Overview of Azure Data Factory Components

In the previous post, we looked at the Azure Data Factory user interface and the four main Azure Data Factory pages. In this post, we will go through the Author page in more detail and look at a few things on the Monitoring page. Let’s look at the different Azure Data Factory components!
Azure Data Factory Components on the Author Page
On the left side of the Author page, you will see your factory resources. In this example, we have already created one pipeline, two datasets, one data flow, and one power query:
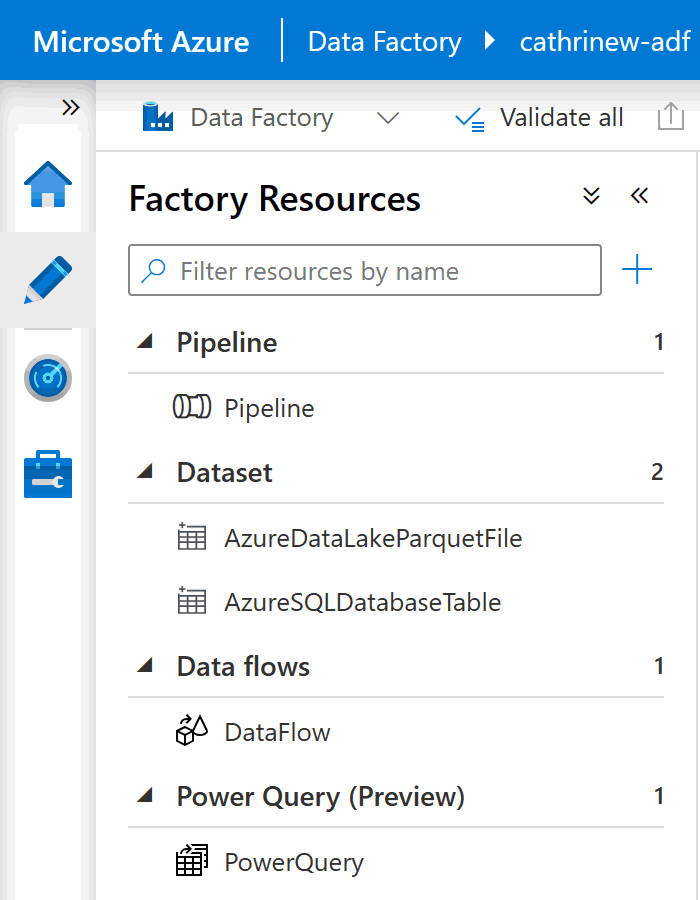
Let’s go through each of these Azure Data Factory components and explain what they are and what they do.
Pipelines

Pipelines are the things you execute or run in Azure Data Factory, similar to packages in SQL Server Integration Services (SSIS). This is where you define your workflow: what you want to do and in which order. For example, a pipeline can first copy and then transform data.
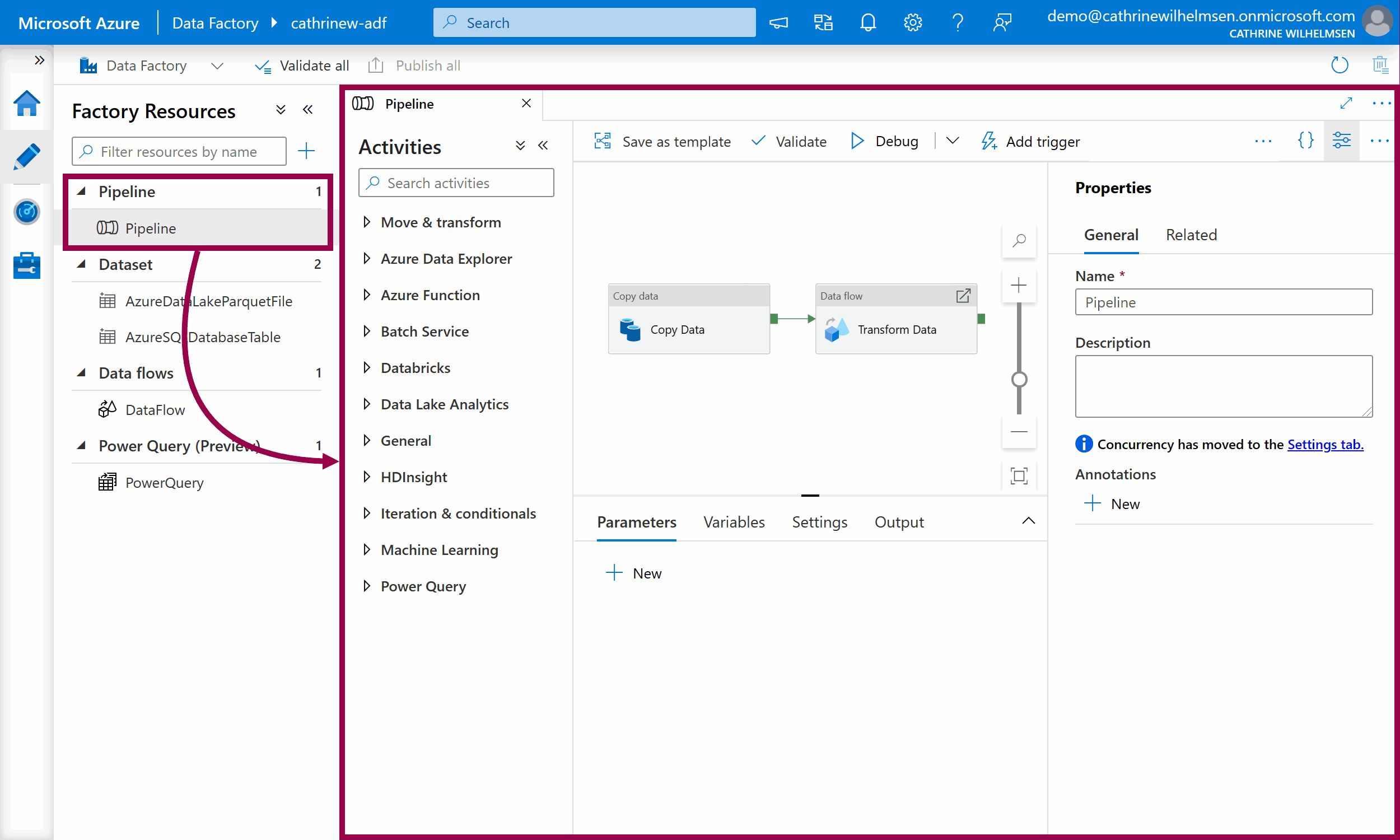
When you open a pipeline, you will see the pipeline authoring interface. On the left side, you will see a list of all the activities you can add to the pipeline. On the right side, you will see the design canvas. You can click on parameters, variables, settings, and output close to the bottom to expand those panes, or the properties button in the top right corner to view the pipeline properties and related pipelines.
Activities

Activities are the individual steps inside a pipeline, where each activity performs a single task. You can chain activities or run them in parallel. Activities can either control the flow inside a pipeline, move or transform data, or perform external tasks using services outside of Azure Data Factory.
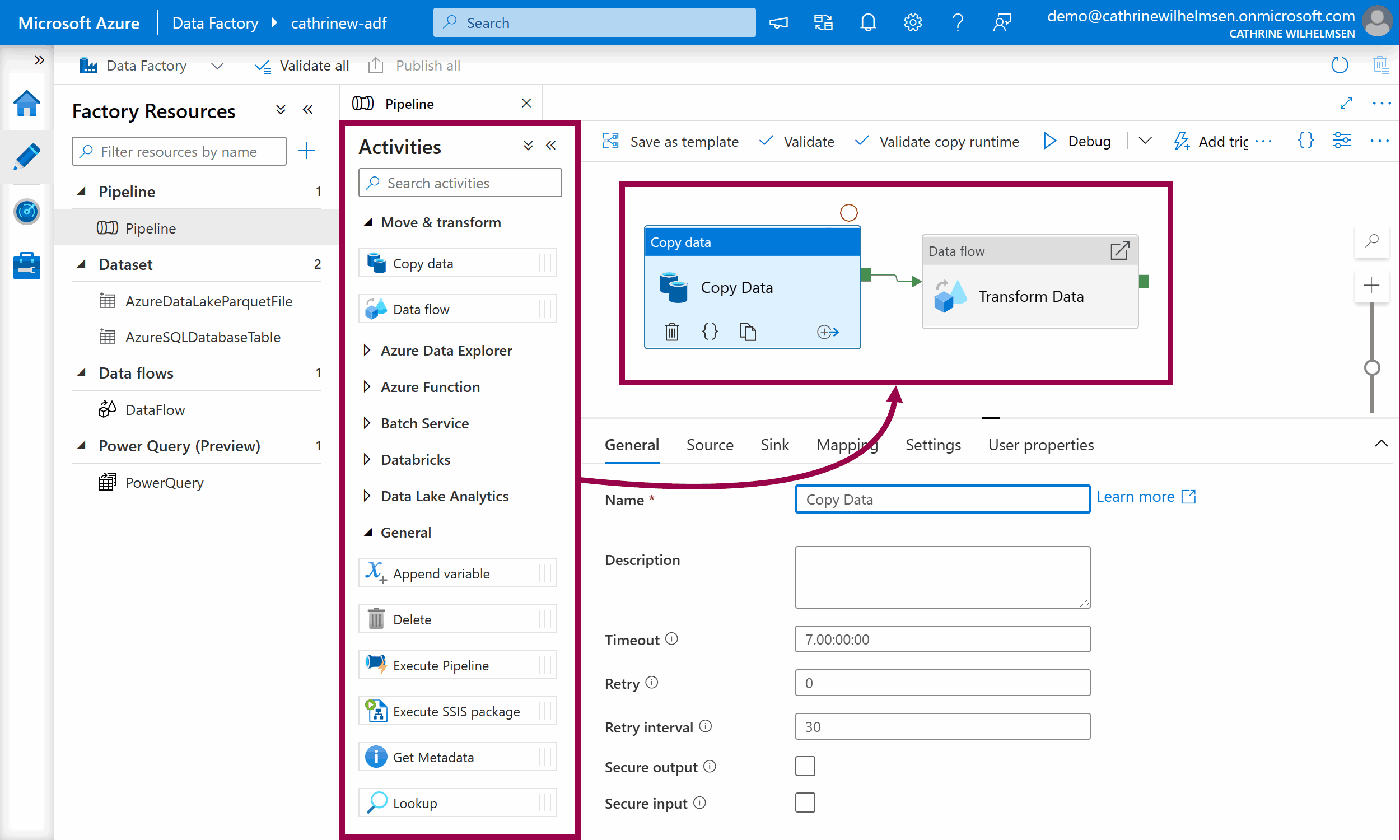
You add an activity to a pipeline by dragging it onto the design canvas. When you click on an activity, it will be highlighted, and you will see the activity properties. These properties will be different for each type of activity.
Data Flows

Data Flows are a special type of activity for creating data transformations. You can transform data in multiple steps using a visual editor, without having to write any other code than data expressions.
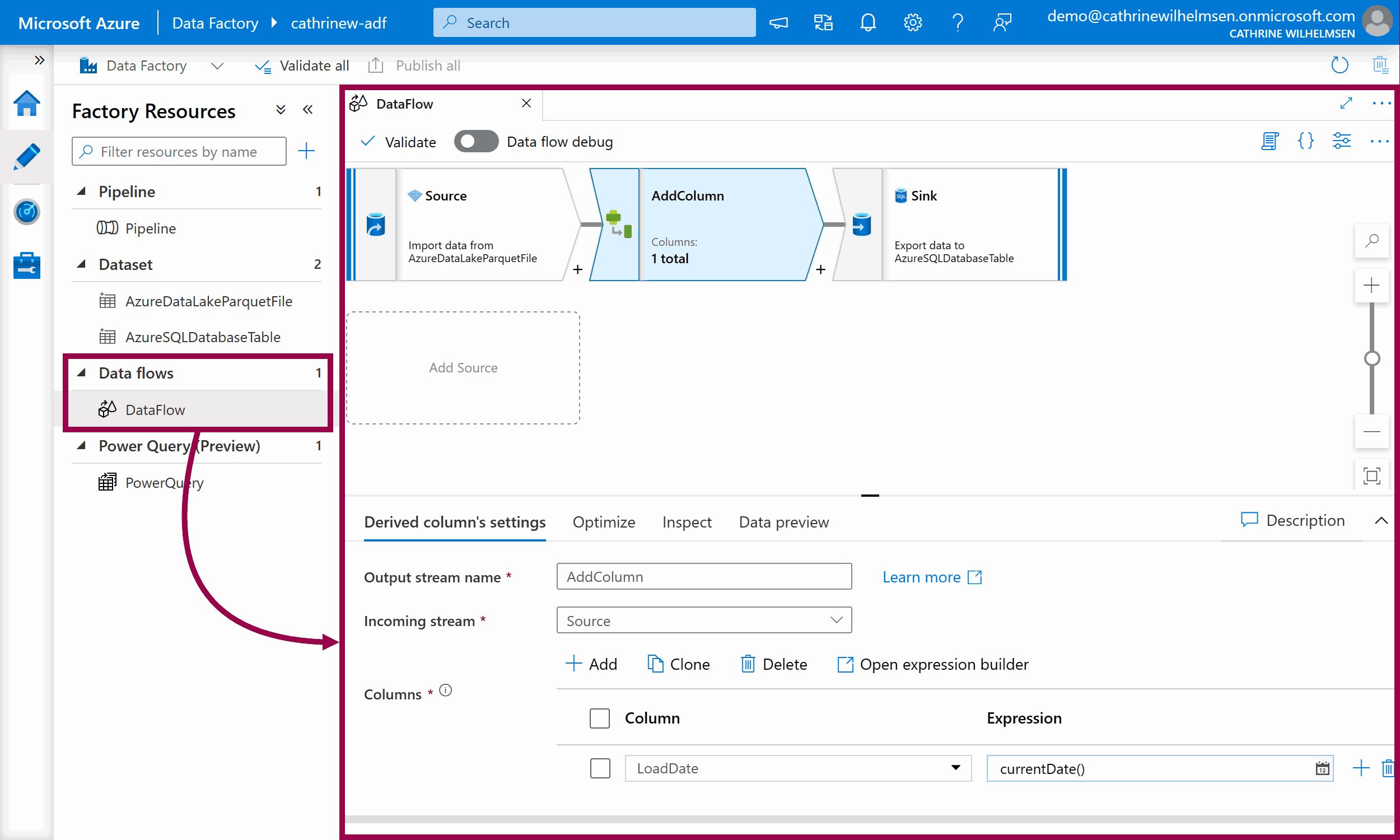
When you open a data flow, you will see the data flow authoring interface. The top part is the visual editor where you add data transformations. When you click on a data transformation, it will be highlighted, and you will see the data transformation settings in the bottom part. These settings will be different for each type of data transformation.
Power Queries

Power Queries are a different type of activity for creating visual data transformations. If you have used Power BI, you might recognize this interface 🤓 (These were rebranded from “wrangling data flows” to “power queries” in 2021, so you may see me use both terms!)
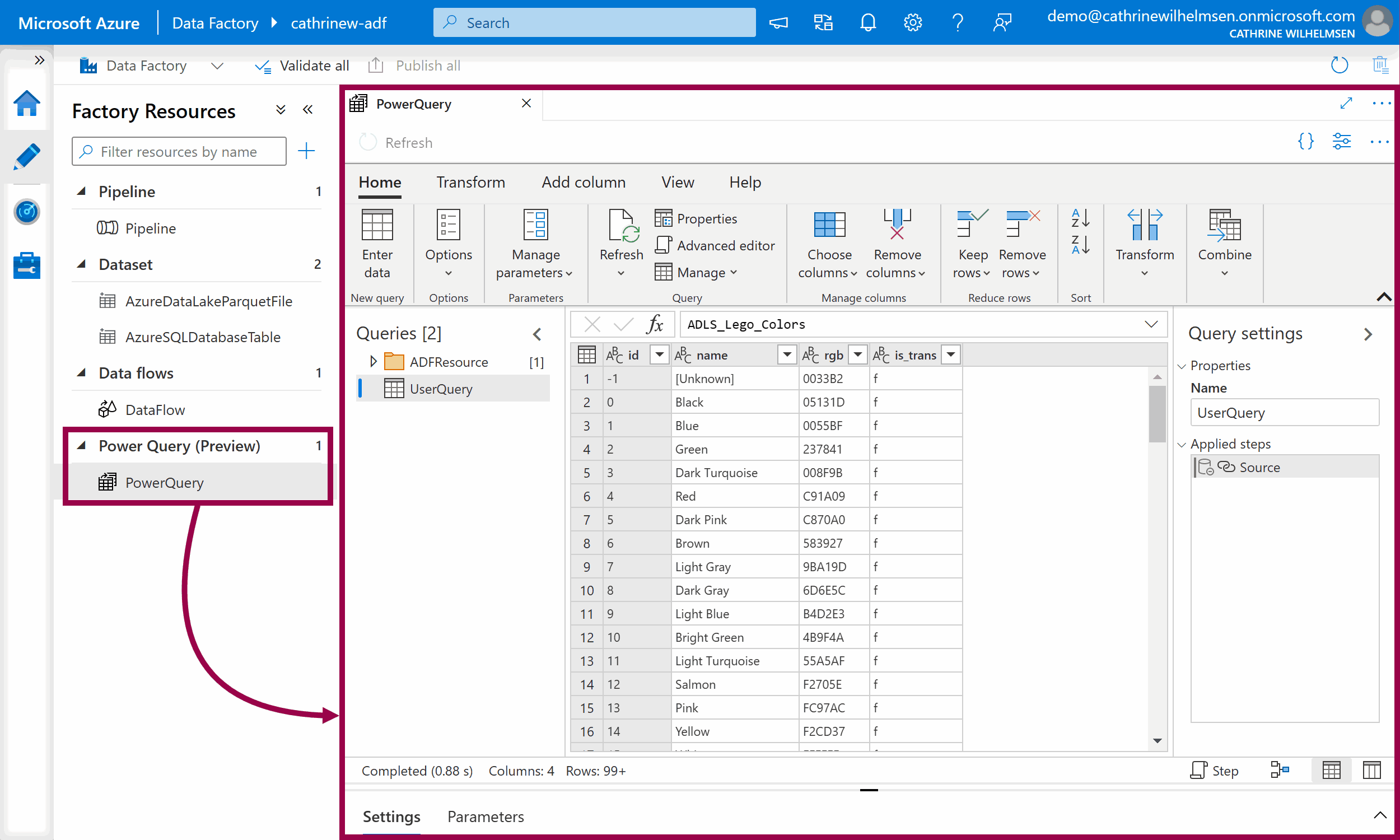
Datasets

If you are copying or transforming data, you need to specify the format and location of the input and output data. Datasets are like named views that represent a database, a database table, a folder, or a single file.
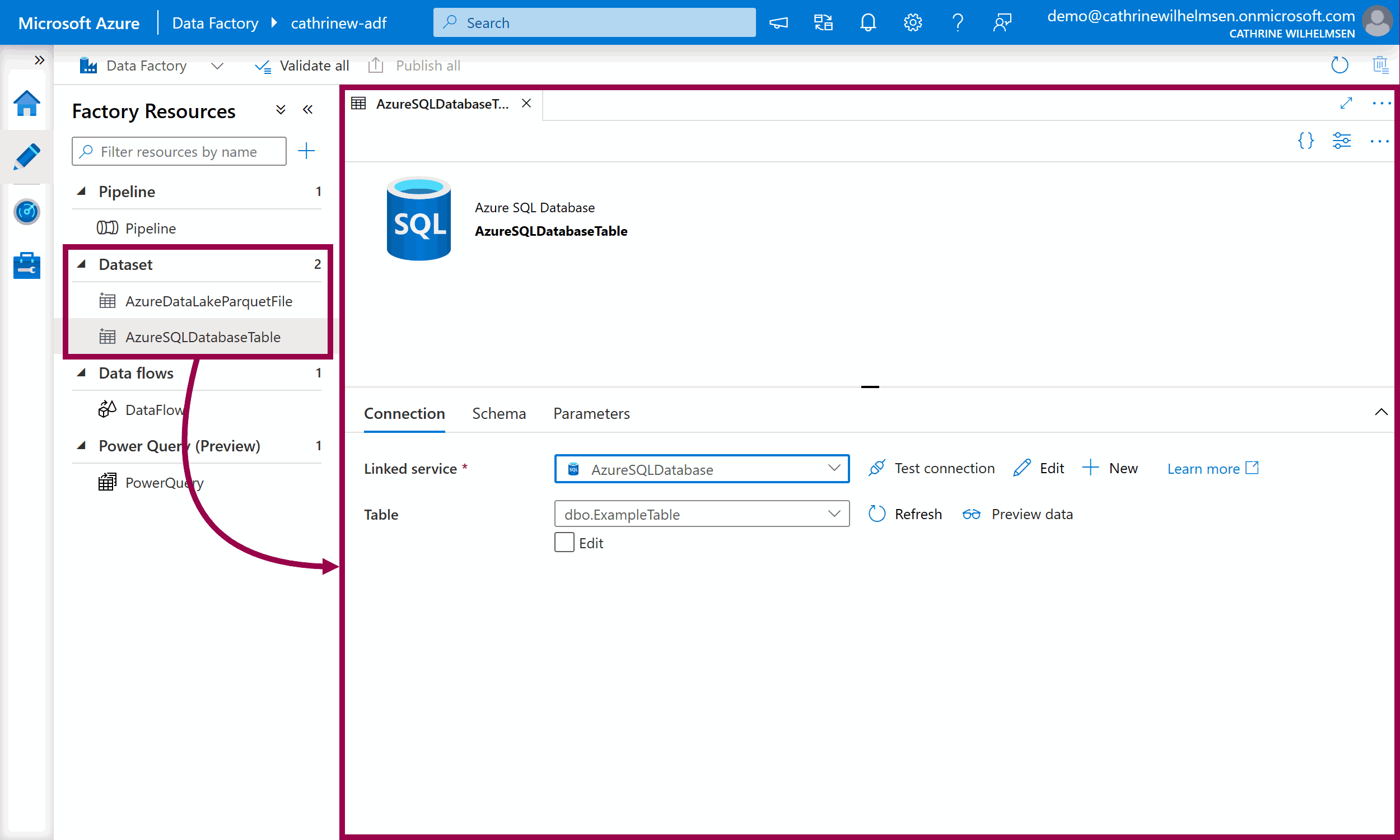
When you create a dataset, you need to specify how to connect to that dataset. You do that using a linked service, which takes us to the next page!
Azure Data Factory Components on the Management Page
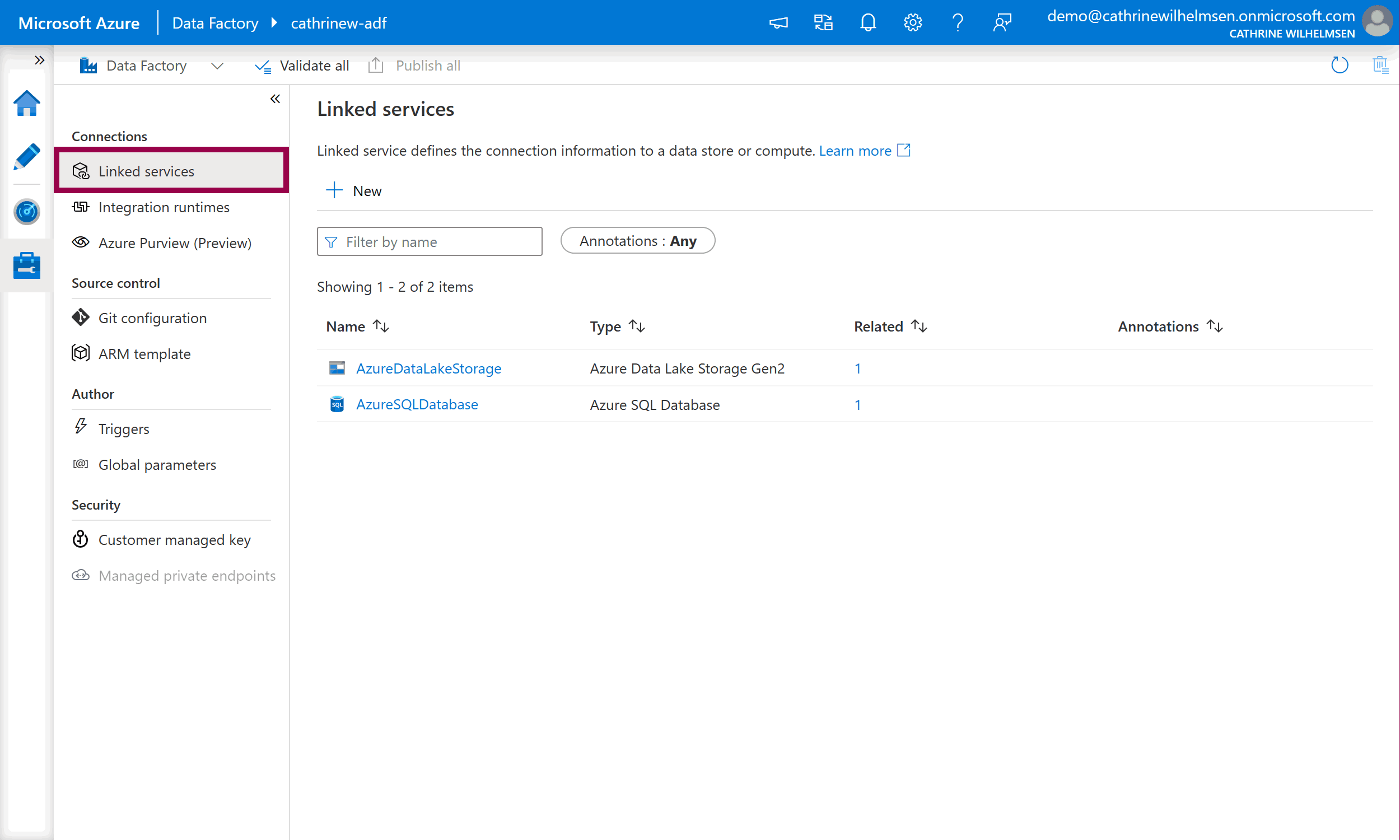
On the left side of the Management page, you will see components and services you can create and configure. We will focus on two of the core components in this post: linked services and triggers.
Linked Services

Linked Services are like connection strings. They define the connection information for data sources and services, as well as how to authenticate to them.
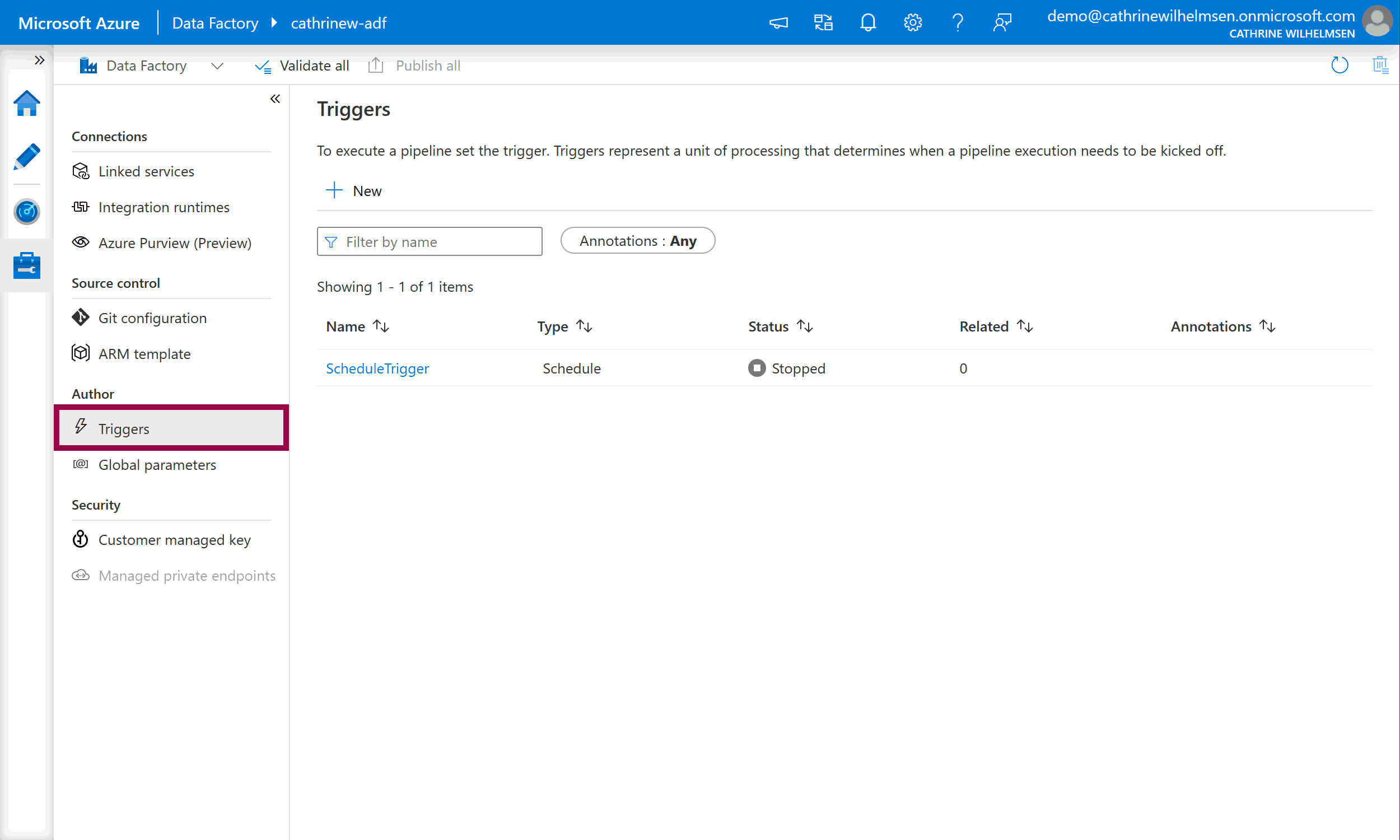
Triggers

Triggers determine when to execute a pipeline. You can execute a pipeline on a wall-clock schedule, in a periodic interval, or when an event happens.
Summary
In this post, we went through the Author and Manage pages in more detail and looked at the different Azure Data Factory components. I like to visualize these in a slightly different way to show how they all work together:
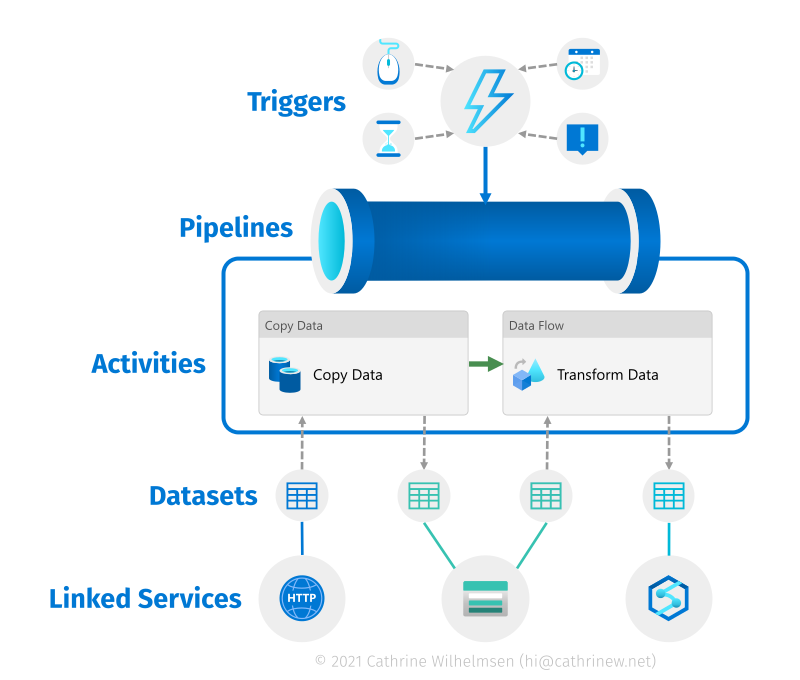
You create pipelines to execute one or more activities. If an activity moves or transforms data, you define the input and output format in datasets. Then, you connect to the data sources or services through linked services. After you have created a pipeline, you can add triggers to automatically execute it at specific times or based on events.
Alrighty! Enough theory. Are you ready to make things happen? I am! Let’s copy some data using the Copy Data Tool.
About the Author
 Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓
Cathrine Wilhelmsen is a Microsoft Data Platform MVP, international speaker, author, blogger, organizer, and chronic volunteer. She loves data and coding, as well as teaching and sharing knowledge - oh, and sci-fi, gaming, coffee and chocolate 🤓