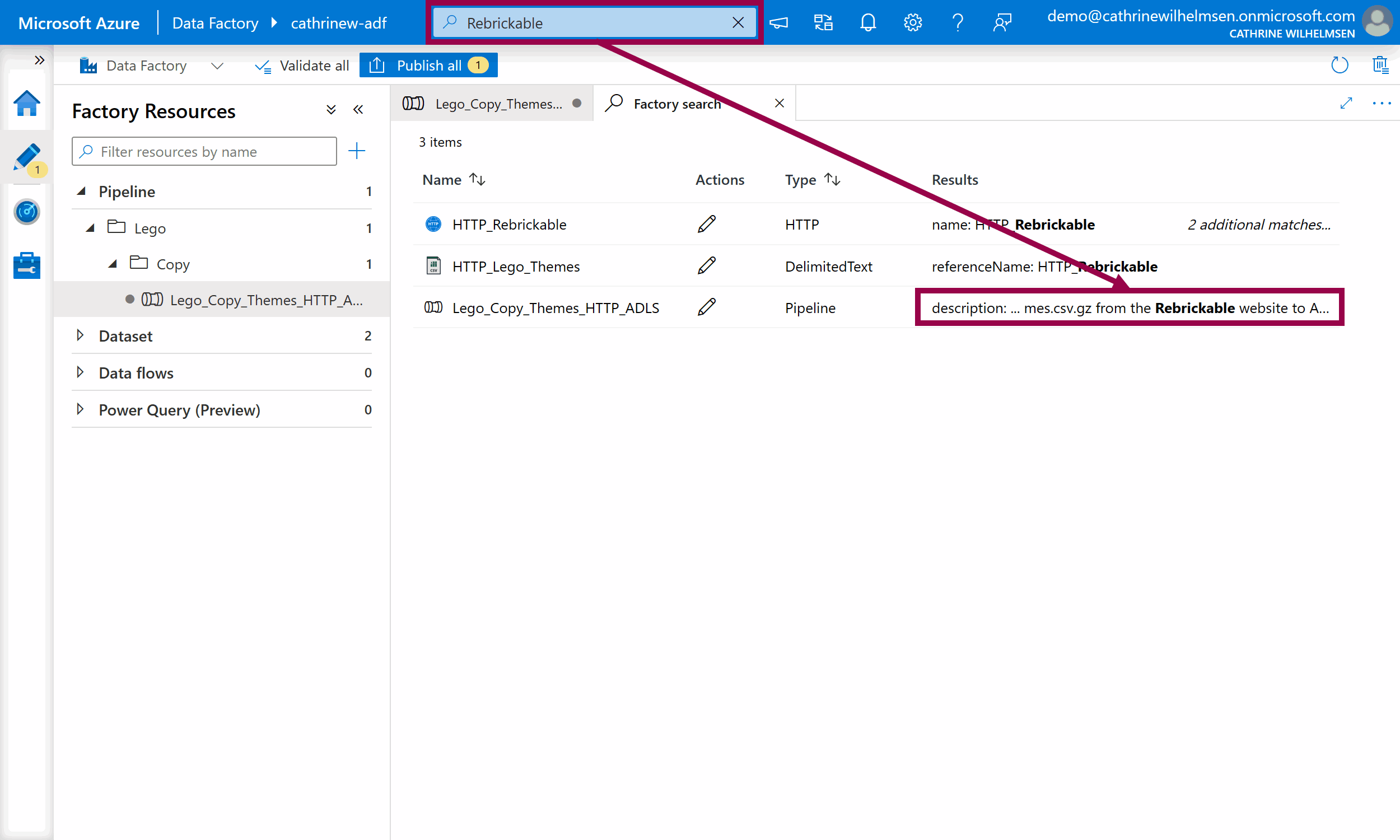
You always have to specify the pipeline name. I also recommend adding good descriptions. You can even search for pipelines based on their descriptions!
You can also add annotations, or tags, to your pipelines. We’ll cover that in a later post.
Do I have to use the graphical user interface?
Nope! 🤓
If you want to, you can work with everything in Azure Data Factory by writing JSON code. Click on Code in the top right corner:
This will show you the pipeline’s JSON code:
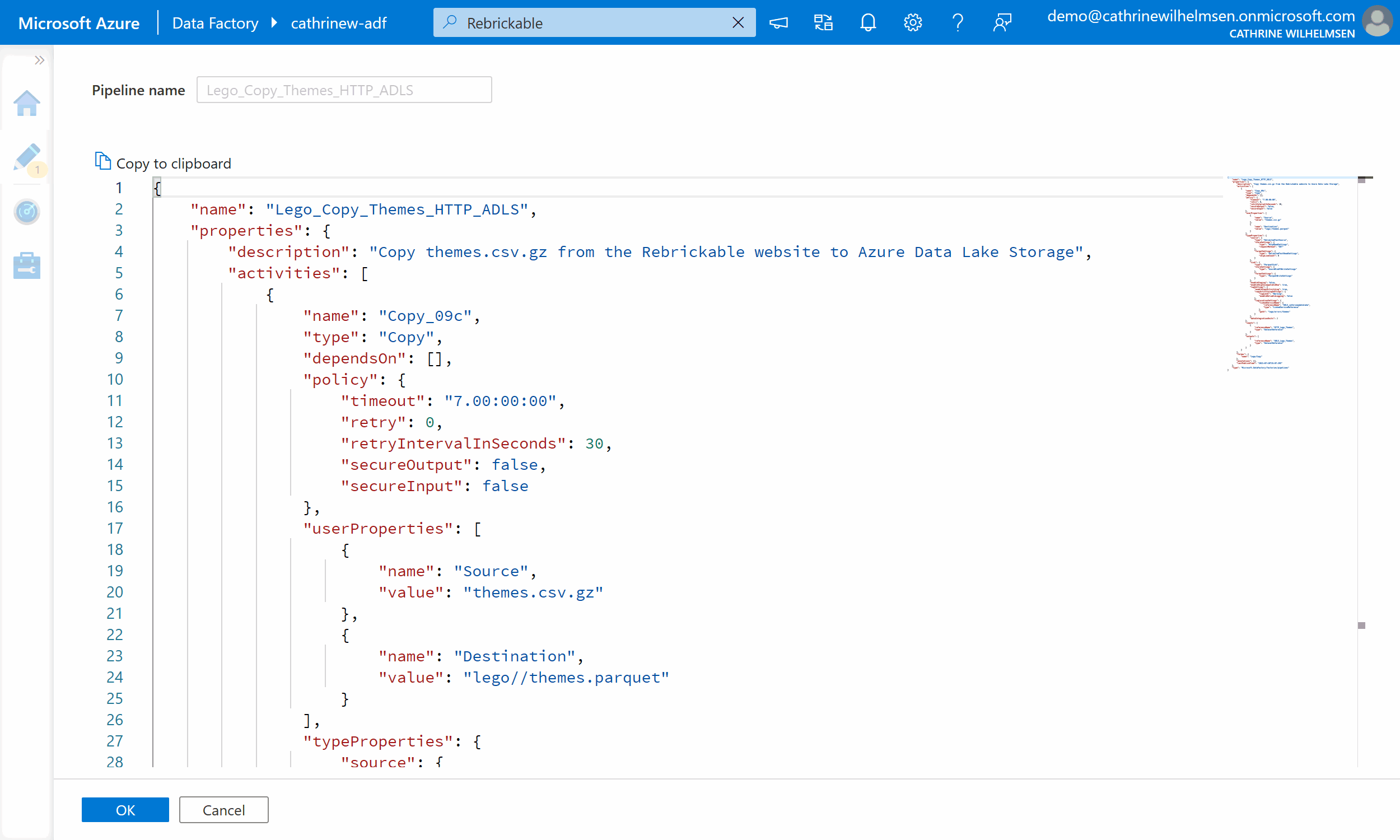
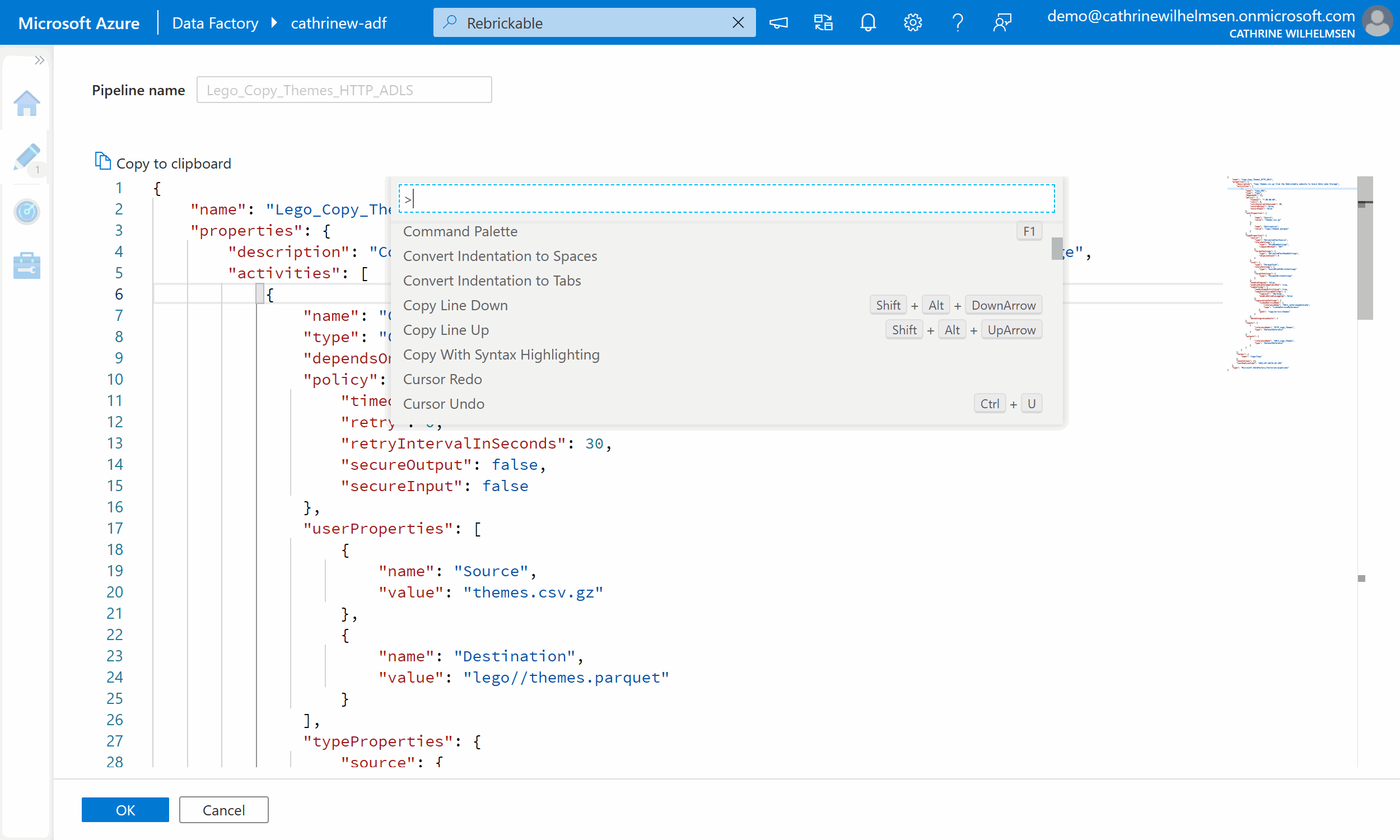
I mostly use the graphical user interface when creating pipelines. However, when I want to rename something in multiple activities, I often find it easier to edit the JSON code. You can use Ctrl+F to find text and Ctrl+H to replace text. And! While this code view looks fairly simple, there is a full code editor behind the scenes. Whaaat! 🤯 You can discover this magic by right-clicking in the editor and choosing Command Palette, or by pressing F1:

There are a lot of hidden goodies in the command palette. Some are useful, some might be more for the curious. Try it out!
How do I check to see if my pipeline is valid?
If you are building more complex pipelines, I recommend validating them once in a while. It’s really annoying building something that you think is awesome, just to be told “sorry, that’s not supported” 😣 So! Click the Validate buttons once in a while:
It will tell you what isn’t working, and you can click each error message to go to where you need to fix it:
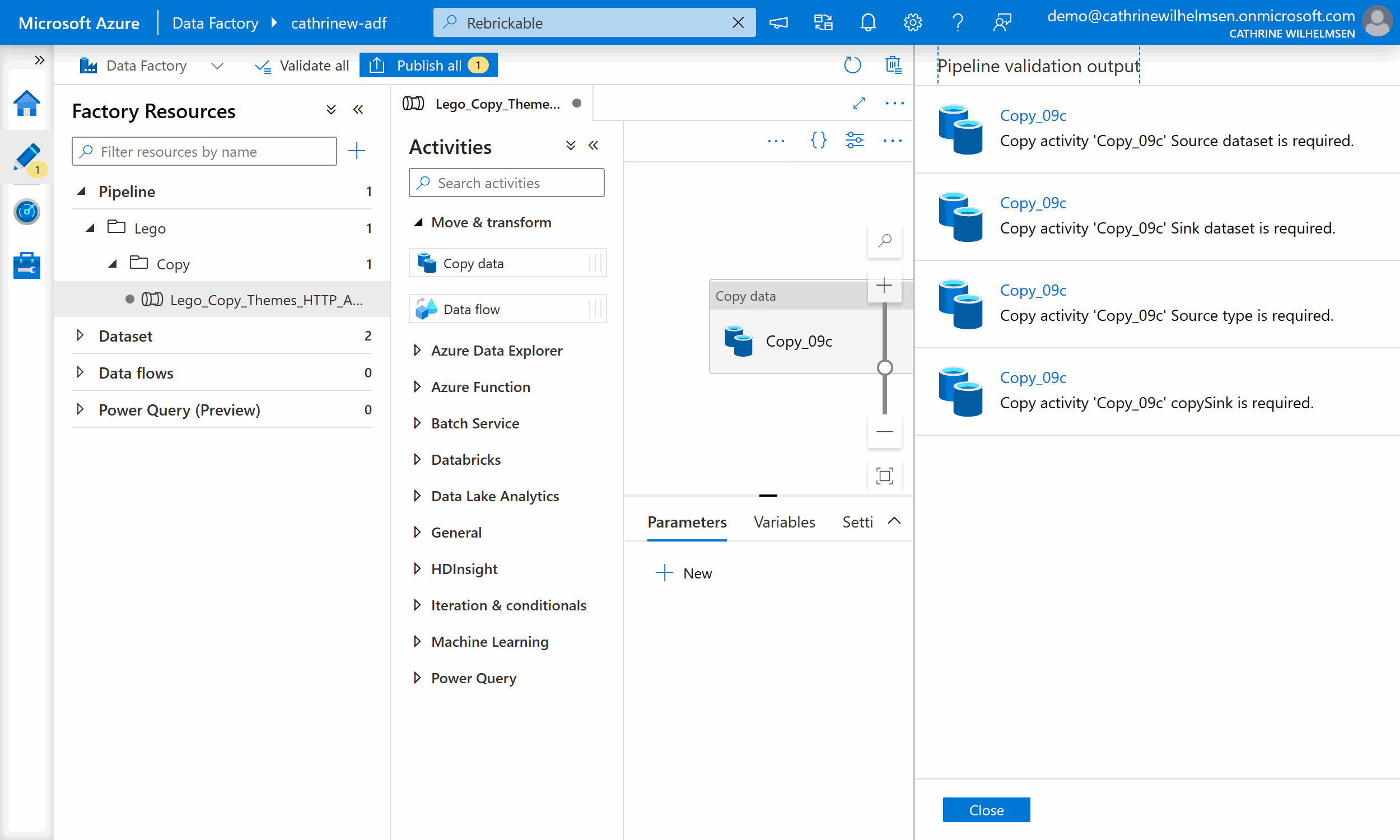
Hopefully, most of the time you will see this friendly checkmark:
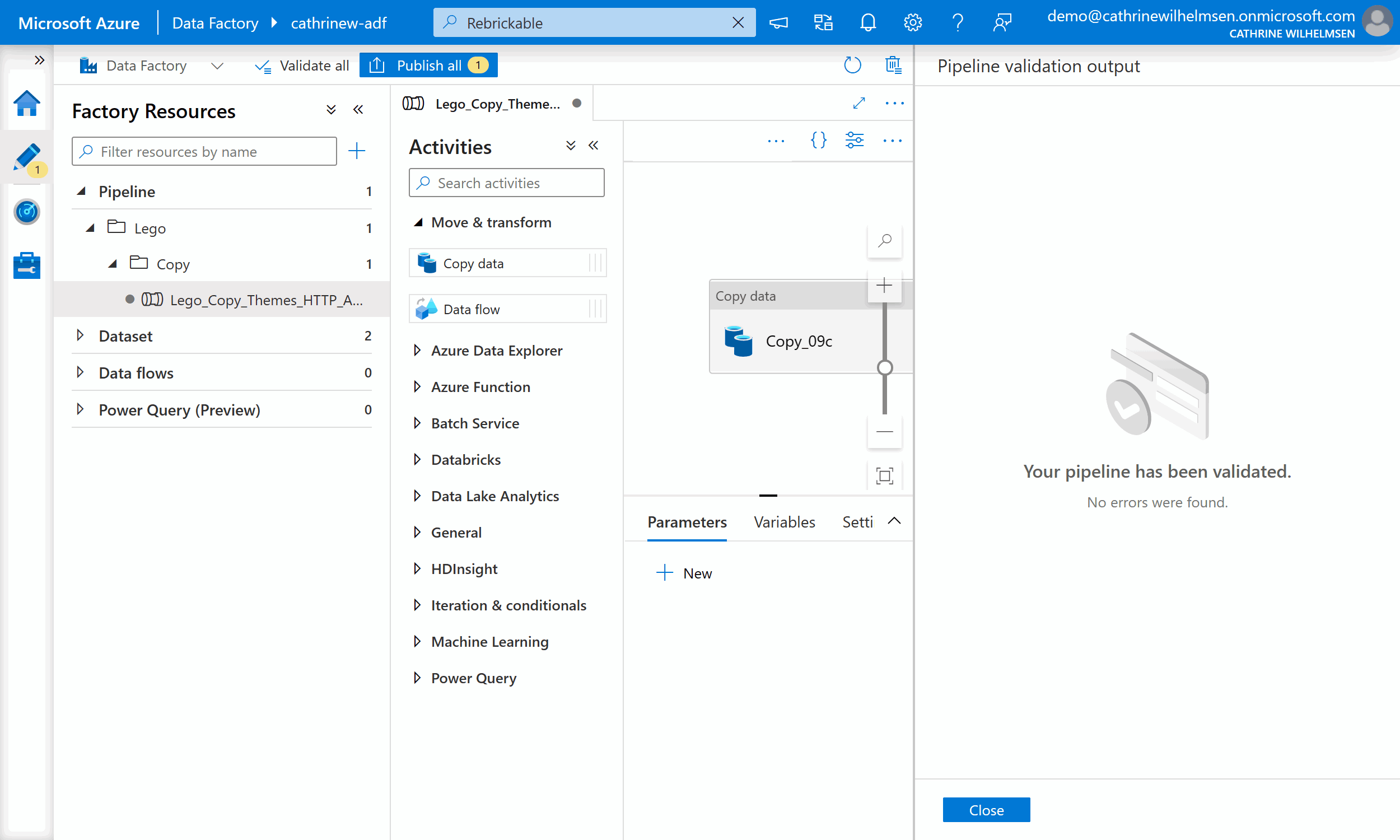
Now, here’s the gotcha. It only checks what it can check inside Azure Data Factory. It doesn’t go to external sources and validate whether or not the file you are trying to load actually exists, for example.
How do I save my pipeline?
To save your pipeline, you need to make sure it validates first. That’s another reason to validate once in a while. You definitely don’t want to be in the middle of building something complex, realize you didn’t get something quite right, notice it’s the end of your workday, leave your browser running because you can’t save the pipeline, come back the next day, and find that your computer restarted in the middle of the night. Trust me! That’s not fun 🤦🏼♀️
Once your pipeline validates, click Publish all:
Verify the pending changes and then click Publish:
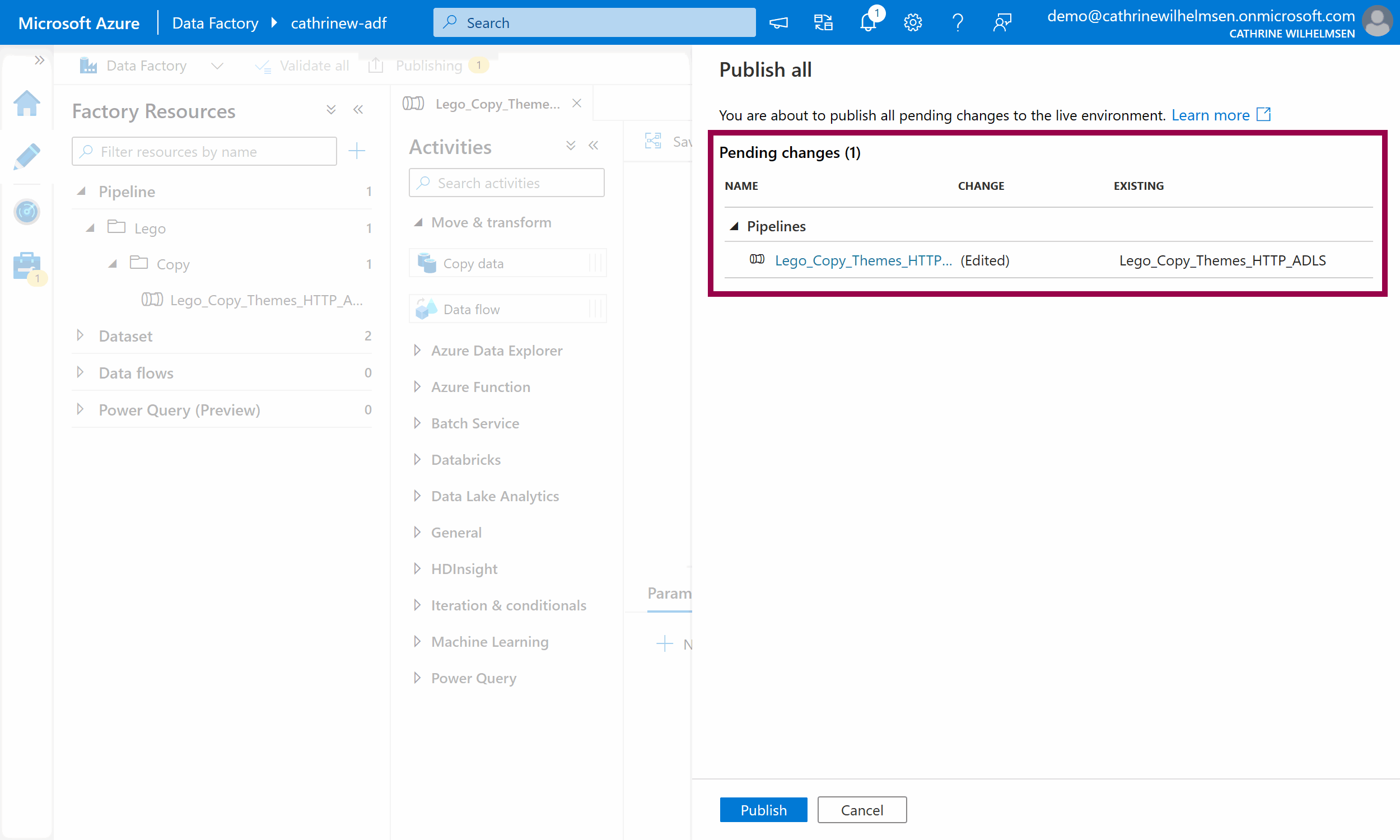
This deploys the change from the user interface to the Azure Data Factory service:

(Now you can leave work without worrying! 😅)
How do I discard my changes?
If you have accidentally made changes while browsing, or you don’t want to keep your changes, click Discard All in the top right corner:
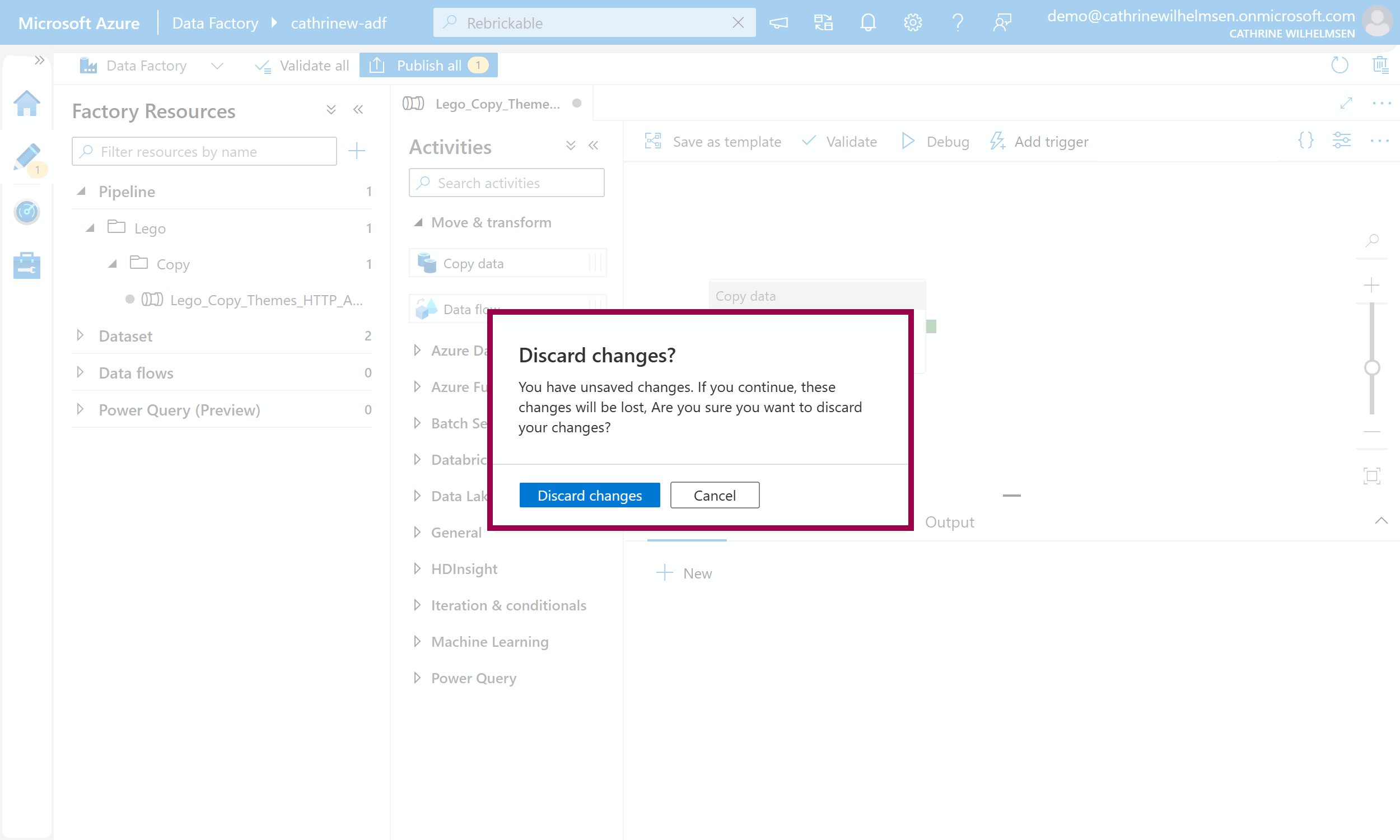
Confirm that you want to discard all the changes and go back to how your Azure Data Factory looked the last time you published:
Summary
In this post, we went through Azure Data Factory pipelines in more detail. We looked at how to create and organize them, how to navigate the design canvas, how to edit the JSON code behind the scenes, and how to publish our changes.
But…
Does the “Copy_09c” activity in the screenshots above bother you just as much as me? You have no idea how difficult it was to screenshot all the things, leaving that as is 😂 I did it for a reason, I promise! We originally built this pipeline using the Copy Data Wizard, which gives activities default names using a random suffix.
In the next post, we’re going to fix this. Let’s dig into the copy data activity!
About the Author
 Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓
Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓